Solr7-4的学习与使用
Posted yangk1996
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Solr7-4的学习与使用相关的知识,希望对你有一定的参考价值。
学习的原因:
17年的时候有学习使用过lucene和solr,但是后来也遗忘了,最近公司有个项目需要使用到全文检索,正好也顺便跟着学习一下,使用的版本是Solr7.4的,
solr解压之后的目录结构:
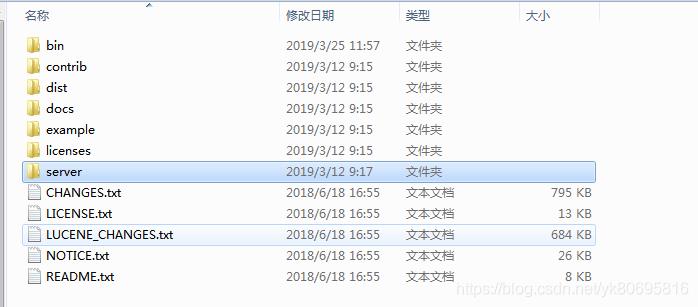
各文件夹里面的内容:
solr从5版本之后不再需要tomcat,使用内置的jetty启动。
下面开始正式开始学习使用Solr:
- 启动solr
因为现在solr使用的内置服务器,我们只需要通过命令启动就可以了。切换到bin目录。
shift+右键
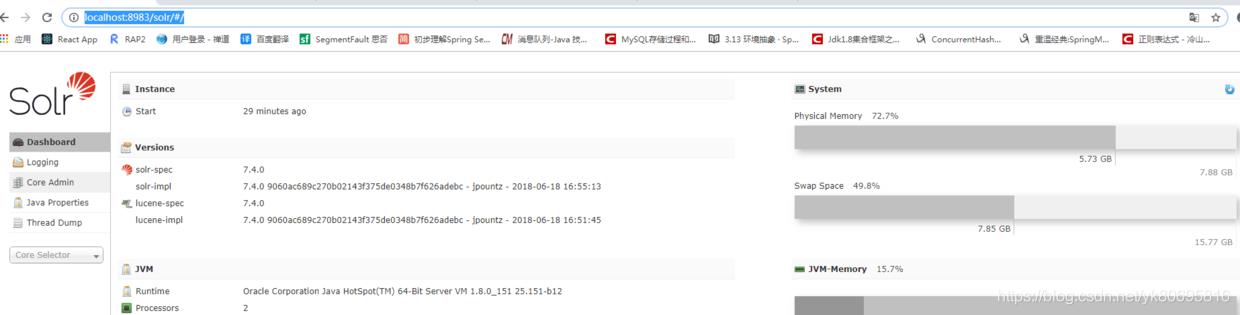
出现黑窗口,输入solr start


- 配置Solr核心(可以理解为solr的数据库)
配置core有两种方式一种是官方推荐的,一种是在admin页面创建
(1)通过Core Admin创建
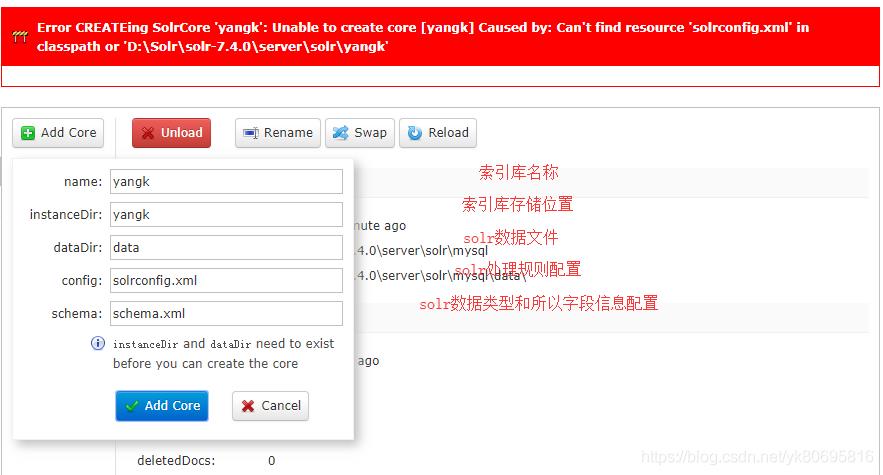
这样创建会报错。可以看到错误提示 无法找打solrconfig.xml文件。这里注意下:创建的instanceDir和dataDir 需存在,就是我们需在solr-7.4.0serversolr 目录下先去创建目录
此目录下的conf文件我们可从serversolrconfigsetssample_techproducts_configs中复制
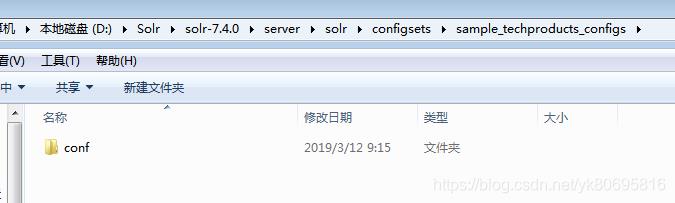
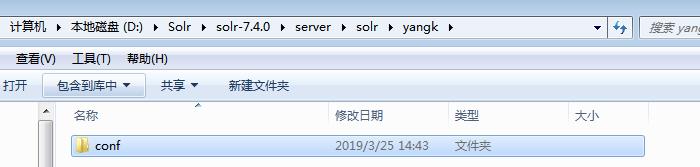
这样再去新增就可以了
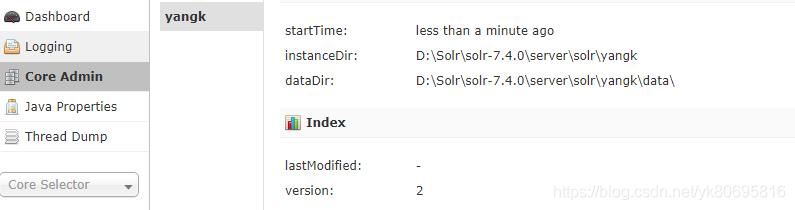
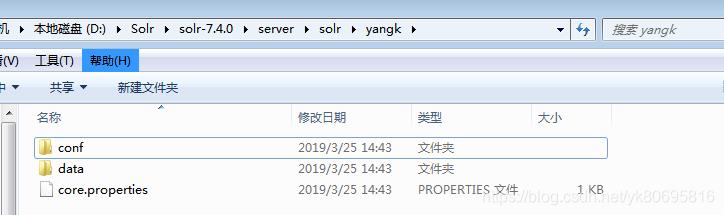
(2)官方推荐
使用命令 solr create -c test

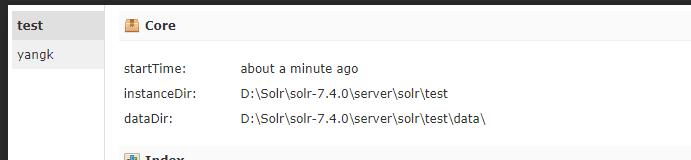
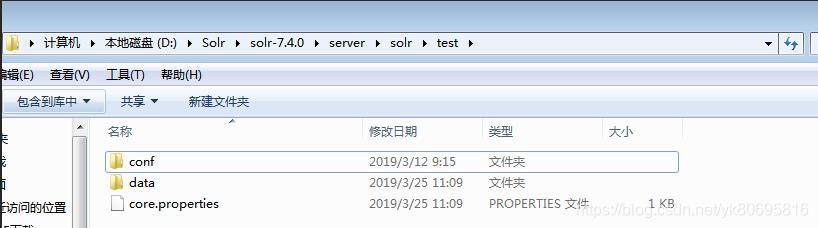
- 配置IK分词器
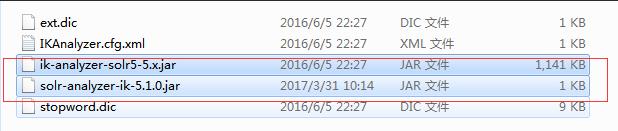
将标记的jar复制到serversolr-webappwebappWEB-INFlib
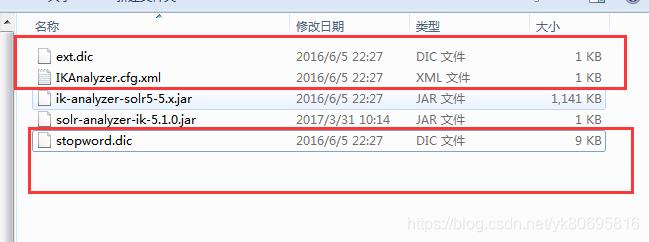
然后在serversolr-webappwebappWEB-INF文件夹下面创建一个classes文件夹将上面标记的复制进去
找到刚刚创建的Core(yangk)下面的conf打开managed-schema添加如下代码:
<fieldType name="yangk_ik" class="solr.TextField">
<analyzer type="index" useSmart="false"
class="org.wltea.analyzer.lucene.IKAnalyzer" />
<analyzer type="query" useSmart="true"
class="org.wltea.analyzer.lucene.IKAnalyzer" /></fieldType>
在这里我们发现并没有schema.xml。这是因为Solr版本中(Solr5之前),在创建core的时候,Solr会自动创建好schema.xml,但是在之后的版本中,新加入了动态更新schema功能,这个默认的schema.xml确找不到了,在Solr5以后,这个schema文件已经不是默认生成好的了,它被取了一个名字managed-schema
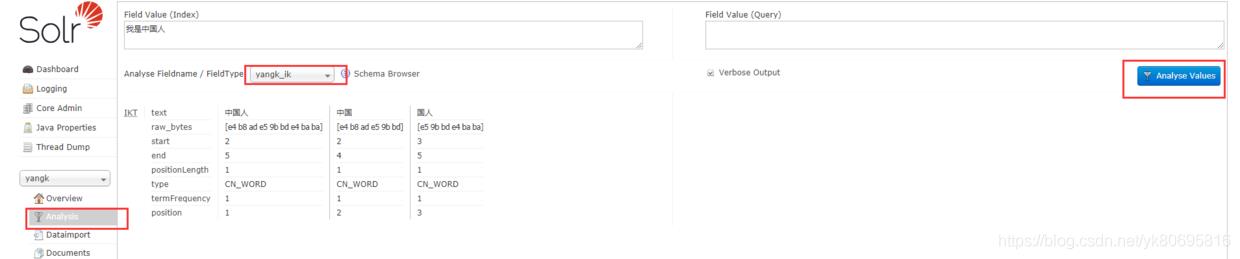
这里想要看到配置的分词器,需要重启下solr 命令:solr restart –p 端口号 重启solr服务
- Solr整合Mysql
整合mysql肯定需要Mysql的包,这里使用的是8.0的,将mysql的包放到solr-7.4.0serversolr-webappwebappWEB-INFlib下面

然后到solr-7.4.0dist文件下下面找到

将这两个包也放到solr-7.4.0serversolr-webappwebappWEB-INFlib下面
为了区分,我从新创建一个croe取名mysql,然后找到solr-7.4.0exampleexample-DIHsolrdb文件夹

将solr-7.4.0exampleexample-DIHsolrdb文件里面的内容复制到mysql文件夹里面
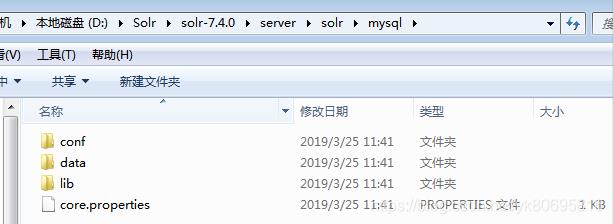
进入conf里面找到db-data-config.xml修改配置文件,改为自己的数据库信息
<dataConfig>
<dataSource driver="com.mysql.cj.jdbc.Driver" url="jdbc:mysql://localhost:3306/springboot?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC" user="root" password="root" />
<document>
<entity name="item" query="select id,name from sys_area">
<field column="id" name="id" />
<field column="name" name="name" />
</entity>
</document>
</dataConfig>
DataSource:数据库连接信息
Entity:对应数据库的数据表
Field:数据库字段,对应于solr的schema.xml中的 field 字段。其中 column 表示数据库字段名,name 表示 field 的 name。
然后在找到solrconfig.xml配置requestHandler

然后找到managed-schema,配置分词器和索引字段

注意:field节点对应db-data-import.xml中的field节点 其中他们的name属性保持一致。如果查询想使用Ik的话,可以把type属性设置为mysql_ik类型。但是因为managed-schema已经存在了id和name的field,所以我配置的时候报错了。如果managed-schema已有的就不需要配置了。只要配置没有的字段就行了。
这个时候配置成功了就可以导入索引
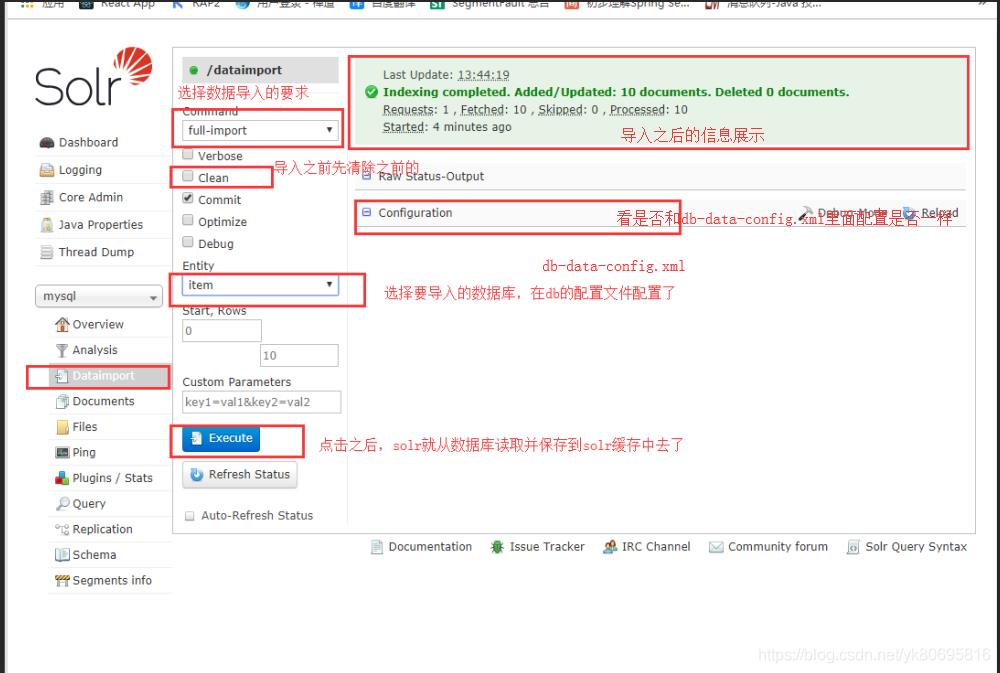
这个时候索引库就导入成功
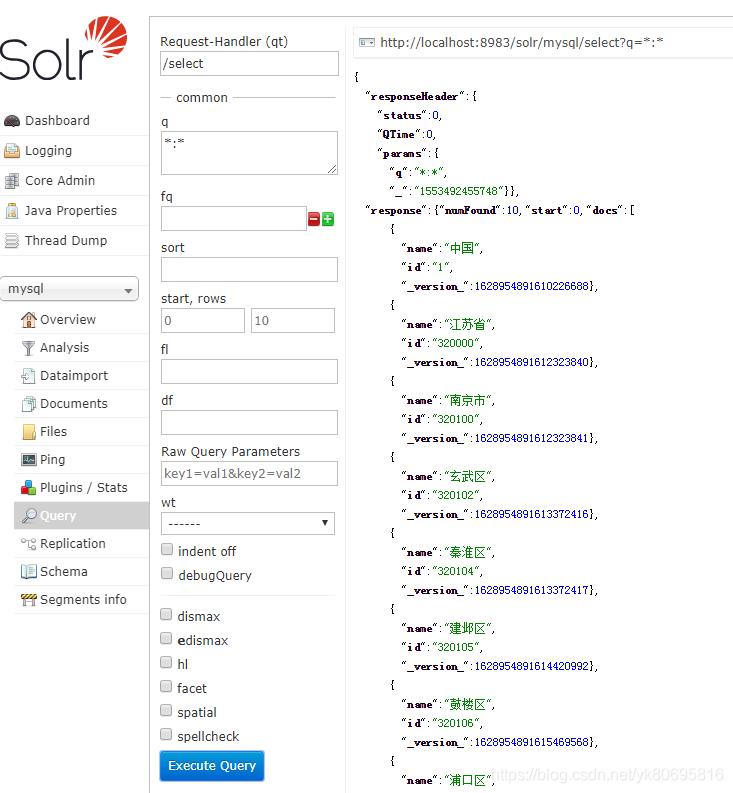
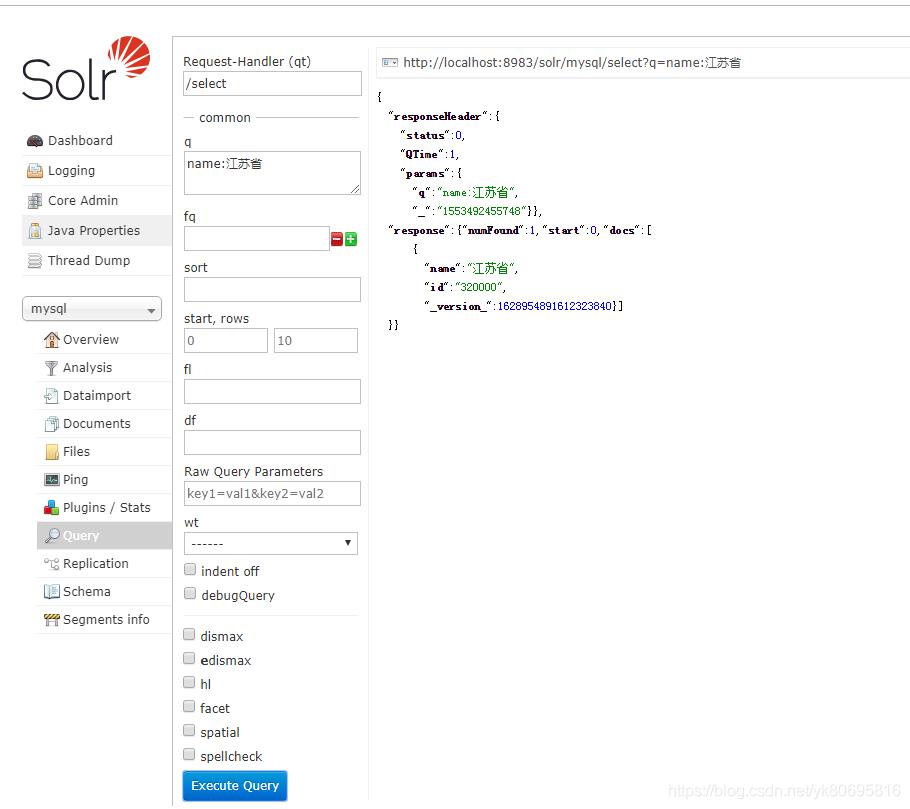
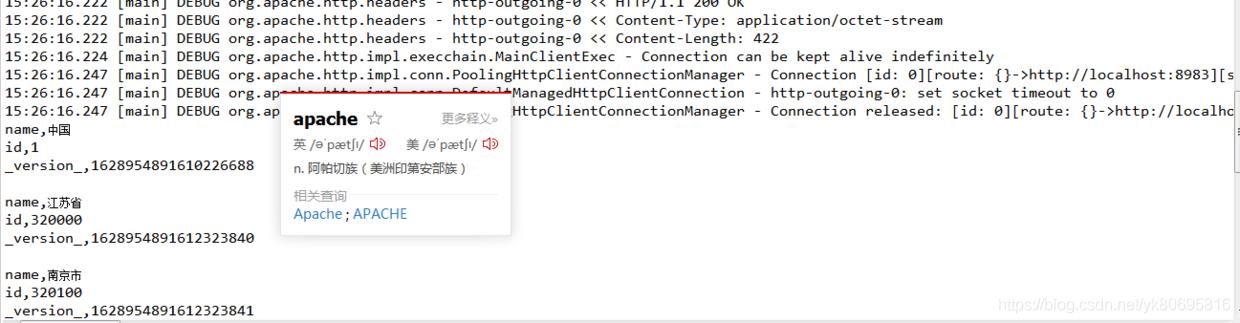
- 使用solrj
maven配置solrj的包
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-solrj</artifactId>
</dependency>
java代码
public class SolrjDrmo {
// 这个是solr索引库的连接地址
private static final String URL = "http://localhost:8983/solr/mysql";
public static void main(String[] args) throws SolrServerException, IOException {
// 创建solr客户端连接
HttpSolrClient hsc = new HttpSolrClient.Builder(URL).build();
// 创建查询对象
SolrQuery query = new SolrQuery();
query.setQuery("*:*");// 设置查询全部数据的条件
/* query.setQuery("name:江苏省"); */ // 列名:值
List<Map<String, Object>> list = getSolrQuery(hsc, query);
if (list == null) {
System.out.println("没有数据");
return ;
}
for (Map<String, Object> map : list) {
Iterator<String> it = map.keySet().iterator();
while (it.hasNext()) {
String key = it.next();
Object value = map.get(key);
System.out.println(key + "," + value);
}
System.out.println(" ");
}
}
public static List<Map<String, Object>> getSolrQuery(HttpSolrClient client, SolrQuery query)
throws SolrServerException, IOException {
List<Map<String, Object>> list = null;
// 执行查询并返回结果
QueryResponse resp = client.query(query);
SolrDocumentList results = resp.getResults();
// 获取查询到的数据总量
long numFound = results.getNumFound();
// 判断总量是否大于0,
if (numFound <= 0) {
// 如果小于0,表示未查询到任何数据,返回null
return null;
} else {
// 如果大于0,表示有数据
// 创建list存储每条数据
list = new ArrayList<>();
// 遍历结果集
for (SolrDocument doc : results) {
// 得到每条数据的map集合
Map<String, Object> map = doc.getFieldValueMap();
// 添加到list
list.add(map);
}
// 返回list集合
return list;
}
}
}
IK分词器的下载地址:https://files.cnblogs.com/files/yangk1996/ikanalyzer-solr6.5.zip
以上是关于Solr7-4的学习与使用的主要内容,如果未能解决你的问题,请参考以下文章