爬取哔哩哔哩影视榜单
Posted jiang0606
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取哔哩哔哩影视榜单相关的知识,希望对你有一定的参考价值。
一.主题式网络主题式网络爬虫设计方案
1.爬虫名称:爬取哔哩哔哩影视榜单
2.爬取内容:影片排名,影片标题,影片综合得分
3.网络爬虫设计方案概述:网页内容的选取 对所选取网页进行html解析 ,单击鼠标右键查看网页源代码,找到关键内容的索引标签,对标签进行分析理解,提取关键字眼。导入第三方库,再将所爬取到的内容进行数据清洗.分析,绘制图形方程,以及可视化处理。
4.技术难点:读取文件时出现异常,时常出现错误。
二、主题页面的结构特征分析
按ctrl+u进行查找,也可以点右键检查元素查看,要爬取的数据在标签class_="num",class_="title",class_="pts"
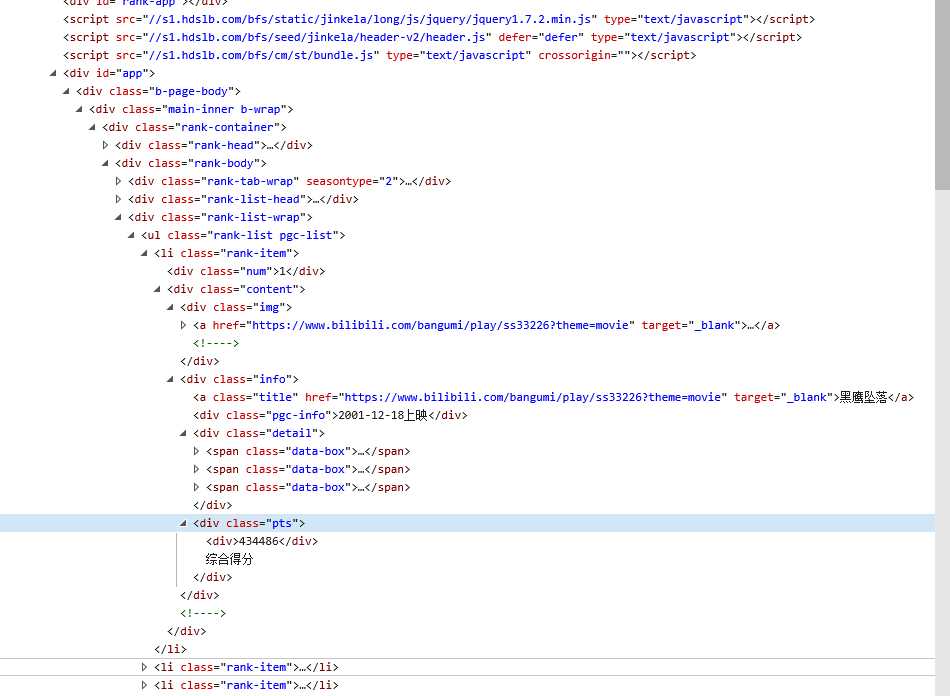
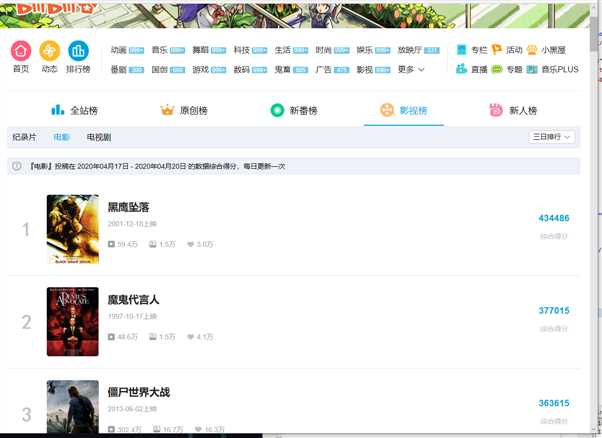
三,网络爬虫的程序设计代码:
1.数据的爬取及采集
#导入库
import requests
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
import csv
import scipy as sp
import seaborn as sns
from sklearn.linear_model import LinearRegression
from bs4 import BeautifulSoup
from pandas import DataFrame
from scipy.optimize import leastsq
#填入要请求的服务器地址
url="https://www.bilibili.com/ranking/cinema/23/0/3"#哔哩哔哩影视榜单
headers = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/69.0.3497.100 Safari/537.36‘}#伪装爬虫
#requests抓取网页信息
import requests
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
import csv
import scipy as sp
import seaborn as sns
from sklearn.linear_model import LinearRegression
from bs4 import BeautifulSoup
from pandas import DataFrame
from scipy.optimize import leastsq
#填入要请求的服务器地址
url="https://www.bilibili.com/ranking/cinema/23/0/3"#哔哩哔哩影视榜单
headers = {‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/69.0.3497.100 Safari/537.36‘}#伪装爬虫
#requests抓取网页信息
def getHTMLText(url,timeout=30):
try:
r=requests.get(url,timeout=30) #用requests抓取网页信息
r.raise_for_status() #异常捕捉
r.encoding=r.apparent_encoding
return r.text
except:
return‘产生异常‘
try:
r=requests.get(url,timeout=30) #用requests抓取网页信息
r.raise_for_status() #异常捕捉
r.encoding=r.apparent_encoding
return r.text
except:
return‘产生异常‘
#html.parser表示用BeautifulSoup库解析网页
html=getHTMLText(url)
soup=BeautifulSoup(html,‘html.parser‘)
print(soup.prettify())
#按照标准缩进格式的结构输出
r=requests.get(url)
#请求网络
r.encoding=r.apparent_encoding
#统一编码
html = r.text
soup = BeautifulSoup(html,‘lxml‘)
#使用工具
rank=[]
title=[]
grade=[]
for i in soup.find_all(class_="num"):
rank.append(i.get_text().strip())
for j in soup.find_all(class_="title"):
title.append(j.get_text().strip())
for n in soup.find_all(class_="pts"):
grade.append(n.get_text().strip())
data=[rank,title,grade]
print(data)
df=pd.DataFrame(data,index=["排名","标题","评分"])
#数据可视化
print(df.T)
df.to_excel(‘C:pythonpython作业.xlsx‘)
file="C:pythonpython作业.xlsx"
chinese=matplotlib.font_manager.FontProperties(fname=‘C:/Windows/Fonts/simsun.ttc‘)
df = pd.DataFrame(pd.read_excel("rank","title","grade"))
html=getHTMLText(url)
soup=BeautifulSoup(html,‘html.parser‘)
print(soup.prettify())
#按照标准缩进格式的结构输出
r=requests.get(url)
#请求网络
r.encoding=r.apparent_encoding
#统一编码
html = r.text
soup = BeautifulSoup(html,‘lxml‘)
#使用工具
rank=[]
title=[]
grade=[]
for i in soup.find_all(class_="num"):
rank.append(i.get_text().strip())
for j in soup.find_all(class_="title"):
title.append(j.get_text().strip())
for n in soup.find_all(class_="pts"):
grade.append(n.get_text().strip())
data=[rank,title,grade]
print(data)
df=pd.DataFrame(data,index=["排名","标题","评分"])
#数据可视化
print(df.T)
df.to_excel(‘C:pythonpython作业.xlsx‘)
file="C:pythonpython作业.xlsx"
chinese=matplotlib.font_manager.FontProperties(fname=‘C:/Windows/Fonts/simsun.ttc‘)
df = pd.DataFrame(pd.read_excel("rank","title","grade"))
df.head()
#数据清洗
#删除无效列和行
print(df.drop(‘标题‘,axis=1,inplace = True))
print(df.head(20))
#删除无效列和行
print(df.drop(‘标题‘,axis=1,inplace = True))
print(df.head(20))
#重复值处理
print(df.duplicated())
print(df.duplicated())
#统计空值
print(df.isnull().sum()) #返回0则没有空值
print(df.isnull().sum()) #返回0则没有空值
#缺失值处理
print(df[df.isnull().values==True]) #返回无缺失值
print(df[df.isnull().values==True]) #返回无缺失值
#用describe()命令显示描述性统计指标
print(df.describe())
print(df.describe())
#用来正常显示中文
plt.rcParams[‘font.sans-serif‘]=[‘Arial Unicode MS‘]
#用来正常显示负号
plt.rcParams[‘axes.unicode_minus‘]=False
plt.rcParams[‘font.sans-serif‘]=[‘Arial Unicode MS‘]
#用来正常显示负号
plt.rcParams[‘axes.unicode_minus‘]=False
#绘制排名与评分的回归图
X = df.drop("排名",axis=1)
predict_model = LinearRegression()
predict_model.fit(X,df[‘评分‘])
print("回归系数为:",predict_model.coef_)
#绘制排名与评分的回归图
plt.rcParams[‘font.sans-serif‘]=[‘STSong‘]#显示中文
sns.regplot(df.排名,df.评分)
# 绘制垂直柱状图
plt.bar(df.排名, df.评分, label="排名与综合得分柱状图")
plt.show()
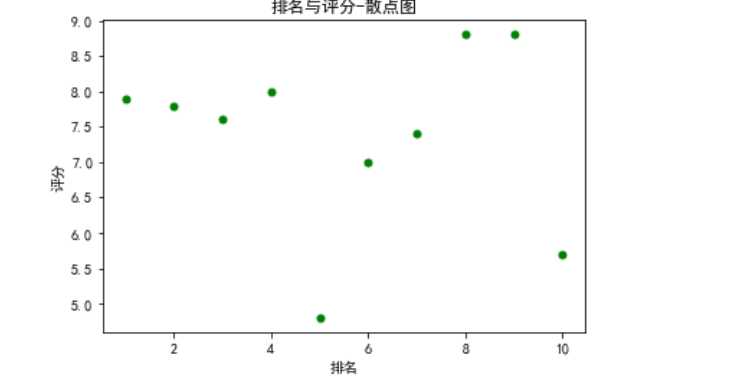
#绘制散点图
def fill0():
plt.scatter(df.排名, df.评分, color=‘green‘, s=24, marker="o")
plt.xlabel("排名")
plt.ylabel("评分")
plt.title("排名与评分-散点图")
plt.show()
fill0()
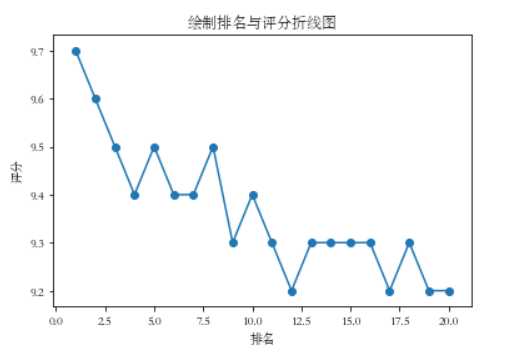
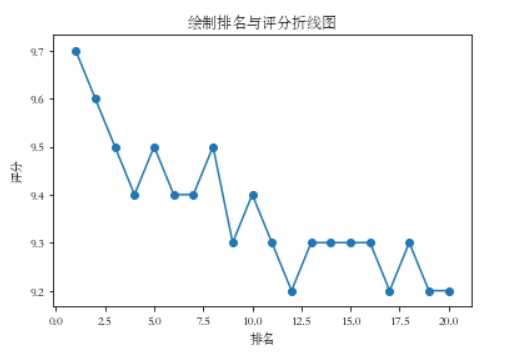
#绘制折线图
def fill1():
x = df[‘排名‘]
y = df[‘评分‘]
plt.xlabel(‘排名‘)
plt.ylabel(‘评分‘)
plt.plot(x,y)
plt.scatter(x,y)
plt.title("排名与评分折线图")
plt.show()
fill1()
#绘制排名与评分-箱体图
def fill2():
plt.figure(figsize=(10, 5))
plt.title(‘绘制排名与评分-箱体图‘)
sns.boxplot(x=‘排名‘,y=‘评分‘, data=df)
fill2()
#绘制部分分布图
sns.jointplot(x="排名",y=‘评分‘,data = df, kind=‘kde‘, color=‘lime‘)
sns.jointplot(x="排名",y=‘评分‘,data = df)
sns.jointplot(x="排名",y=‘评分‘,data = df, kind=‘reg‘)
sns.jointplot(x="排名",y=‘评分‘,data = df, kind=‘hex‘)
#绘制直方图
filename = ‘C:pythonpython作业.xlsx‘
colnames=["rank","title","grade"]
df = pd.read_excel(filename,skiprows=1,names=colnames)
a=np.arrray(df.grade)
b=df.title
s=pd.Series(a,b)
s.name=‘影片与评分统计值‘
s.plot(kind=‘bar‘,title=‘影片与评分统计值‘)
plt.grid()
plt.show()
b=df.title
s=pd.Series(a,b)
s.name=‘影片与评分统计值‘
s.plot(kind=‘bar‘,title=‘影片与评分统计值‘)
plt.grid()
plt.show()
#绘制一元一次回归方程
def main():
colnames = ["排名", "标题", "评分"]
df = pd.read_excel(‘C:pythonpython作业.xlsx‘,skiprows=1,names=colnames)
X = df.排名
Y = df.评分
def fit_func(p, x):
k, b = p
return k * x + b
def error_func(p, x, y):
return fit_func(p,x)-y
p0=[0,0]
Para=leastsq(error_func, p0, args = (X, Y))
k,b=Para[0]
print("k=",k,"b=",b)
plt.figure(figsize=(10,5))#图像比例
plt.scatter(X,Y,color="green",label=u"得分分布",linewidth=2)
x=np.linspace(0,40,20)
y=k*x+b
plt.plot(x,y,color="red",label=u"回归方程直线",linewidth=2)
plt.title("电影排名和评分关系图")
plt.xlabel(‘排名‘)
plt.ylabel(‘评分‘)
plt.legend(loc=3,prop=chinese)#绘制图例
plt.show()
main()
#绘制一元二次方程
chinese=matplotlib.font_manager.FontProperties(fname=‘C:/Windows/Fonts/simsun.ttc‘)
#设置中文字体
plt.rcParams[‘font.sans-serif‘]=[‘Arial Unicode MS‘]
plt.rcParams[‘axes.unicode_minus‘]=False
filename="C:pythonpython作业.xlsx"
colnames=["排名","标题","评分"]
df=pd.read_excel(filename,skiprows=1,names=colnames)
X=df.排名 #确定x轴
Y=df.评分 #确定y轴
def func(params,x): #二次函数的标准形式
a, b, c =params
return a * x * x + b * x + c
#误差函数
def error(params,x,y):
return func(params,x)-y
a, b, c =params
return a * x * x + b * x + c
#误差函数
def error(params,x,y):
return func(params,x)-y
p0=[1978,20]
def main2():
#主函数
plt.figure(figsize=(10,6))
p0=[1980,300,1]
Para=leastsq(error,p0,args=(X,Y))
a,b,c=Para[0]
print("a=", a, "b=", b, "c=", c)
plt.scatter(X,Y,color="green",label="样本数据",linewidth=2)
#画拟合曲线
x=np.linspace(1,50,50)
y=a * x * x + b * x + c
plt.plot(x,y,color="red",label="拟合曲线",linewidth=2)
plt.legend()
plt.title("影片排名与评分一元二次方程关系图")
plt.grid()
plt.show()
main2()
def main2():
#主函数
plt.figure(figsize=(10,6))
p0=[1980,300,1]
Para=leastsq(error,p0,args=(X,Y))
a,b,c=Para[0]
print("a=", a, "b=", b, "c=", c)
plt.scatter(X,Y,color="green",label="样本数据",linewidth=2)
#画拟合曲线
x=np.linspace(1,50,50)
y=a * x * x + b * x + c
plt.plot(x,y,color="red",label="拟合曲线",linewidth=2)
plt.legend()
plt.title("影片排名与评分一元二次方程关系图")
plt.grid()
plt.show()
main2()
#数据持久化
def create_file(file_path,msg):
Resou =r‘C:python哔哩哔哩影视榜单.xlsx‘
df = pd.DataFrame(msg,columns=[‘排名‘,‘标题‘,‘评分‘])
df.to_excel(Resou)
print()
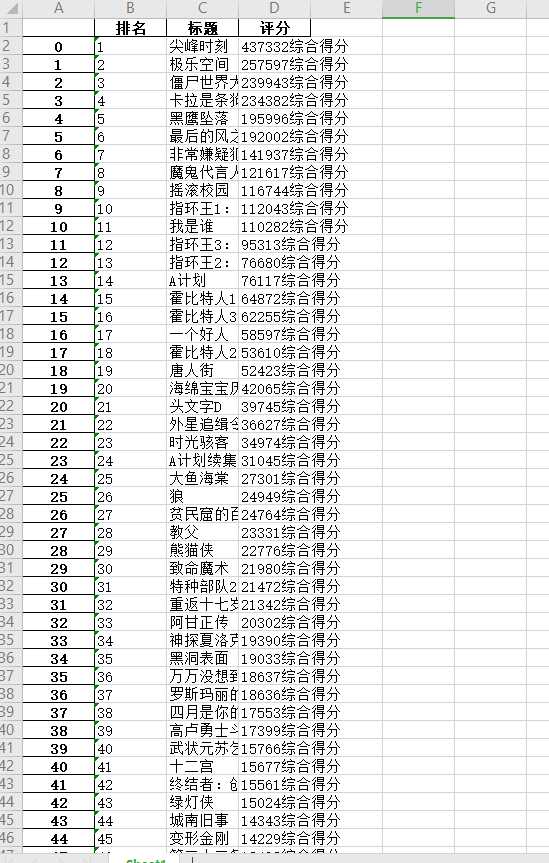
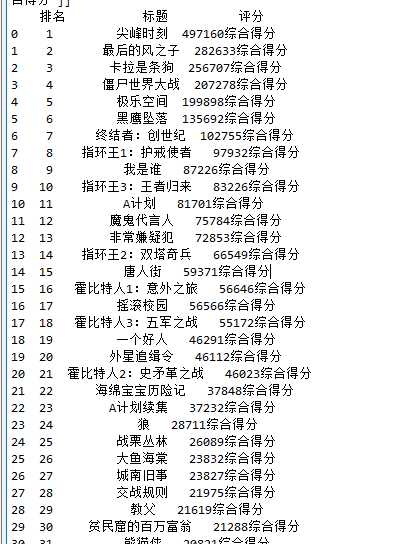
#数据清洗 #重复值处理 print(df.duplicated()) #统计空值 print(df.isnull().sum()) #返回0则没有空值 #缺失值处理 print(df[df.isnull().values==True]) #返回无缺失值 #用describe()命令显示描述性统计指标 print(df.describe())
#绘制排名与综合得分的回归图 X = df.drop("排名",axis=1) predict_model = LinearRegression() predict_model.fit(X,df[‘评分‘]) print("回归系数为:",predict_model.coef_
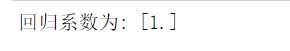
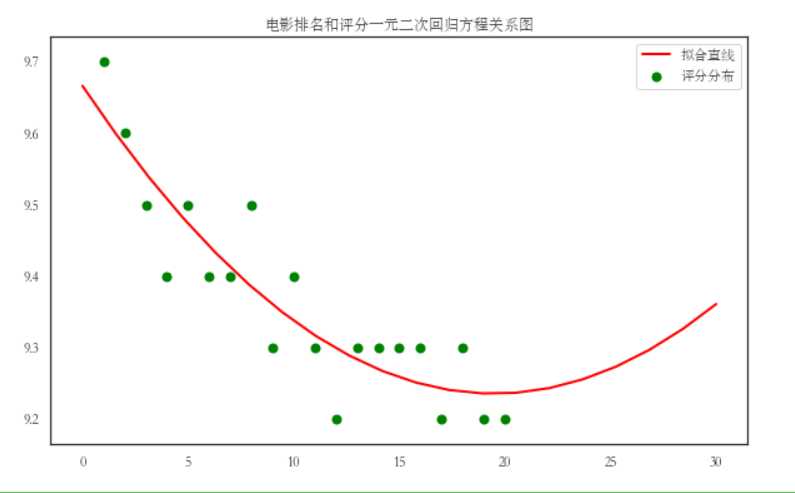
#绘制一元二次方程 chinese=matplotlib.font_manager.FontProperties(fname=‘C:/Windows/Fonts/simsun.ttc‘) #设置中文字体 plt.rcParams[‘font.sans-serif‘]=[‘Arial Unicode MS‘] plt.rcParams[‘axes.unicode_minus‘]=False filename="C:pythonpython作业.xlsx" colnames=["排名","标题","评分"] df=pd.read_excel(filename,skiprows=1,names=colnames) X=df.排名 #确定x轴 Y=df.评分 #确定y轴 def func(params,x): #二次函数的标准形式 a, b, c =params return a * x * x + b * x + c #误差函数 def error(params,x,y): return func(params,x)-y p0=[1978,20] def main2(): #主函数 plt.figure(figsize=(10,6)) p0=[1980,300,1] Para=leastsq(error,p0,args=(X,Y)) a,b,c=Para[0] print("a=", a, "b=", b, "c=", c) plt.scatter(X,Y,color="green",label="样本数据",linewidth=2) #画拟合曲线 x=np.linspace(1,50,50) y=a * x * x + b * x + c plt.plot(x,y,color="red",label="拟合曲线",linewidth=2) plt.legend() plt.title("影片排名与评分一元二次方程关系图") plt.grid() plt.show() main2()
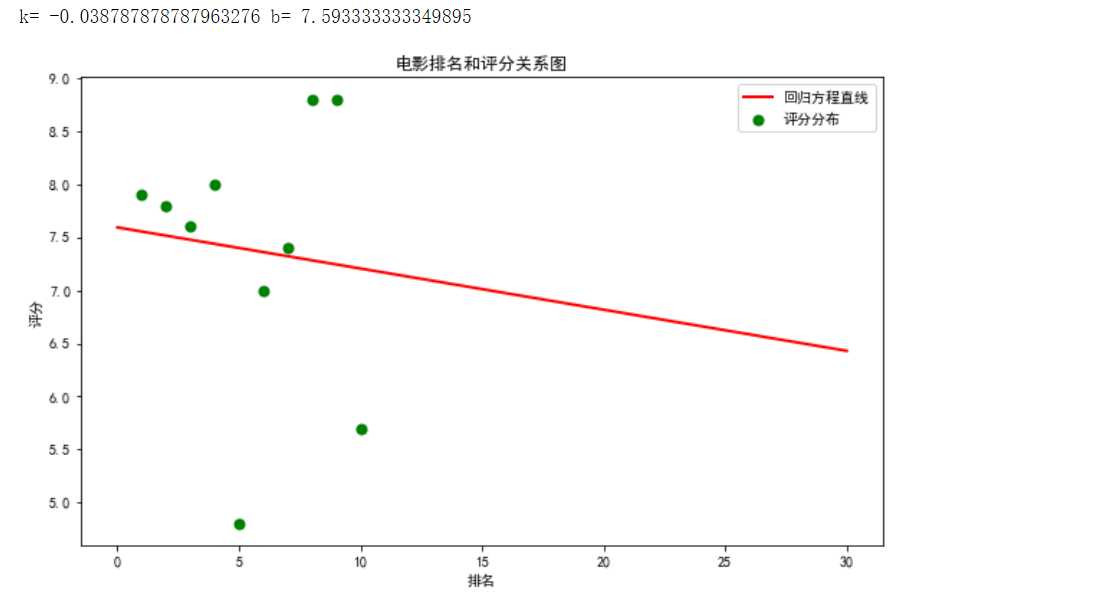
#绘制一元一次回归方程 def main(): colnames = ["排名", "标题", "评分"] df = pd.read_excel(‘C:pythonpython作业.xlsx‘,skiprows=1,names=colnames) X = df.排名 Y = df.评分 def fit_func(p, x): k, b = p return k * x + b def error_func(p, x, y): return fit_func(p,x)-y p0=[0,0] Para=leastsq(error_func, p0, args = (X, Y)) k,b=Para[0] print("k=",k,"b=",b) plt.figure(figsize=(10,5))#图像比例 plt.scatter(X,Y,color="green",label=u"得分分布",linewidth=2) x=np.linspace(0,40,20) y=k*x+b plt.plot(x,y,color="red",label=u"回归方程直线",linewidth=2) plt.title("电影排名和评分关系图") plt.xlabel(‘排名‘) plt.ylabel(‘评分‘) plt.legend(loc=3,prop=chinese)#绘制图例 plt.show() main()
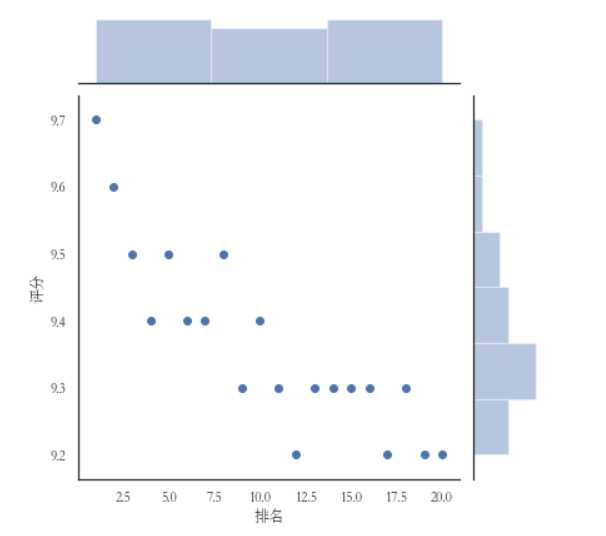
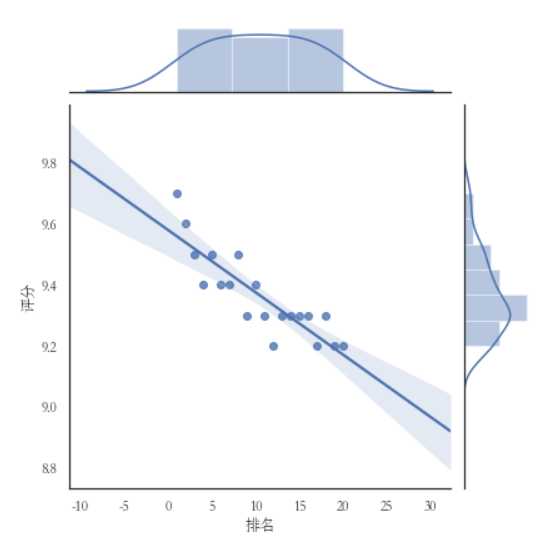
#绘制部分分布图 sns.jointplot(x="排名",y=‘评分‘,data = df, kind=‘kde‘, color=‘lime‘) sns.jointplot(x="排名",y=‘评分‘,data = df) sns.jointplot(x="排名",y=‘评分‘,data = df, kind=‘reg‘) sns.jointplot(x="排名",y=‘评分‘,data = df, kind=‘hex‘)
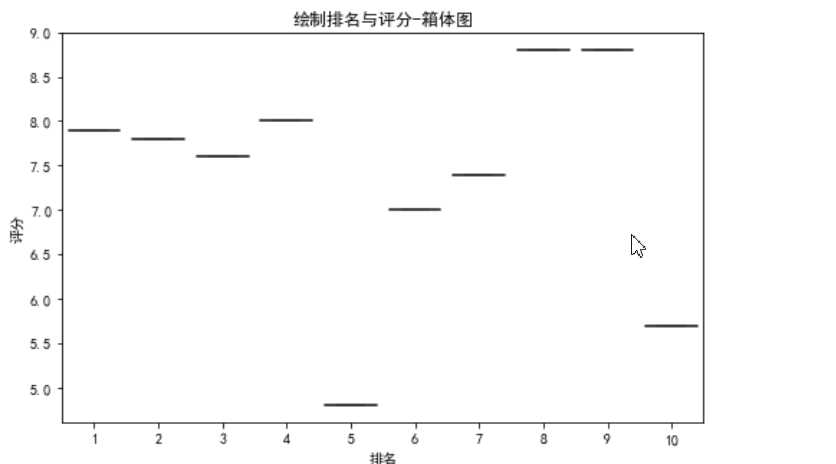
#绘制散点图 def fill0(): plt.scatter(df.排名, df.评分, color=‘green‘, s=24, marker="o") plt.xlabel("排名") plt.ylabel("评分") plt.title("排名与评分-散点图") plt.show() fill0() #绘制折线图 def fill1(): x = df[‘排名‘] y = df[‘评分‘] plt.xlabel(‘排名‘) plt.ylabel(‘评分‘) plt.plot(x,y) plt.scatter(x,y) plt.title("排名与评分折线图") plt.show() fill1() #绘制排名与评分-箱体图 def fill2(): plt.figure(figsize=(10, 5)) plt.title(‘绘制排名与评分-箱体图‘) sns.boxplot(x=‘排名‘,y=‘评分‘, data=df) fill2()
四.结论
1.编写过程还有许多漏洞是自己无法解决的,还有显示图片的问题,有通过同学的帮助和查找百度来处理问题。
2.通过这次作业才发现自己原来有这么多不足,知识点不全面,还有很大的提升空间,只有多写多看多用才能做到真正的掌握。
希望今后的学习自己可以下决心更用功,学习python的用处还是很大的,值得在这方向上更进一步,也希望在老师的指导和
带领下能越学越好。
以上是关于爬取哔哩哔哩影视榜单的主要内容,如果未能解决你的问题,请参考以下文章