带你走进MySQL数据库(MySQL入门详细总结一)
Posted huangjiahuan1314520
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了带你走进MySQL数据库(MySQL入门详细总结一)相关的知识,希望对你有一定的参考价值。
导读:关于mysql用三篇文章带你进入MySQL的世界。
MySQL开源免费,MySQL 是一个关系型数据库管理系统,由瑞典 MySQL AB 公司开发,目前属于 Oracle 公司。MySQL 是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。。MySQL 是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的 RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。
1.免安装版MySQL的安装
2.安装版MySQL的安装
MySQL的登录:
1.在doc窗口下输入:mysql -uroot -p加密码。(也可以敲回车后输入密码,这样密码不可见)。
2.MySQL服务默认端口号:3306。
3.修改root密码: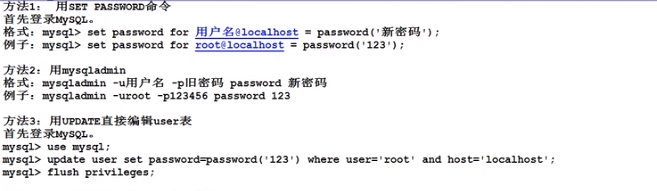

4.卸载MySQL
- 双击原来的安装包,然后点击remove。卸载。
- 手动删除Program File中的MySQL目录。
- 手动删除 ProgramDate目录(一般为隐藏)中的MySQL目录。
1.sql,DB,DBMS分别是什么?他们之间是什么关系?
- DB:DataBase(数据库,数据库实际上在硬盘上以文件的形式存在)
- 数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。
2.什么是表? - 表:table
- 表是数据库的基本组成单元,所有的数据都以表格的形式组织,目的是可读性强。
- 一个表包括行和列:
行:被称为数据/记录(data)
列:被称为字段。(column) - 每个字段应该包括哪些属性?
字段名,数据类型,相关的约束。
如:学号(int) 姓名(varchar) - RDBMS 即关系数据库管理系统(Relational Database Management System)的特点:
1.数据以表格的形式出现
2.每行为各种记录名称
3.每列为记录名称所对应的数据域
4.许多的行和列组成一张表单
5.若干的表单组成database
RDBMS 术语
在我们开始学习MySQL 数据库前,让我们先了解下RDBMS的一些术语: - 数据库: 数据库是一些关联表的集合。
- 数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 列: 一列(数据元素) 包含了相同类型的数据, 例如邮政编码的数据。
- 行:一行(=元组,或记录)是一组相关的数据,例如一条用户订阅的数据。
- 冗余:存储两倍数据,冗余降低了性能,但提高了数据的安全性。
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键:外键用于关联两个表。
- 复合键:复合键(组合键)将多个列作为一个索引键,一般用于复合索引。
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。
- 参照完整性: 参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。
3.MySQL主要学习SQL语句,SQL语句怎么分类呢? - DQL(数据查询语言):查询语句,凡是select语句都是DQL.
- DML(数据操作语言):insert delete update,对表当中的数据进行增删改。
- DDL(数据定义语言):create drop(删除) alte(修改),对表结构的增删改。
- TCL(事物控制语言):commit提交事务,rollback回滚事务。
- DCL(数据控制语言):qrant授权,revoke撤销权限。
第一步:登录mysql数据库管理系统。(mysql -uroot -p)
第二步:查看有哪些数据库
show databases;命令。(不是SQL语句,属于MySQL命令)
±-------------------+
| Database |
±-------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
±-------------------+
第三步:创建属于我们自己的数据库
create database xingkong;(这个是mysql命令)
第四步:使用xingkong数据库
use xingkong;(mysql命令)
第五步:查看当前使用的数据库有哪些表格(mysql命令)
show tables;(查看exam数据库中的表:show tables from exam;)
第六步:初始化数据
source 路径和文件名称;(这里自定义了一个数据库,一下出现的代码都是基于此)
5.xingkong.sql,这个文件以sql结尾,这样的文件被称为“sql脚本”。
什么是sql脚本?
- 当一个文件的扩展名为.sql,并且该文件中编写了大量的sql语句,我们称这样的为sql脚本。
- 注意:直接使用source命令可以执行sql脚本。
- sql脚本中的数据量太大的时候,无法打开,请使用source命令完成初始化。
6.删除数据库:
drop database xingkong;
7.查看表结构:
desc dept;部门表(自定义表)
desc emp;员工表(自定义表)
desc salgrade;工资等级表(自定义表)
8.表中的数据:
select * from emp;
select *from dept;
9. 查看当前用的数据库:
select database();
select version();版本
10.常用命令 - c 命令 结束一条语句。
- exit 命令,退出mysql;
11.查看创建表的语句:
show create table emp;
1.简单的查询语句(DQL)
- 语法格式:select 字段名1,字段名2,字段名3,…from 表名;
- 提示:任何一个sql语句以“;”结尾。
- sql语句不区分大小写。(但对表中存储的数据就不一样,mysql语法严格)
*** 查询的时候字段可以参与数学运算:**
select ename,sal*12 as (新名字) from emp;(ename,sal 为字段,emp为表)名字如果为中文需要用单引号括起来。(as关键字可以省略) - 字符串使用单引号括起来。
- 查询所有字段?
select * from emp;(emp为自定义的表),效率较低。
2.条件查询 - 语法格式:selcet 字段,字段,… from 表名 where 条件;条件为字符串需要单引号括起来。
执行顺序为:from,然后where,最后select;
不等于:<>符合。或!=。 - select ename ,sal from emp where sal between 11 and 500;
between …and 使用的时候必须左小右大,也可以使用在字符串方面。数字【左闭右闭】。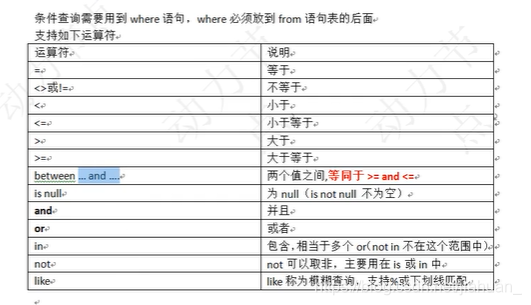
select ename from emp where ename between ‘a’ and ‘c’;首字母【左闭右开】。 - 在数据库中NULL不是一个之,代表什么也没有,不能用等号衡量,只能使用 is null 或者 is not null;(0和null表示的东西不一样)
- 找出工作岗位是xxx和xxxx的员工:
用or:select ename,job from emp where job = ‘xxx’ or job=‘xxxx’;可以加小括号来搞定优先级。
where job in (‘xxx’,‘xxxx’);不是一个区间,直接是一个值。
not in 表示不在。 - 模糊查询like?
找出名字当中含有嘉的?(模糊查询需掌握两个特殊的符号,一个是%,一个是_)
%代表任意多个字符,_代表任意一个字符。
如:*查找含A的(ename为自定义字段,emp为自定义表)
select ename from emp where ename like ‘%O%’;
*查找名字第二个字母是A的?
select ename from emp where ename like ‘_A%’;
*找出名字有下划线的?(用下划线转义)
select ename from emp where ename like ‘% _%’;
*找出名字中最后一个是T的?
select ename from emp where like ‘%T’;
1.按照工资升序,找出员工名和薪资?(默认升序)
select
ename,sal
from
emp
order by
sal;
注意:默认为升序,指定升序:asc,指定降序desc
select ename, sal from emp order by sal desc;
2.按照工资的降序排列,当工资相同的时候,按照名字的升序排序。
select ename,sal from emp order by sal desc,ename asc;
多个排序,靠前面的字段更加重要,去主导作用,后面的字段可能都用不上。
3.找出工作岗位是xxxx的员工,并且要求按照薪资的降序排列。
select
ename,job,sal
from
emp
where
job =‘xxxx’
order by
sal desc;
order by是最后执行的。先from,后where,再select,最后order by.
另称:多行处理函数。
- 一.那什么是单行处理函数呢?
输入一行,输出一行。 - 计算每个员工的年薪?
select ename ,(8000+NULL)*12 as yearsal from emp;(数据库中数学表达式中有NULL,结果一定是NULL) - ifnull()空处理函数怎么用?
ifnull(可能为null的数据,被当作什么处理):属于单行处理函数。
select ename ,ifnull(comn,0)as comm from emp;
二.分组函数(多行处理函数)
1.count 计数
2.sum 求和
3.avg 平均值
4.max 最大值
5.min 最小值
一共就这五个。
注意:所有的分组函数都是对“某一组”数据操作。 - 找出工资总和?
select sum(sal) from emp; - 找出最高工资?
select max(sal) from emp; - 找出平均工资?
select avg(sal) from emp; - 找出总人数?
select count(*) from emp;
select count(ename) from emp; - 输入多行,最终输出为一行。
- 分组函数自动忽略NULL。(不会统计)
所以:select sum(sal) from emp where sal is not nul;是没有必要的。
select count (comm)from emp;(comm自定义字段,含义:津贴) - 找出工资高于平均工资的员工?
- select ename,sal from emp where sal>avg(sal);//这种写法是错误的。
原因:**SQL语句当中有一个语法规则,分组函数不可以直接使用在where字句当中。**因为 group by是在where之后执行的。所以说还没有分组,不能用分组函数,没有group by 语句也自成一组,即有缺省的group by。
因此:解决问题的方法为:
第一步:找出平均工资
select avg(sal) from emp;
第二步:找出高于平均工资的员工。
select ename,sal,from emp where sal >2073.xx
综合起来:select ename ,sal from emp where sal>(select avg(sal) from emp);
±------±--------+
| ename | sal |
±------±--------+
| JONES | 2975.00 |
| BLAKE | 2850.00 |
| CLARK | 2450.00 |
| SCOTT | 3000.00 |
| KING | 5000.00 |
| FORD | 3000.00 |
±------±--------+ - count()和count(具体的某个字段),他们有什么区别。
count():不是统计某个字段中数据的个数,而是统计总记录条数。(和某个字段无关)count(comm):表示统计comm字段中不为NULL的数据总数量。
group by:按照某个字段或者某些字段进行分组。
having :having 是对分组之后的数据进行再次过滤。
两者必须联合使用。
案例:找出某个岗位的最高薪资?
1.先进行分组。
- select max(sal) from emp group by job;
注意:分组函数一般和group by联合使用,这也是为什么他被称为分组函数的原因。 - 任何一个分组函数count sum avg max min)都是在group by 语句执行结束之后才会执行的。当一条sql语句没有group by 的话,整张表就会自成一组。
- 当一条语句中有group by 时,select后面只能跟分组函数,和分组字段。
案例:找出每个部门,不同工作岗位的最高薪资?(两个字段联合分组)
select
deptno,job,max(sal)
from
emp
group by
deptno,job; - 找出每个部门的最高薪资,要求显示薪资大于2500的数据。
第一步:找出每个部门的最高薪资
select max(sal) ,deptno from emp group by deptno;
第二部:找出薪资大于2900
select max(sal) ,deptno from emp group by deptno having max(sal)>2900;//效率较低(较高的mysql版本不能用)
第二种方法:
select
max(sal) deptno
from
emp
where
sal>2900
group by
deptno;//效率较高
案例:找出每个部门的平均工资,要求显示薪资大于2000的数据。
第一步:找出每个部门的平均工资。
select deptno ,avg(sal) from emp group by deptno;
第二步:要求显示薪资大于2000的数据。
select deptno,avg(sal) from emp group by deptno having avg(sal) >2000;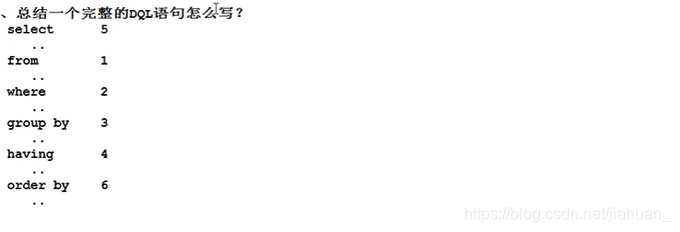
- select语句总

- 关于查询结果集的去重?
在select后加distinct关键字去除重复记录。
distinct关键字只能出现在所有字段的最前面。(不然不均衡啊)如果有多个字段,联合起来去重。
如:select distinct deptno ,job from emp;
结果:
±-------±----------+
| deptno | job |
±-------±----------+
| 20 | CLERK |
| 30 | SALESMAN |
| 20 | MANAGER |
| 30 | MANAGER |
| 10 | MANAGER |
| 20 | ANALYST |
| 10 | PRESIDENT |
| 30 | CLERK |
| 10 | CLERK |
±-------±----------+ - 统计岗位的数量?
select count(distinct job) from emp;
以上是关于带你走进MySQL数据库(MySQL入门详细总结一)的主要内容,如果未能解决你的问题,请参考以下文章