端到端全景分割
Posted wujianming-110117
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了端到端全景分割相关的知识,希望对你有一定的参考价值。
端到端全景分割
An End-to-End Network for Panoptic Segmentation
摘要
全景分割是一个具有挑战性的课题,它需要为每个像素指定一个类别标签,同时对每个对象实例进行分割。传统上,现有的方法使用两个独立的模型,而不共享特性,这使得流水线不易实现。此外,通常采用启发式方法对结果进行合并。然而,在合并过程中,如果没有足够的上下文信息,很难确定对象实例之间的重叠关系。为了解决这一问题,本文提出了一种新的端到端遮挡感知网络(OANet),它可以有效地预测单个网络中的实例和内容分割。此外,本文还引入了一个新的空间排序模块来处理预测实例之间的遮挡问题。通过大量的实验验证了该方法的有效性,并在COCO全景基准上取得了良好的效果。
1. Introduction
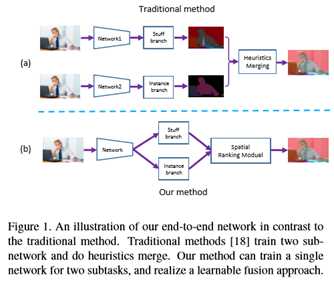
在本文中,本文提出了一种新的端到端算法,如图1(b)所示。据本文所知,这是第一个能够在端到端管道中处理上述问题的算法。更具体地说,本文将实例分割和内容分割合并到一个网络中,该网络共享主干特性,但对这两个任务应用不同的头分支。在训练阶段,主干功能将通过多项监督的累积损失进行优化,而总分支将只对特定任务进行微调。
为了解决对象实例之间存在重叠关系的问题,提出了一种新的空间排序模块算法。本模块学习排名分数,并为实例提供排序依据。
总之,本文将算法的贡献总结如下:
•本文首先提出了一种端到端的遮挡感知管道,用于解决全景分割问题。
•本文引入了一个新的空间排序模块来解决重叠关系的模糊性,这种模糊性通常存在于全景分割问题中。
•本文在COCO全景分割数据集上获得最先进的性能。
2. Proposed End-to-end Framework
本文算法的概述如图2所示。本文的算法有三个主要部分:
1) stuff分支预测整个输入的stuff分段。
2) 实例分支提供实例分段预测。
3) 空间排名模块为每个实例生成一个排名分数。
3.1. End-to-end Network Architecture
本文采用FPN[26]作为端到端网络的骨干架构。例如分割,本文采用原始的Mask R-CNN[14]作为本文的网络框架。本文应用自顶向下的路径和横向连接来获得特征地图。然后,附加3×3卷积层得到RPN特征映射。之后,本文申请ROIAlign[14]层用于提取对象建议特征并获得三个预测:建议分类分数、建议边界框坐标和建议实例掩码。
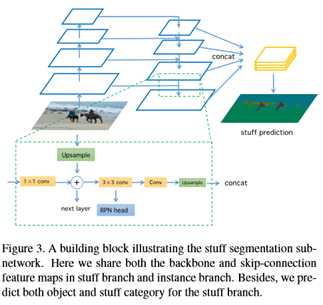
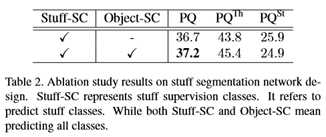
对于材料分割,在RPN特征图上叠加两个3×3卷积层。为了实现多尺度特征提取,本文将这些层与后续的3×3卷积层和1×1卷积层连接起来。图3显示了stuff分支的详细信息。在训练过程中,由于辅助目标信息可以为目标的预测提供对象上下文,所以本文同时对目标的分割和分割进行监控。在推论中,本文只提取材料预测并将其标准化为概率。为了突破培训过程中的信息流动障碍,提高整个管道的效率,本文共享了两个分支的骨干网络的特点。
这里提出的问题可以分为两部分:
1) 特征映射上的共享粒度
2) 实例丢失和数据丢失之间的平衡。
在实践中,本文发现随着更多的特征图被共享,本文可以获得更好的性能。因此,本文共享特征映射,直到跳过连接层,即图3所示的RPN头之前的3×3卷积层。
2.2. Spatial Ranking Module
现代的实例分割框架通常是基于对象检测网络和一个附加的掩模预测分支,如掩模RCNN[14]通常是基于FPN[26]。一般来说,当前的目标检测框架不考虑不同类别之间的重叠问题,因为流行的度量不受此问题的影响,例如AP和AR。然而,在全景分割任务中,由于一个图像中的像素数是固定的,因此重叠问题,或者具体来说,必须解决一个像素的多个指定。
一般情况下,检测得分是用来对实例进行降序排序,然后根据得分较大的对象在得分较低的对象之上的规则将其分配给stuff画布。然而,这种启发式算法在实际应用中很容易失败。例如,让本文考虑一个戴领带的人,如图7所示。由于person类比COCO数据集中的tie更频繁,因此其检测分数往往高于tie边界框。因此,通过上面的简单规则,tie实例被person实例覆盖,导致性能下降。
本文可以通过全景注释来缓解这种现象吗?也就是说,如果本文强迫网络学习的人在标注的地方打一个洞,可以避免上述情况吗?如表3所示,本文使用上述注释进行实验,但仅发现衰减的性能。因此,这种方法目前不适用。为了解决这一问题,本文采用了一种类似语义的方法,提出了一种简单而有效的解决遮挡问题的算法,称为空间排序模块。
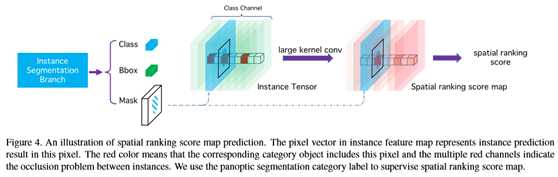
如图4所示,本文首先映射结果实例分割到输入大小的张量。特征映射的维数是对象类别的个数,不同类别的实例映射到相应的通道。
3. Experiments
3.1. Dataset and Evaluation Metrics
数据集:
本文在COCO全景分割数据集上进行了所有实验[18]。这个数据集包含118K个用于训练的图像,5k个用于验证的图像,其中80个类别的内容有注释,53个类别的内容有注释。本文只使用训练图像进行模型训练和验证集测试。最后,本文将测试开发结果提交给COCO 2018全景分割排行榜。
评估指标:
本文使用[18]中定义的标准评估指标,称为全景质量(PQ)。
它包含两个因素:
1) 分割质量(SQ)衡量所有类别和
2) 检测质量(DQ)仅测量实例类。
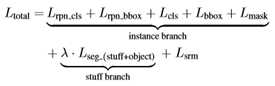
PQ、SQ和DQ的数学形式在等式5中给出,其中p和g是预测和基本真值,TP、FP、FN表示真阳性、假阳性和假阴性。
很容易发现SQ是匹配实例的常用平均IOU度量,DQ可以看作是检测精度的一种形式。匹配阈值设置为0.5,即如果预测的像素IOU和地面真值大于0.5,则认为预测匹配,否则不匹配。对于stuff类,图像中的每个stuff类都被视为一个实例,无论其形状如何。
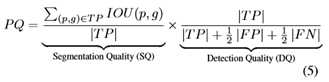
3.2. Implementation Details
本文选择ResNet-50[16]在ImageNet上预训练用于消融研究。本文使用SGD作为优化算法,动量为0.9,权值衰减为0.0001。采用带预热策略的多阶段学习率策略[33]。也就是说,在最初的2000次迭代中,本文通过将学习率从0.002提高到0.02来使用线性渐进预热策略。在60000次迭代之后,本文将学习率降低到0.002(对于接下来的20000次迭代),并进一步将其设置为0.0002(对于剩余的20000次迭代)。输入的批大小设置为16,这意味着每个GPU在一次迭代中使用两个图像。对于其他细节,本文使用Mask RCNN的经验[14]。除了对本文网络的两个分支进行培训外,还应该注意空间排名模块。在训练过程中,监督标签是对应的非重叠语义标签,训练为语义分割网络。本文设置忽略的非冲突像素,以强制网络聚焦于冲突区域。

3.3. Ablation Study on Network Structure
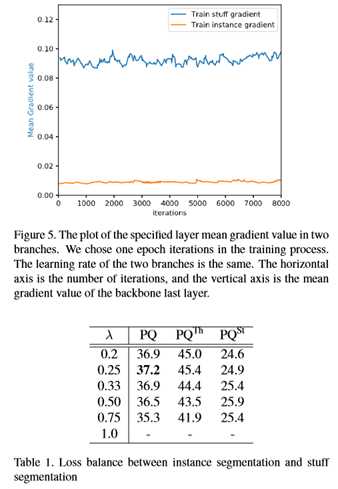
在本小节中,本文将重点介绍端到端网络设计的特性。本文主要讨论了三个问题:损失平衡参数、业务分支的对象上下文和两个分支的共享模式。为了避免实验的笛卡尔积,本文只修改特定的参数,并对另一个参数进行最优控制。
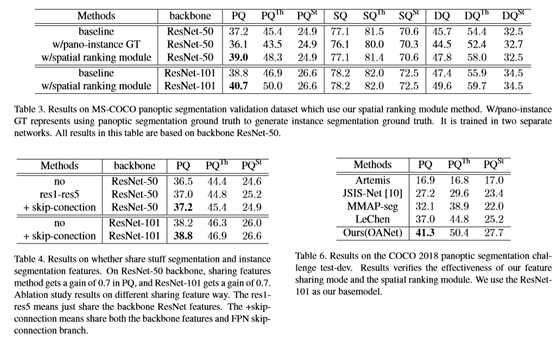
3.4. Ablation Study on Spatial Ranking Module
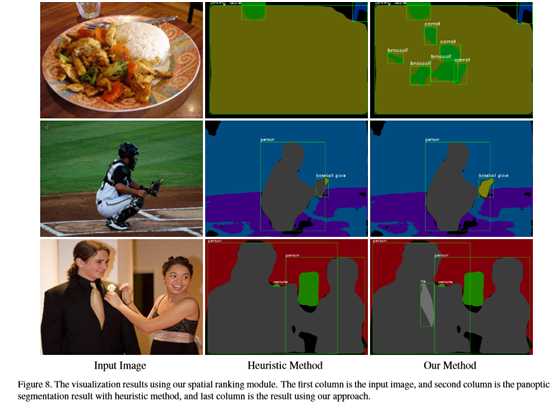
图7解释了本文的空间排名模块的原理。对于示例输入图像,网络预测一个人加一个平局,其包围盒得分分别为0.997和0.662。如果本文用分数来决定结果,平局将完全由该人来决定。然而,在本文的方法中,本文可以得到每个实例的空间排名分数,分别为0.325和0.878。借助新的分数,本文可以得到正确的预测。图8总结了更多的例子。

4. Conclusion
本文提出了一种新的端到端遮挡感知算法,该算法将常见的语义分割和实例分割融合到一个模型中。为了更好地利用不同的监控机制,减少计算资源的消耗,本文研究了不同分支之间的特征共享问题,认为应该尽可能多地共享特征。此外,本文还观察了全景分割中提出的特殊排序问题,并设计了简单而有效的空间排序模块来解决这一问题。实验结果表明,本文的方法优于以前的最新模型。
以上是关于端到端全景分割的主要内容,如果未能解决你的问题,请参考以下文章
MATLAB深度学习采用 Deeplab v3+ 实现全景分割