Python接口自动化之Token详解及应用
Posted vivia
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python接口自动化之Token详解及应用相关的知识,希望对你有一定的参考价值。
在上一篇Python接口自动化测试系列文章:Python接口自动化之cookie、session应用,
介绍了cookie、session原理及在自动化过程中如何利用cookie、session保持会话状态。
以下介绍Token原理及在自动化中的应用。
?
一、Token基本概念及原理
1、Token作用
为了验证用户登录情况以及减轻服务器的压力,减少频繁的查询数据库,使服务器更加健壮。

2、什么是Token
Token是服务端生成的一串字符串,以作客户端进行请求的一个令牌,当第一次登录后,服务器生成一个Token便将此Token返回给客户端,以后客户端只需带上这个Token前来请求数据即可,无需再次带上用户名和密码。
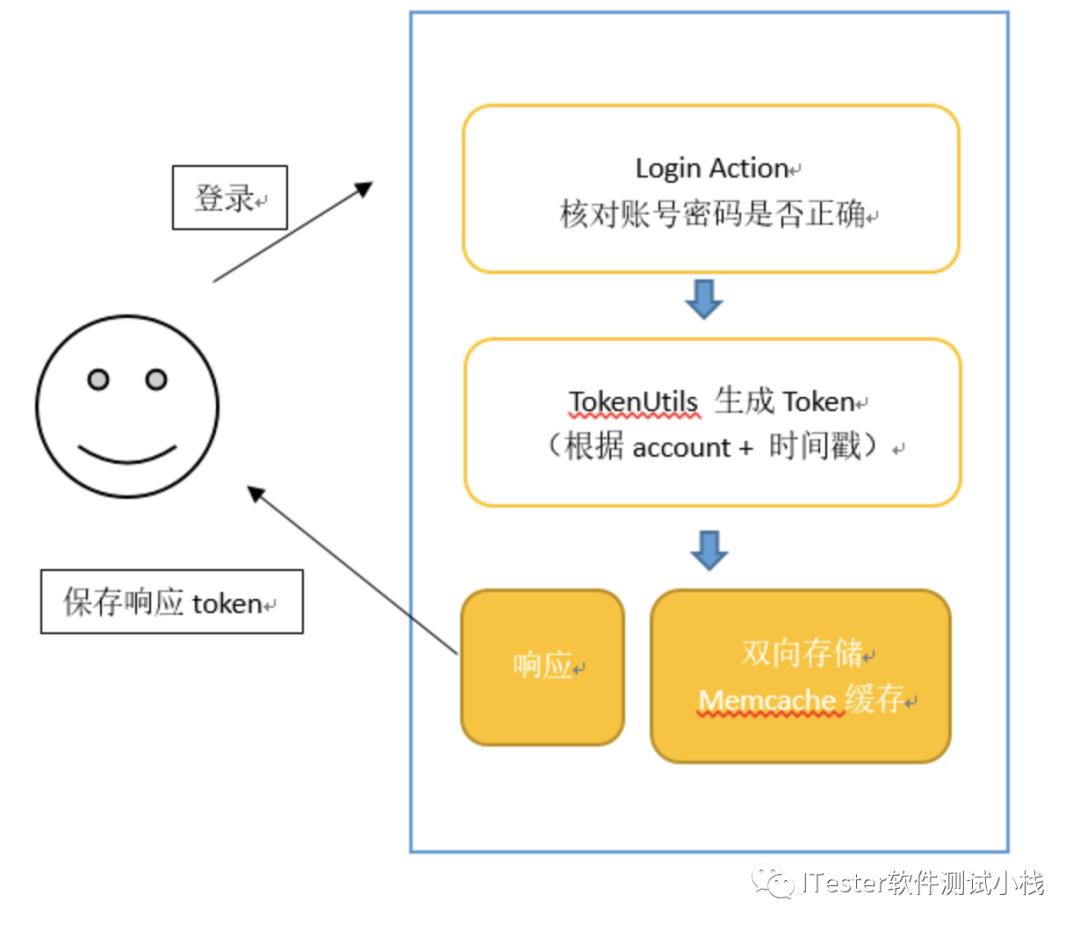
3、Token运行原理

1.当用户首次登录成功之后, 服务器端就会生成一个 token 值,这个值会在服务器保存token值(保存在数据库中),再将这个token值返回给客户端;
2.客户端拿到 token 值之后,进行保存 (保存位置由服务器端设置);
3.以后客户端再次发送网络请求(一般不是登录请求)的时候,就会将这个 token 值附带到参数中发送给服务器;
4.服务器接收到客户端的请求之后,会取出token值与保存在本地(数据库)中的token值进行比较;
5.如果两个 token 值相同, 说明用户登录成功过,当前用户处于登录状态;
6.如果没有这个 token 值, 没有登录成功;
7.如果 token 值不同,说明原来的登录信息已经失效,让用户重新登录;
4、Token认证优点
-
无状态(也称:服务端可扩展行):Token机制在服务端不需要存储session信息,因为Token 自身包含了所有登录用户的信息,只需要在客户端的cookie或本地介质存储状态信息.
-
可重用性:在多个平台和域(domains)上运行,重复使用相同的令牌来验证用户,很容易构建与其他应用程序共享权限的应用程序。
-
安全性:由于我们没有使用 Cookies,我们不必再防御网站的跨站点请求伪造(CSRF)攻击。
5、Token和 Cookie、Session 的选型
对于只需要登录用户并访问存储在站点数据库中的一些信息的中小型网站来说,Session Cookies 通常就能满足。如果有企业级站点,应用程序或附近的站点,并且需要处理大量的请求,尤其是第三方或很多第三方(包括位于不同域的API),则 token显然更适合。
二、Token实战
讲了那么多概念和原理,很多小伙伴可能不知道token长啥样,接下来以接口登录为例。
import requests url = ‘http://127.0.0.1:8000/user/login/‘ payload = { "username":"vivi", "password":"123456" } res = requests.post(url,json=payload) print(res.text)
响应结果如下:
{ "token": "eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjoxLCJ1c2VybmFtZSI6InZpdmkiLCJleHAiOjE1ODY4NDg5NzgsImVtYWlsIjoidml2aUBxcS5jb20ifQ.a2ExtNVjGrY8T1gefcJTnk4JUOx9NVtCk6lMK8o47co", "user_id": 1, "username": "vivi" }
响应结果有返回token,但是token要怎么用呢,不急,我们一步步来。假设现在有个项目列表的接口,在不登录的前提下,不能访问。
import requests url = ‘http://127.0.0.1:8000/projects/‘ pro_res = requests.get(url) print(pro_res.json())
响应结果:提供认证信息
{‘detail‘: ‘身份认证信息未提供。‘}
项目列表接口需要携带token,服务器校验成功后,才能成功返回信息
重点来了,如何从登录接口获取token,项目列表接口又如何携带token?

访问登录接口,并获取token。
import requests url = ‘http://127.0.0.1:8000/user/login/‘ payload = { "username":"vivi", "password":"123456" } login_res = requests.post(url,json=payload) # 从响应结果中获取token值 token = login_res.json()["token"] print("token:", token)
响应结果为:
token: eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjoxLCJ1c2VybmFtZSI6InZpdmkiLCJleHAiOjE1ODY4NTEyMjksImVtYWlsIjoidml2aUBxcS5jb20ifQ.neqVM5MFGuFbKIUOCqW_qXBajhTTQMfmAs2PWTkEMes
那项目列表接口又如何携带token呢,token直接加在请求头,这样就可以了么,当然不是,我们还需要在token前加上前缀,前缀由后端设置,见过最多的前缀是:Bearer,不清楚的参照接口文档。
项目列表携带token访问。
import requests url = ‘http://127.0.0.1:8000/projects/‘ # 拼接最终的token,注意中间有个空格 token = "Bearer" + " " + token headers={ "authorization": token } pro_res = requests.get(url,headers=headers) print(pro_res.json())
响应结果为:
{ "count": 2, "results": [ { "id": 1, "name": "自动化测试平台项目1", "tester": "vivi" }, { "id": 2, "name": "自动化测试平台项目2", "tester": "coco" } ], "total_pages": 1, "current_page_num": 1 }
总结:本文主要介绍token基本概念、运行原理及在自动化中接口如何携带token进行访问。
下一篇:requests封装,比较重要,离最终的框架又进了一步。
更多系列文章,可以关注微信公众号:ITester软件测试小栈

以上是关于Python接口自动化之Token详解及应用的主要内容,如果未能解决你的问题,请参考以下文章