运用jieba库统计词频及制作词云
Posted slj-xt
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了运用jieba库统计词频及制作词云相关的知识,希望对你有一定的参考价值。
一、对新时代中国特色社会主义做词频统计
import jieba txt = open("新时代中国特色社会主义.txt","r",encoding="utf-8").read() words = jieba.lcut(txt) counts = {} for word in words: if len(word) == 1: continue else: counts[word] = counts.get(word,0)+1 items = list(counts.items()) items.sort(key=lambda x:x[1], reverse=True) for i in range(20): word, count = items[i] print("{0:<10}{1:>5}".format(word, count))
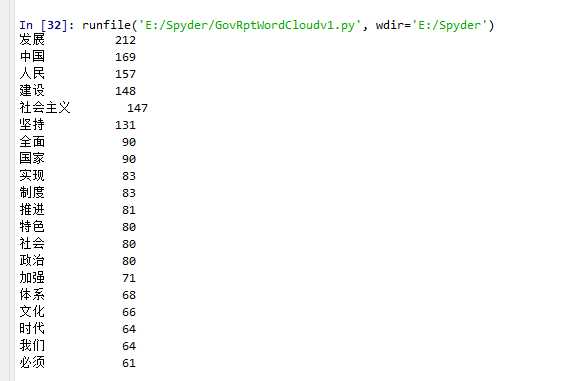
二、根据词频制作词云
#GovRptWordCloudv2.py import jieba import wordcloud from imageio import imread mask = imread("dd.png") f = open("新时代中国特色社会主义.txt","r",encoding="utf-8") t = f.read() f.close() ls = jieba.lcut(t) txt = " ".join(ls) w = wordcloud.WordCloud(font_path = "simkai.ttf",mask = mask,width = 1000,height = 700,background_color = "black",max_words = 20) w.generate(txt) w.to_file("grwordcloud.png")

以上是关于运用jieba库统计词频及制作词云的主要内容,如果未能解决你的问题,请参考以下文章