广告行业中那些趣事系列1:广告统一兴趣建模流程
Posted wilson0068
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了广告行业中那些趣事系列1:广告统一兴趣建模流程相关的知识,希望对你有一定的参考价值。

摘要:这是广告系列的第一篇。广告的核心是服务广告主,为广告主圈定对应的人群从而达到好的广告转化效果。而在其中起到桥梁作用的就是标签。广告主会根据自身的性质选定一类或几类有明显特点的人群,这里用标签表示。而我们要做的就是给用户打上标签,然后提供给广告主使用。广告主选择标签,而标签后面则代表人群。本文基于实战项目介绍如何为广告主圈定人群以及如何刻画用户对标签的兴趣度得分。
本系列文章主要结合实际项目围绕广告行业出发,涉及统一兴趣建模、NLP文本理解、图计算等等内容,会持续更新。对相关内容感兴趣的小伙伴可以关注,互相探讨学习。
文章目录
- 更通俗的理解为广告主圈合适的人群
- 构建广告主和用户之间的联系
- 如何刻画用户对标签的兴趣度
01 更通俗的理解为广告主圈合适的人群
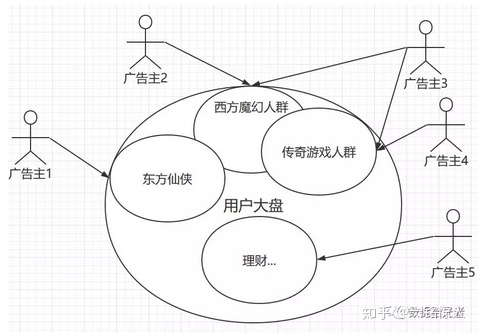
图 1 为广告主圈人群
广告主是干什么的?通俗的理解有点像甲方。广告主说我现在想投入1W块提升下自身的影响力,这里的提升影响力可以是增加点击人数、下载人数、注册人数等等。
有甲方那肯定就有乙方。乙方就是我们移动端厂商。甲方有钱,而我们乙方则可以说是有展示广告的资源。过去广告行业可能是这样的,有个广告主想打广告,看到有栋大楼有个很显眼的位置空着,然后广告主就找到大楼的拥有者说,我出1W块,想在你这个空着的位置打个广告,然后大楼的拥有者收了钱,在上面贴了广告。

随着移动互联网时代的到来,大家花在手机上的时间越来越多。而对于移动厂商来说,卖出的这X亿部手机都可以是移动的广告展示位。区别在于什么?以前的广告就贴在那栋楼上,来来往往的人都能看到。而现在的广告是”千人千面”。同一时刻小A的手机上展示的是传奇游戏的广告,而小B的手机上可能展示的是东方仙侠的广告。对应到图1中移动厂商就提供了中间那个展示广告的大盘子X亿部手机终端。
如何做到给不同的人展示不同的广告呢?这就是我们标签团队要做的事情了。我们需要构建广告主和手机用户之间的联系。对应到图1中,我们要将大盘人群根据不同的兴趣爱好给用户打上不同的兴趣标签。
02 构建广告主和用户之间的联系
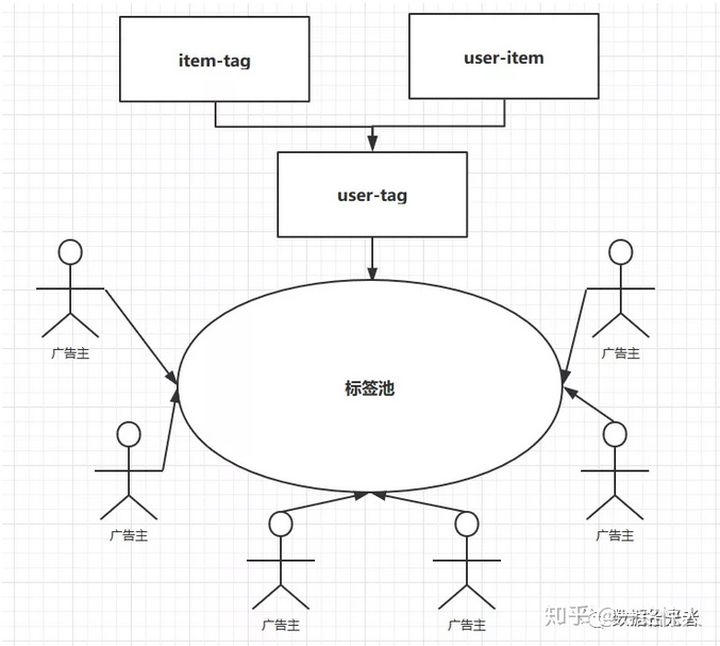 图 2 广告主和用户联系图
图 2 广告主和用户联系图
构建广告主和用户之间的联系主要经过以下五个步骤:
1、构建一个兴趣类目体系
这个兴趣类目体系就是广告主选择人群的一个标准。兴趣类目体系需要覆盖所有广告主需求。现在我们可能存在这样一个简单的兴趣类目体系:

其中传奇游戏标签就代表对传奇这一类游戏有兴趣的人群。
2、建立用户操作行为的关联user-item
用户对手机的所有操作行为都属于item,比如用户登录app、登录网址等等都属于用户操作行为。这里用户操作手机行为用user-item来表示。user-item的数据来源主要是通过手机终端埋点获取。实际项目中数据源可能会用到app、ad、site、query_word、news、微信小程序等等。
3、建立数据源和标签的关联item-tag
其实就是给数据源打上标签。拿app举例,比如成龙大哥代言的一刀传奇我们可以打上传奇游戏标签,而这些标签的制定都是在第一步兴趣类目体系中完成的。
给数据源打标可以通过人工标注或者模型打标。目前项目中app打标采用的是人工打标,主要原因是app数量较少,通过人工打标即可完成app识别。人工标注app也存在很多问题,比如同一个app不同的人由于社会阅历、经验等原因会打上不同的标注。如何更精准的给item打标也是目前项目中一个非常棘手的问题,这个后续会总结一些项目经验和大家一起探讨。
而新闻资讯news和用户搜索词query主要通过模型打标,主要使用的是NLP里大名鼎鼎的BERT模型。这里打个小小的广告,广告系列的第二篇文章会主要讲一下在实际项目中如何使用BERT来给数据源打标,有兴趣的小伙伴可以关注一波。
4、建立用户和标签的关联user-tag
根据user-item和item-tag我们可以构建user-tag的关联。有的小伙伴可能要问怎么做?将上面两种关系分别持久化到hive表中join一下就能拿到user-tag的关联了。通过上面四个步骤我们已经得到人群和标签的关联了。
5、广告主从标签池中选择标签圈定人群
广告主会根据自身的需求选择一个或者多个标签,而这些标签背后都有各自对应的人群。这里人群可能存在重叠,也就是说有人可能既喜欢传奇游戏,还喜欢西方魔幻游戏。
广告主和标签的关系是多对多的关系,一个广告主可以选择一个或者多个标签,而一个标签也可能被一个或者多个广告主选中。
总结下整个流程:首先我们会制定一个兴趣类目体系;然后分别构建user-item和item-tag的关联;接着根据user-item和item-tag进行join即可拿到user-tag的关系。到这里我们已经给用户打上对应的标签了;最后广告主会根据自己的需求去标签池中选择标签,选择标签就是选择人群,最终完成了给广告主圈人群的整个流程。
03 如何刻画用户对标签的兴趣度
通过上述部分我们已经生产出了user-tag的关联。现在有个新的问题,假如现在有个成龙大哥代言的一刀传奇app,现在有100W人登录这个app,按照上述流程我们会给这100W人打上传奇游戏这个标签。有个对传奇游戏标签感兴趣的广告主想打广告,而广告主仅仅需要曝光50W人。那么如何从这100W人群中选择需要曝光的50W人群?
因为广告展示位本身是有价值的,有效曝光(曝光并且有转化)会为我们手机厂商带来广告收益,而无效曝光(曝光无转化效果)则会让我们白白浪费资源,所以我们希望选中的50W人会有更好的曝光转化效果。广告的转化效果越好,广告主就愿意出更多的钱来投广告。
来段题外话,现在广告行业竞争也异常惨烈。一般广告主会同时在多个平台投放广告,并进行对比。如果他在头条或者腾讯都花了1W块,但是腾讯带来的广告效果更好,那广告主为什么不把更多的钱花在腾讯呢?所以如何选出广告转化效果更好的这50W人群,这就需要刻画用户对传奇标签的兴趣度得分,选择得分高的用户进行曝光。
如何刻画用户的兴趣度也是该篇的重点内容。通过统一建模流程我们可以系统批量的生产标签。
统一建模流程整体架构如下:
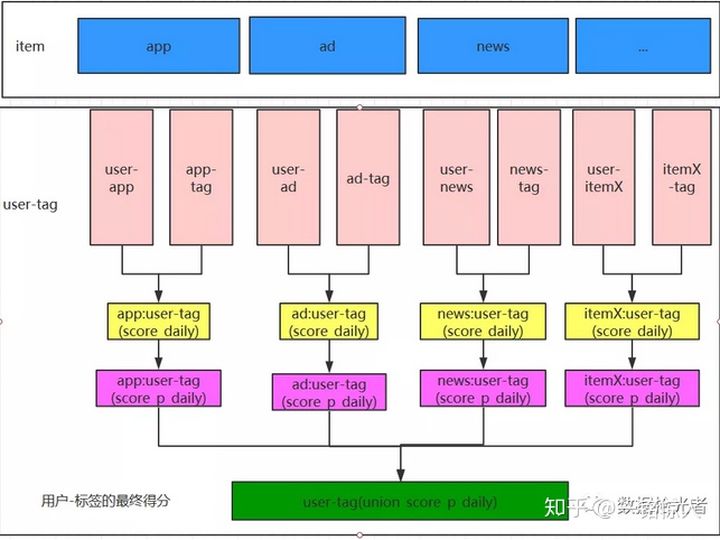 图 3 统一建模整体架构
图 3 统一建模整体架构
1、如何计算当天用户的兴趣度User-tag(score_daily)
User-tag(score_daily)主要是计算日维度用户u在标签t上的得分。
这里拿app举例,其他数据源item计算流程类似。得分score_daily代表用户u在当天d对标签t的兴趣度,计算公式如下:
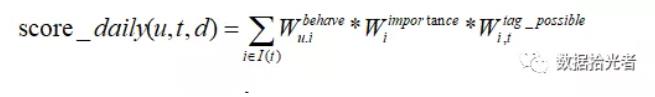
该公式主要由三部分组成:

下面分别讲解上述三部分:
1.1、用户u使用app的程度W_behave
这里用户使用app可以是登录次数、登录时长、付费次数等等。
如果对于app行为只看登录时长,那么用户使用app的程度由用户u使用app的时长在所有使用该app的时长排名来决定。W_behave的计算公式如下:
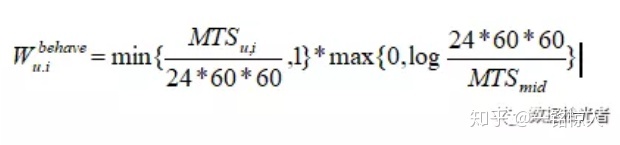
其中MTS_mid表示使用该app的所有用户的时长的中位数。而MTS_u,i表示用户当天使用app的时长(同时修正异常值),单位为秒。TS_u,i表示用户使用app的时长。
MTS_u,i计算公式如下:
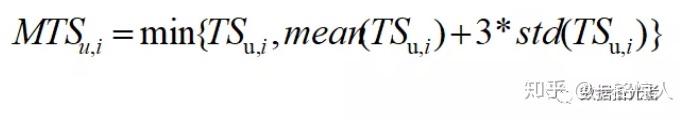
min中后半部分表示使用该app的所有用户的时长均值加上3倍的标准差。
有些小伙伴可能要问W_behave如何修正异常值?W_behave公式中min部分的取值为0或1。当出现异常数据时(最明显的是用户u使用app的时长大于1天)会设置为1,因为按照日维度计算计算情况下用户一整天使用app,但不可能大于1天。公式中max部分取值为大于等于0的值。当出现异常值时比如MTS_mid大于1天的时间时log部分会是负数,则会自动置为0。而正常值时则会显示一个正数。
如果觉得上述流程太复杂,那么W_behave通俗简单的理解是分位数。
比如小A当天使用抖音的时长为5个小时,超过了90%的抖音用户,那么我们可以简单的设置W_behave=0.9。
在实际项目中可能使用的是用户的多种操作行为,比如同时使用登录行为和付费行为,这样涉及到不同行为的权重也是不同的。对于游戏类app我们主要看中用户的付费行为,所以付费行为的权重会大于登录行为的权重。
1.2、App本身的重要程度W_importance
这里使用了类似TFIDF的策略,主要目的是对活跃人数多的app进行打压。通俗的理解是如果一个app比如微信很多人都会登录,那么使用这个app去识别某个标签的能力会大大降低,我们就会认为这个app的重要程度很低。而这类app本身对于兴趣标签挖掘意义不大。反过来,有些人数不是那么多的app它更能识别对该类app是否有兴趣。
W_importance的计算公式如下:
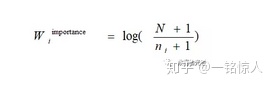
其中N代表大盘总的人数,n_i代表某个app的使用人数。举例来说,极端情况下当一个app所有人都使用了,那么它的重要性为0。
还拿抖音举例,假如N代表当天所有使用app的人数为2亿,n_i表示抖音用户为1亿,那么抖音app的重要度W_importance=log(2/1)=log2
1.3、App所属标签的可能性W_tag_possible
设置这个的原因是针对item理解的时候会同时采用人工标注和机器学习模型识别。针对人工识别的app我们会设置为1,而对于通过机器学习模型打标的app我们会设置为概率值(因为使用机器学习模型时通常会输出一个判定为正例的概率值)。
总结下,通过上述一大推猛如虎的操作我们可以得到在app数据源上用户u当天在标签t上的得分score_daily。通过score_daily我们可以很好的刻画当天哪些用户更有广告价值,而这些用户可能会带来更好的广告转化效果。
这里咱们的核心目标永远是广告转化效果,广告转化效果,广告转化效果!重要的事情说三遍。计算用户u当天在标签t上的得分流程对应图3中黄色的方块部分。
2、如何计算一段时间内的用户兴趣度User-tag(score_p_daily)
通过上述我们可以得到用户u在当天标签t上的得分score_daily。但是仅仅考虑当天用户在标签t上行为就决定是不是给用户打上对应的标签是不合理的。
比如有个用户在过去一个月经常登录传奇游戏,但是昨天因为某些原因并没有登录传奇游戏,所以我们就没有给这个用户打上传奇游戏标签,这显然很不合理。反应用户兴趣标签应该考虑一段时间内的行为而不是某一天,所以用户最终的兴趣得分应该是当天用户u在标签t上的得分和最近一段时间上累计的兴趣得分共同来决定。计算公式如下:
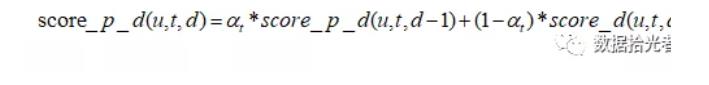
其中score_p_d(u,t,d-1)代表前天用户u在一段时间内(一般设置为3-6个月)在标签t上累计的兴趣得分。
score_d(u,t,d)代表昨天当天用户u在标签t的上的得分,也就是上一部分得到的score_daily。α_t代表衰减系数,该值表示当前用户最终兴趣得分在最近一段时间得分和当天用户u在标签t上的得分的一个权衡。α_t的计算公式如下:
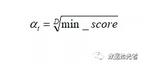
举例来说,如果我们认为用户在90天里没有登录某个标签的app,那么我们认为该用户u在标签t上的得分最终降低为0.0001。当降低到0.0001时我们认为用户对该标签已经没有兴趣。
总结一下,刻画用户u在标签t上最终的兴趣得分不仅要看用户当天对标签t的兴趣得分,还要看最近一段时间内累计的兴趣得分。计算score_p_daily流程对应图3中紫色的部分。
3、多个数据源融合
通过上述部分我们可以得到用户u在app数据源上在标签t上的最终兴趣得分,该兴趣得分可以反映用户在一段时间内对该标签的兴趣程度。
实际项目中我们不仅仅会用到app数据源,还会包括新闻资讯news、网址site等等。所以我们需要将不同的数据源的得分进行融合得到在多种数据源下最终的兴趣得分,计算公式如下:
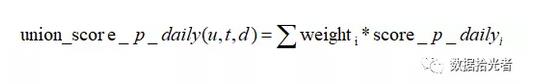
其中weight_i代表数据源i的权重,score_p_daily_i代表用户u在数据源i上累计兴趣得分,将所有数据源上的得分乘以数据源的权重然后累计相加得到最终的兴趣得分。
通过融合多个数据源我们得到了用户在多个数据源下的综合的兴趣得分,我们称为统一兴趣建模流程。
到这里,大功告成。总结一下,通过统一建模流程,我们可以批量生产标签,通过控制底层数据源的标注可以动态的增减标签,更好的满足广告主的需求。
说点轻松的
文章里一直在拿传奇游戏举例子。一个很重要的原因是小时候有幸经历过传奇游戏风靡的时代,还记得那时候想尽一切办法偷偷去网吧上网而被妈妈抓住暴打的样子。那个战法道横行的时代,和公会的小伙伴一起攻打过沙巴克,还有我最喜欢的法师职业。可能是那个年代里大家很难忘记的回忆。也许正是因为这个原因,尽管现在比传奇游戏好玩的游戏有那么多,还是有那么多中年油腻大叔会愿意花很多很多钱去玩传奇游戏。这也是目前我们游戏板块传奇游戏依然是重头角色的原因吧。而我加入标签团队的第一个标签优化任务就是传奇游戏标签。一点感慨,不过是青春罢了。
下一篇会通过使用NLP中BERT模型对资讯news、用户搜索词query进行文本识别,从而给这些数据源进行模型打标。
喜欢本类型文章的小伙伴可以关注我的微信公众号:数据拾光者。有任何干货我会首先发布在微信公众号,还会同步在知乎、头条、简书、csdn等平台。也欢迎小伙伴多交流。如果有问题,可以在微信公众号随时Q我哈。

以上是关于广告行业中那些趣事系列1:广告统一兴趣建模流程的主要内容,如果未能解决你的问题,请参考以下文章
广告行业中那些趣事系列10:推荐系统中不得不说的DSSM双塔模型
广告行业中那些趣事系列10:推荐系统中不得不说的DSSM双塔模型
广告行业中那些趣事系列4:详解从配角到C位出道的Transformer