爬虫学习进行式
Posted ahugecat
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫学习进行式相关的知识,希望对你有一定的参考价值。
爬虫这一节内容说难也难,说简单也简单,这就要看每个人要求了!我写了两个爬虫程序,算是分享一下我的心路历程吧!毕竟我是要搞AI和CTF的呢!
首先是在学习爬虫几天后的粗糙产品,简单的爬取了一下QQ音乐的榜单(感觉不正规)
同样,主要技术路径是requests-bs4的方法来执行的,通过import requests和from bs4 import BeautfulSoup来提供技术支持
我用的URL为:url="http://www.9ku.com/music/sshot.htm 一个第三方网站榜单网站
Talk is cheap show me the code
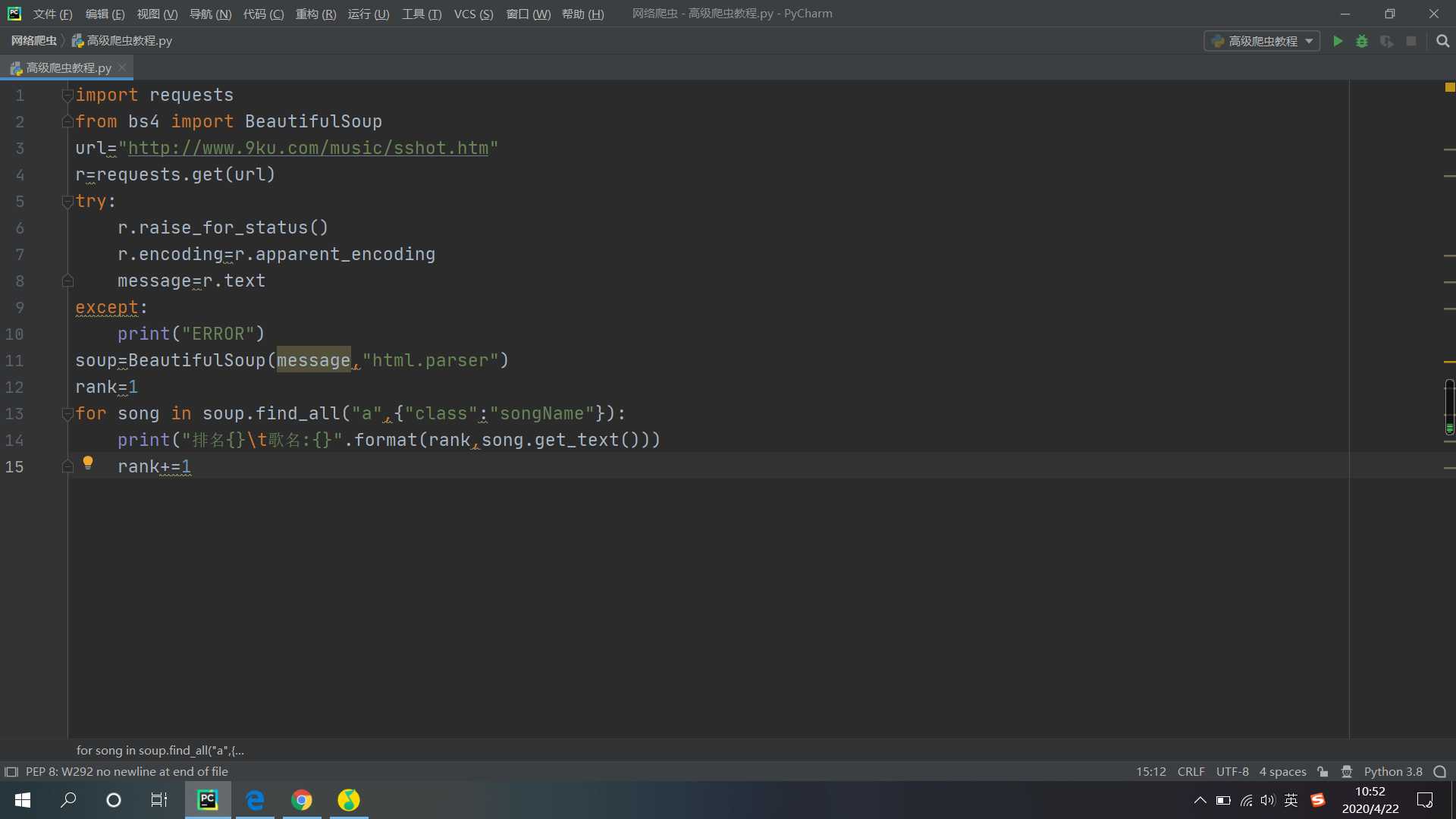
运用MOOC里面讲到的基础框架为基础,这里我get_有一个小总结,如果想要获得一个标签下的文本内容,可以使用Tag.get_text()来获得文本内容!
当然使用正则表达式也不是不可以
关键代码如下:print(re.search(">.*<",str(song)).group()),但是这样做会出现左右两端尖括号不是很美观
最后输出结果如下(部分):
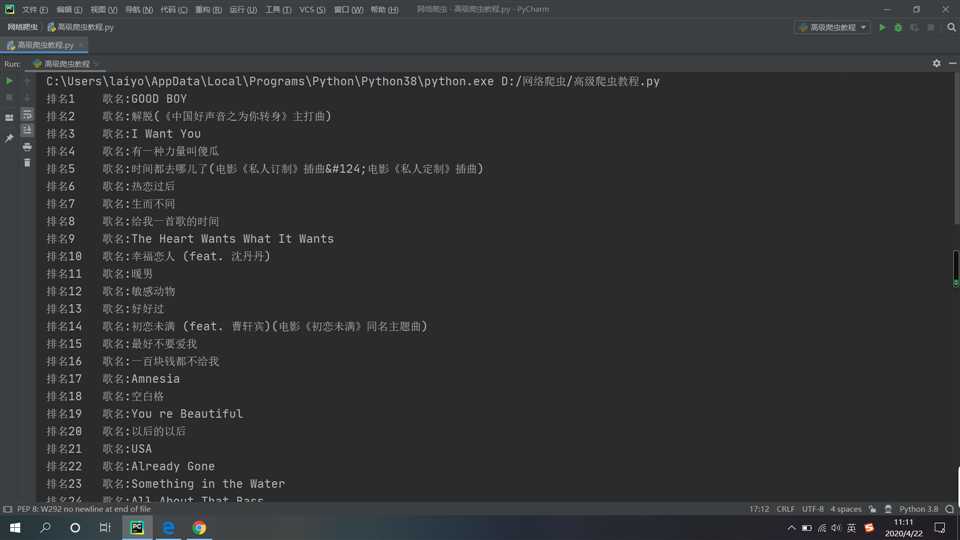
虽然爬虫做出来了但是似乎不那么的好!于是有了2.0版本,只是稍稍改动了一点,原理还是一样,这次爬取的是酷狗的
代码有点长,我就放在GitHub上的,欢迎大家批评指正
https://gist.github.com/A-Huge-Cat/911a4f1d10721d33f9e0f2f0d2c8a78d(第一次用,也不知道能不能访问,不能的话请给我留言)
以上是关于爬虫学习进行式的主要内容,如果未能解决你的问题,请参考以下文章