# IT明星不是梦 # Ceph持久化存储为k8s应用提供存储方案
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了# IT明星不是梦 # Ceph持久化存储为k8s应用提供存储方案相关的知识,希望对你有一定的参考价值。
目录:1)Ceph介绍
2)部署Ceph集群
采用版本【2020最新nautilus (stable)14.2.7】
为什么使用Ceph?
ceph其实早在2004年的时候写的第一行代码,它是到2012年才有的第一个开发版本,到2014年的时候ceph才慢慢有公司在生产上应用了,那时候一般有的版本也不是很稳定,也是进行一些二次的研发,包装成一些自己的东西,不过现在ceph的版本已经很稳定了,已经适合在生产用了,目前用的比较多的,社区影响比较好的是这个luminous版本,这个版本也是比较稳定,也是比较流行,目前也是用的比较多。
另外就是ceph和其他存储有些不一样的地方,它可扩展,有很好的性能,有稳定存储的计算模块,在没用ceph之前用的一般都是一些传统的存储或者就是商业的存储,像商业的成本一般比较高,需要一些设备或者存储到云端,另外就是拿服务器做挂载共享,这种一个是不利于横向扩展,它很难保证数据的稳定性,数据的访问速率,因为用挂载模式的话,它挂载的模式访问是比较差的,所以基于这种原因来采用ceph,目前像腾讯、乐视、新浪、国外的公司雅虎也都是用的ceph,像国内用的比较成功的x-sky这个用的也比较多,所以这个ceph已经很稳定了,目前市面的ceph人员也比较缺少。
GlusterFS和ceph的区别
分布式存储的话无疑就是横向扩展,任何一个节点挂了的话,可以不整体影响一个运行,可能一台x86服务器一些ssd和hdd的盘组合起来就可以把这个存储运行起来,(ssd固态硬盘)(hdd硬盘驱动器,常说的电脑c盘)那么分布式存储多节点多副本,横向扩展,主要成本很低,它可以把资源隔离,支持很低服务模式,块,对象,文件系统,也是随着节点增加,性能也是有所提高的,所以淘汰了很多集中式的存储,现在也是慢慢的走向分布式的存储。
Ceph架构介绍
ceph主要使用底层的rados存储,最核心的,外面封装了一个librados对文件系统对对象提供一些支持,外层有rgw、rbd、cephfs通过这些数据,将它提供给用户去使用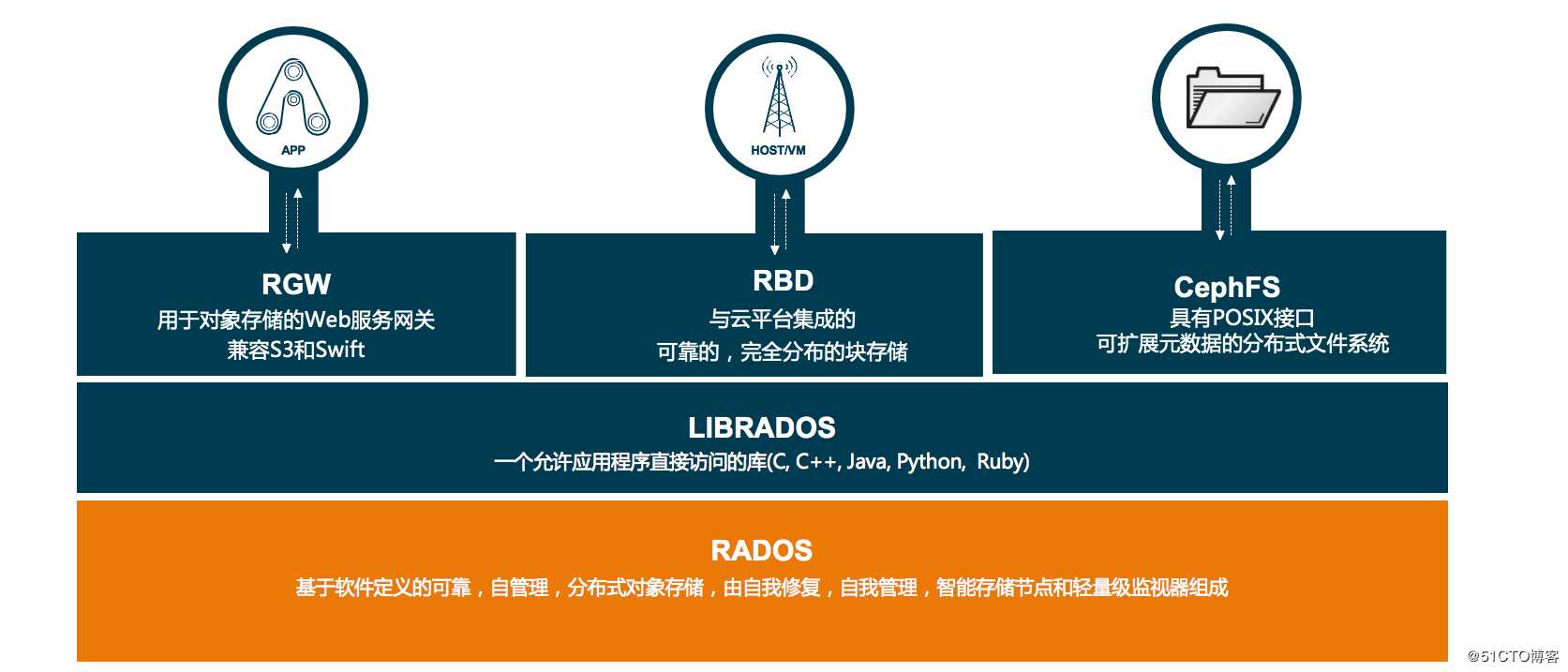
第一个rgw也就是对象存储,rbd是块存储,cephfs是文件系统存储,它的底层是rados,上层是librados这个其实就是一个开发库,librados中间还有一个封装的对象,主要和上面层进行关联,把存储空间通过软件隔离出来,然后提供给用户去使用
像这个rbd听的比较多,块存储其实就是一块磁盘,cephfs就是共享mount,相当于以前的将它释放出去,rgw可能就比较先进了,一般用的比较多的就是rgw,rdb块存储和cephfs也用的不是很多,rgw用的话可能会做一些开发。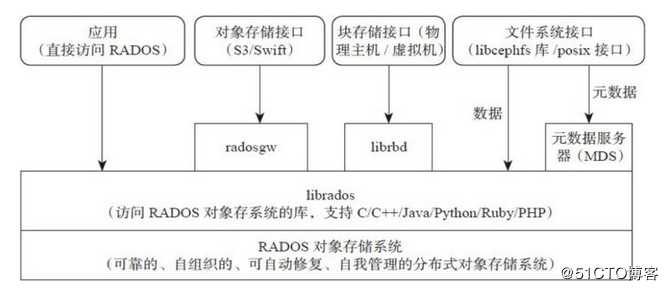
也就是块存储有个rbd,因为rados提供的这些对底层提供这些接口,我支持很多东西,你过来连接我就可以了,MDS就是我们所说的cephfs,也就是文件系统的接口,rgw就是对象存储,也就是在librados之上,提供给用户使用,因为rados是底层的存储,librados是对象的封装的,不能给用户直接使用的,如果它想使用,对象存储,块存储,文件系统存储是要和librados做交互的,那么应用也可以直接和rados之间交互,交互的时候可能就需要代码连接它的库去开发,但是一般都是通过对象存储的接口,因为那样的方式简单一些。
Ceph的设计思想
高性能:它的集群可靠性,扩展性,数据安全性,接口一致性,去中心化,基于这些设计思想有了很好的性能,它的高性能就是可以不断的横向扩展,提高数据的存储速率,还有还内部还有一个crush算法,通过crush算法将数据平均分配到每个节点上,其实就是拿了一张地图,访问的时候去这个地图里面去找,把这个数据拼起来获取到,可以很均衡的分配到每一台机器上,而且还支持很多PB级的数据,其实很多公司已经做到了百PB级的数据,也就是很多的节点很多的物理机组成的集群。
高扩展性:去中心化,也就是分布式存储,还有它的随着节点的增长,而它线性的增长它的性能
特性丰富:支持三种存储接口:块,文件,对象,而且还可以自己去开发对接很多东西。
还有就是它的扩展性安全性,它是怎么保证数据的安全性呢?
在ceph的每个用户,都有独立的空间,就是你要访问数据的话,你要有密钥,才能访问你想要的数据,然后每个数据都是隔离它的,之前集中式的存储是很难做到的。
高性能
a. 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高
b.考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等
c. 能够支持上千个存储节点的规模,支持TB到PB级的数据
高可扩展性
a. 去中心化
b. 扩展灵活
c. 随着节点增加而线性增长
特性丰富
a. 支持三种存储接口:块存储、文件存储、对象存储
b. 支持自定义接口,支持多种语言驱动
Ceph核心概念
RADOS
全称Reliable Autonomic Distributed Object Store,即可靠的、自动化的、分布式对象存储系统。RADOS是Ceph集群的精华,用户实现数据分配、Failover等集群操作。
rados主要是可靠的,自动化的,分布式对象存储系统,数据主要是通过rados来存储的,给用户来实现分配,包含一个故障的切换,它的自我修复,ceph某个节点osd或者某个盘块了之后,进行数据的重新分布,它会把坏盘的数据迁移走,加个新盘把数据迁移过来,都是通过rados来实现的,所以这是最核心的部分,我们做操作的时候基本不会对这个东西做任何改变。
Librados
Rados提供库,因为RADOS是协议很难直接访问,因此上层的RBD、RGW和CephFS都是通过librados访问的,目前提供php、Ruby、Java、Python、C和C++支持。
librados是一个允许应用程序直接访问的库(c++,java,python,ruby)它是rgw、rbd、cephfs都是通过librados来访问的,只有通过librados才能访问到底层的存储。
Crush
Crush算法是Ceph的两大创新之一,通过Crush算法的寻址操作,Ceph得以摒弃了传统的集中式存储元数据寻址方案。而Crush算法在一致性哈希基础上很好的考虑了容灾域的隔离,使得Ceph能够实现各类负载的副本放置规则,例如跨机房、机架感知等。同时,Crush算法有相当强大的扩展性,理论上可以支持数千个存储节点,这为Ceph在大规模云环境中的应用提供了先天的便利。
crush算法是ceph的创新之一吧,就是因为有这个东西,所以才能实现很快的寻址,很快的找到数据,其实当ceph达到一定程度的时候,就是传统的寻址方案会有一定的瓶颈,也就是ceph的算法一致性hash的容灾性隔离,可以把ceph存储方案的寻址理解成数据库中的索引,比如有了索引之后,去查数据很快,我有一个地方存放在哪里,crush就是做这个用的,通过这些算法来提供数据的检索能力,扩展快,包含扩展到几千个节点的时候,也能很快的去寻找到数据,这就是crush算法。
Pool
Pool是存储对象的逻辑分区,它规定了数据冗余的类型和对应的副本分布策略,支持两种类型:副本(replicated)和 纠删码( Erasure Code)
pool是存储里面一个逻辑的概念,就是它规定了数据的冗余还有副本,默认ceph是三个副本,也就是一个数据要存三份,为什么呢,因为前面说的强的一致性,保证数据一致性的话,要对这三份数据做比较,如果任何数据的md5值有变化的时候,集群就报错,数据不一致有问题,强一致性,三副本也就是这一个策略,也是保证数据的冗余性,pool是一个逻辑概念,pool里面会有pg
PG
PG( placement group)是一个放置策略组,它是对象的集合,该集合里的所有对象都具有相同的放置策略,简单点说就是相同PG内的对象都会放到相同的硬盘上,PG是 ceph的逻辑概念,服务端数据均衡和恢复的最小粒度就是PG,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据;
为什么会有PG这个概念呢?如果没有pg的话,存储写了一份数据,比如这个数据是8M的,那在ceph存储的时候8M会分成2份,4M去存储,当数据量达到一定级别的时候,就会有很多很多的对象,那么PG来做什么,把它们这些数据均衡的分布到每个归档起来,比如一份数据三副本,可能会放到3个PG里面,那么这样的话,就保证将这些数据归置在一起,crush算法找的时候会找这些pg,pg再找这些对象,就很快,分组的概念,引进这个就是主要来分配数据,定位数据,分配数据是把多副本放到不同的pg上,pg有主有备一个对象在这个pg上是主,在另外一个节点是备,那么它很均衡把这个数据存放在每个pg里面,那就保证互相冗余,其中我们一个节点挂了,我们另一个有对象的数据,pg就是这个概念。
Object
简单来说块存储读写快,不利于共享,文件存储读写慢,利于共享。能否弄一个读写快,利 于共享的出来呢。于是就有了对象存储。最底层的存储单元,包含元数据和原始数据。
无论是rbd,还是rgw,cephfs它最终到ceph里面都是用一个对象来存储的,那么一个4M的文件,就是存储一个4M的对象,8M就是两个4M的文件,虽然存进去是一个比较大的文件,但是它会帮你拆分很多小份,因为这样的话,它会提供很高的效率,ceph还有一点,就是快,快一点在于以前我们的文件系统一个文件的数据和原数据都是放在一起存储的,然后存储先将这些块打散写进磁盘里面,这个过程中就是没有原数据,把所有东西都放在一起,然后每个块要读取哪个块,这样的按顺序来找,这样的话很很慢,其实就是相当于100个速度的读写,但是只读到了其中一个块,才知道下一个块在哪里,按顺序把这些都找到,跟传统的文件系统不一样的地方就是它把原数据独立出来了,它把数据的原数据单独存放起来,这样的话便于包含原数据,包含了它的一些对象属性,创建时间、大小等等这些,数据是单独存放起来的,那么当用户访问的时候会先访问原数据,那么就知道它的名字,位置,属性,然后这样的话在存储里去找,这样久很快了,把原数据独立出来了,这也就是和传统文件系统的区别。
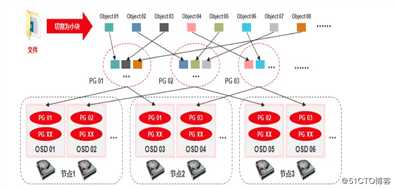
上面这张图,资源的划分,文件存放进去会切割为很多小块,object01-object08很多的小块,然后放在不同的PG里面,然后PG会落到每个节点上,最终存放到OSD上,最小一个对象是4M,文件有多大,就拆分多少个4M,然后存放到PG里面,那么这些PG有主有备,那么用户访问的也是主。
ceph对象元数据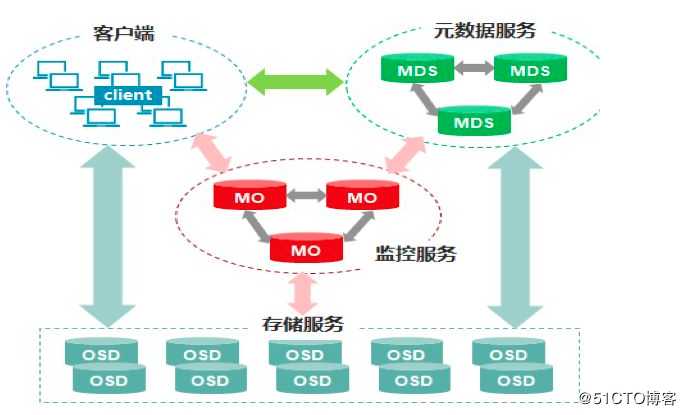
那么客户端会访问元数据服务器,访问到元数据之后,然后去monitor拿一个crush map,再去OSD寻找这个数据
Ceph核心组件
OSD
OSD是负责物理存储的进程,一般配置成和磁盘一一对应,一块磁盘启动一个OSD进程。主要功能是存储数据、复制数据、平衡数据、恢复数据,以及与其它OSD间进行心跳检查,负责响应客户端请求返回具体数据的进程等;
Pool、PG和OSD的关系:
一个Pool里有很多PG;
一个PG里包含一堆对象,一个对象只能属于一个PG,虽然是多副本的,但是每个副本都是一个单独的对象。
PG有主从之分,一个PG分布在不同的OSD上(针对三副本类型) ,PG会放在不同的OSD上
OSD是物理存储的进程,一般一个盘对应一个OSD,一个磁盘启动一个进程,这个进程对应一个OSD,它主要的功能就是存储数据、复制数据、平衡数据、恢复数据,来完成与其他OSD之间的心跳检查,还负责响应客户端请求返回具体数据的进程,就是ceph拿数据中间不通过任何进程,不同的软件,用户是和OSD之间交互的,就是ceph虽然可以从OSD去获取数据,但是它是怎么知道拿的数据在什么位置,有多少块是怎么组合起来的呢?那么它是从monitor拿的crush map,那么这个map里面有它想要的东西,位置,大小,元数据,拿到这个东西之后,再去拿OSD,这个就是用户想拿到的东西。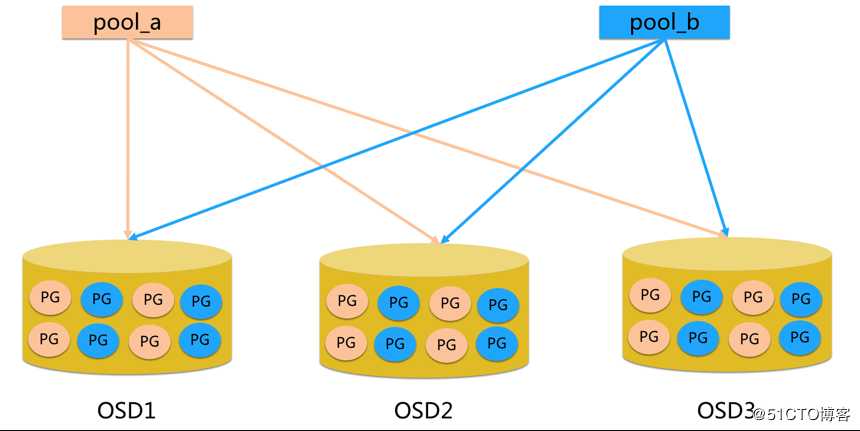
那么这就是三个OSD,两个pool,每个pool放在不同的ODS上,这就是pool和OSD之间的关系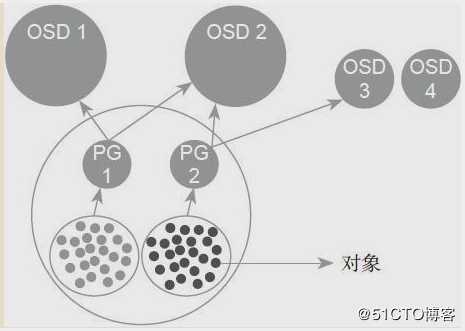
对象都放PG里面,然后PG又放在OSD里面
Monitor
一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,用来保存OSD的元数据。负责坚实整个Ceph集群运行的Map视图(如OSD Map、Monitor Map、PG Map和CRUSH Map),维护集群的健康状态,维护展示集群状态的各种图表,管理集群客户端认证与授权;
monitor其实是ceph存储的大脑,一个ceph可以有多个monitor,多个monitor可以组成一个集群,主要是通过paxos来同步数据,用来保存OSD的元数据,map里面存放了很多的数据的信息,每个组件,比如OSD配置的有变化了,它会告诉monitor有哪些变化,它就可以想象成一个人的大脑,掌管着所有的信息,比如OSD挂了,它会汇报,那么monitor也会实时的去检测下面这些组件的健康状态,如果这些组件没有上报这些组件的健康状态,那么这个monitor是不健康的,monitor主要是这个作用,ceph是分布式存储,包括它们下面的组件也是分布式的,生产上一般也是建议3个monitor,奇数的monitor来组成一个组件做高可用,任何一个monitor挂了的话,也不会影响一个的使用,这就是分布式存储架构的概念
MDS
MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。负责保存文件系统的元数据,管理目录结构。对象存储和块设备存储不需要元数据服务;
mds也就是cephfs的元数据,文件系统的共享方式,那么它们的数据都是放在mds里面的,负责保存文件系统的元数据,管理目录结构,如果不用cephfs,mds是可以不用部署的,只要用cephfs的时候才需要这个mds,mds也是可以做成高可用的,主备模式,新版本可以做成负载均衡的模式
Mgr
ceph 官方开发了 ceph-mgr,主要目标实现 ceph 集群的管理,为外界提供统一的入口。例如cephmetrics、zabbix、calamari、promethus
为什么会有这个mgr,在luminous版本之前,用的zabbix、calamari(团队制监控面板)的比如ceph用它的metrics,prometheus,那么想用这些东西的话,可能需要下载一些软件,安装上,或者自己去开发去写,那么这样的话就很不方便,那么mgr呢,主要目标实现ceph集群的关联,为外界提供统一的入口,就是把这些边缘的东西,都以插件的形式存放在存储里,那么用mgr的时候ceph mgr module开启关闭,就很方便的去使用,其实就是将这个东西集中的管理到一起,mgr也可以做成分布式的,mgr也可以做成分布式的,但它只是主备的模式,当它挂了的话,是不影响集群的使用的,只会影响用ceph监控的控制台prometheus之类的。
RGW
RGW全称RADOS gateway,是Ceph对外提供的对象存储服务,接口与S3和Swift兼容。
就是对象存储,对象存储比如使用rbd写进一个文件,是通过librados切成对象再存放到文件系统里,这种效率是多了一层,对象存储是直接做开发要rgw接口,用对象的形式写到存储里,这就少了一层,对文件做了个转换,librados和cephfs都是对写文件做了个转换,通过cephfs和rbd在文件系统写文件一样,如果通过rgw写的话可以直接对接接口,它支持s3和swift接口,通过这个接口把对象直接写入到osd存储里面,这个rgw就很快,肯定要比rbd和cephfs要快,所以很多公司都在用对象存储,对于读写一些场景比较高的话,那么建议使用对象存储,像rbd和cephfs开发起来也不是很方便,像mysql只能用rbd,像cephfs对一些读写场景不高的对这些对一些支持,如果对性能比较高的就要用rgw。
Admin
Ceph常用管理接口通常都是命令行工具,如rados、ceph、rbd等命令,另外Ceph还有可以有一个专用的管理节点,在此节点上面部署专用的管理工具来实现近乎集群的一些管理工作,如集群部署,集群组件管理等。
admin就是一个管理的接口,去执行rados、ceph、rbd等命令,去执行rados就要和rados去交换,admin这个接口就是做这个的管理的,另外ceph还有一个专用的管理节点,它可以管理集群的部署,集群的组件。
Ceph三种存储类型
1、 块存储(RBD)
优点:
通过Raid与LVM等手段,对数据提供了保护;
多块廉价的硬盘组合起来,提高容量;
多块磁盘组合出来的逻辑盘,提升读写效率;
缺点:
采用SAN架构组网时,光纤交换机,造价成本高;
主机之间无法共享数据;
使用场景
docker容器、虚拟机磁盘存储分配;
日志存储;
文件存储;
块存储其实就是模拟磁盘,通过raid与lvm手段进行对数据的一些保护,其实ceph集群如果想用rbd的板块,ceph会通过软件给你一个块,用户可以把这个块拿出来之后,对这个块做格式化,或者直接在板块去写,像vmware的底层都是往块里面去写,块的读写速度要比文件系统要高,块主要是多块廉价的硬盘组合起来的,多块磁盘组合出来的逻辑盘提升读写效率,这就是以一个成本的角度去考虑
缺点呢就是就是成本高主机之间无法共享数据
为什么会有cephfs就是rbd不支持直接的数据共享,如果数据共享的话,把rbd格式化,然后mount到本地,然后再通过服务器exports,直接把格式化好的盘释放给用户,一般它的使用场景就是pod,通过pv,pvc的形式把它挂上,或者日志存储,文件存储,就是局限于一些场景,对块支持的一些场景,块比文件系统优势读写速度要比文件系统要快。
2、文件存储(CephFS)
优点:
造价低,随便一台机器就可以了;
方便文件共享;
缺点:
读写速率低;
传输速率慢;
使用场景
日志存储;
FTP、NFS;
其它有目录结构的文件存储
这个就是造价低,方便文件共享,缺点就是读写速率比较低,传输速率也比较慢,使用场景一般也是使用NFS,日志存储,那么文件存储其实就是我们直接mount,在客户端用mount命令,存储上的一块空间,mount到本地,这就是cephfs的优点,要是块的话需要做一些出来才能mount到本地。
3、对象存储(Object)(适合更新变动较少的数据)
优点:
具备块存储的读写高速;
具备文件存储的共享等特性;
使用场景
图片存储;
视频存储;
对象存储因为它可以直接与底层交互,直接写进去就是对象,不用做任何处理,所以它会很快,那么公司要用对象存储的话,可能会用到一些开发成本,比如可能会调一些s3的接口,通过python拉取一些数据,写一些数据,对集群的开发做一些备份,做一些监控,都是通过这个s3这个接口,主要是快,一个是功能多,开发出来方便易用,这里面会有一些开发成本。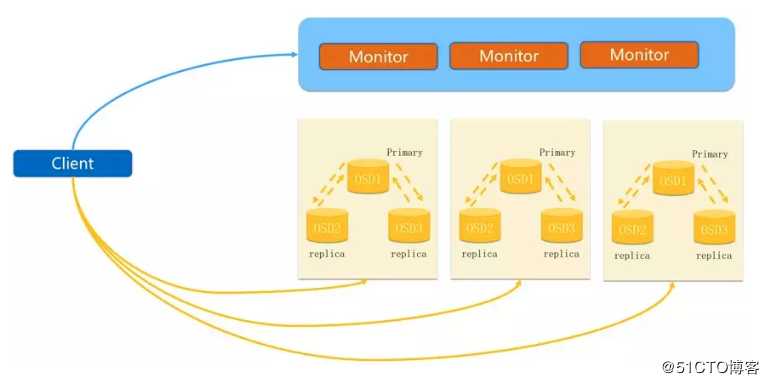
这个client去map拿数据,然后它会去下面这个OSD去找文件,那么这个OSD有主有副本,只有主才会提供服务,副本是不做任何改动的,ssd和hdd的盘怎么分配,(ssd即固态硬盘,hdd即机械硬盘)你在集群里要设置盘符,ceph命令去看的时候会有ssd和hdd的标识,通过这个标识它会把这个主副本frimary放到性能比较好的盘上,把其他副本放到其他盘上,也可以手动的去调节这个权重,让数据分布的概念股均匀一些。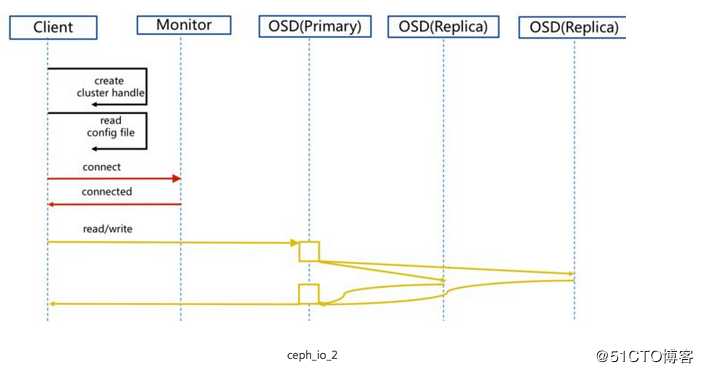
Client会去monitor去建立连接,这个建立连接就是先拿到crush map,然后如果读数据的话,直接去副本去读数据就可以了,读完数据就直接返回一个数据,如果client去集群写数据的话,那么ceph有强一致性,就是写数据的时候主副本写完了,这个数据是不能读的,只有等主副本让其他副本把这个数据同步完之后,它们三副本之间会有通信,三个接口通信完成确认数据一致之后才可以去读取,这也就是一个强一致的由来。
部署ceph集群
一、Ceph版本选择
Ceph版本来源介绍
Ceph 社区最新版本是 14,而 Ceph 12 是市面用的最广的稳定版本。
第一个 Ceph 版本是 0.1 ,要回溯到 2008 年 1 月。多年来,版本号方案一直没变,直到 2015 年 4 月 0.94.1 ( Hammer 的第一个修正版)发布后,这个一般早期做存储的公司会用到,用的比较多的早期是16年的jewel版本,为了避免 0.99 (以及 0.100 或 1.00 ?),制定了新策略。
x.0.z - 开发版(给早期测试者和勇士们)(社区提供的开发或者合作伙伴提供的开发版本)
x.1.z - 候选版(用于测试集群、高手们)(提供一些bug,做一些测试)
x.2.z - 稳定、修正版(给用户们)(真正给我们用的都是这个x.2.z版本稳定、修正版也就是发布出来玩吗可以是直接在生产去用的)
x 将从 9 算起,它代表 Infernalis ( I 是第九个字母),这样第九个发布周期的第一个开发版就是 9.0.0 ;后续的开发版依次是 9.0.1 、 9.0.2 等等。
现在一般公司用的比较多的是luminous版本,也已经2年的时间了
一般呢,生产用的比较多的还是luminous版本,12.2.12
ceph官方网站:https://ceph.io
ceph官方文档网站:https://docs.ceph.com/docs/master/
ceph中文文档网站:http://docs.ceph.org.cnLuminous新版本特性
Bluestore
ceph-osd的新后端存储BlueStore已经稳定,是新创建的OSD的默认设置。
BlueStore通过直接管理物理HDD或SSD而不使用诸如XFS的中间文件系统,来管理每个OSD存储的数据,这提供了更大的性能和功能。
BlueStore支持Ceph存储的所有的完整的数据和元数据校验。
BlueStore内嵌支持使用zlib,snappy或LZ4进行压缩。(Ceph还支持zstd进行RGW压缩,但由于性能原因,不为BlueStore推荐使用zstd)
集群的总体可扩展性有所提高。我们已经成功测试了多达10,000个OSD的集群。
ceph-mgr
ceph-mgr是一个新的后台进程,这是任何Ceph部署的必须部分。虽然当ceph-mgr停止时,IO可以继续,但是度量不会刷新,并且某些与度量相关的请求(例如,ceph df)可能会被阻止。我们建议您多部署ceph-mgr的几个实例来实现可靠性。
ceph-mgr守护进程daemon包括基于REST的API管理。注:API仍然是实验性质的,目前有一些限制,但未来会成为API管理的基础。
ceph-mgr还包括一个Prometheus插件。
ceph-mgr现在有一个Zabbix插件。使用zabbix_sender,它可以将集群故障事件发送到Zabbix Server主机。这样可以方便地监视Ceph群集的状态,并在发生故障时发送通知。
之前的版本还有jewel用的都是filestore,现在是bluestore,那么什么是filestore,什么是bluestore,也就是filestore传进来的是一个文件,存储进行一个处理,可以这么说filestore是一个磁盘,格式化之后再往里面写,相当于一个文件了,写完文件之后,filestore再把这个文件转换成对象写到rados里面,filestore是多了一层,可能效率会有点低。
那么新版本用的是bluestore,可以直接管理物理盘,就是插上这个盘之后不需任何处理,直接ceph-deploy create一下就变成一个osd存储空间了,bluestore的特性呢可以直接管理硬盘,管理裸盘,存放进去的就存放到osd这个进程里
而且bluestore还支持压缩,使用snappy、zlib或lz4支持内联压缩,压缩完之后实际存到文件大小是有变化的,查看一个对象大小的时候,会有一定的缩小,luminous先版本特性呢比之前的扩展性提高了,据说可以达到1万个osd,osd的概念是我们用100个osd,10000个ods
还有一个ceph-mgr,这个是管理这个插件,管理这个API,它是一个后台进程,然后通过多个mgr实现高可用
二、安装前准备
安装要求
最少三台Centos7系统用于部署Ceph集群。硬件配置:2C4G,另外每台机器最少挂载三块硬盘(每块盘5G-20G)
cephnode01 192.168.1.2
cephnode02 192.168.1.8
cephnode03 192.168.1.11 内网yum源服务器,硬件配置2C4G cephyumresource01 192.168.1.14
环境准备(在Ceph三台机器上操作)
(1)关闭防火墙:
systemctl stop firewalld
systemctl disable firewalld(2)关闭selinux:
sed -i ‘s/enforcing/disabled/‘ /etc/selinux/config
setenforce 0(3)关闭NetworkManagersystemctl disable NetworkManager && systemctl stop NetworkManager
(4)添加主机名与IP对应关系:
vim /etc/hosts
192.168.1.2 cephnode01
192.168.1.8 cephnode02
192.168.1.11 cephnode03(5)设置主机名:
hostnamectl set-hostname cephnode01
hostnamectl set-hostname cephnode02
hostnamectl set-hostname cephnode03(6)同步网络时间和修改时区
systemctl restart chronyd.service && systemctl enable chronyd.service
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime(7)设置文件描述符
echo "ulimit -SHn 102400" >> /etc/rc.local
cat >> /etc/security/limits.conf << EOF
* soft nofile 65535
* hard nofile 65535
EOF(8)内核参数优化
cat >> /etc/sysctl.conf << EOF
kernel.pid_max = 4194303
echo "vm.swappiness = 0" /etc/sysctl.conf
EOF
sysctl -p(9)在cephnode01上配置免密登录到cephnode02、cephnode03
ssh-keygen
ssh-copy-id root@cephnode02
ssh-copy-id root@cephnode03(10)read_ahead,通过数据预读并且记载到随机访问内存方式提高磁盘读操作,相当于把经常读的数据存到缓存一份。echo "8192" > /sys/block/sda/queue/read_ahead_kb
(11) I/O Scheduler,SSD要用noop,SATA/SAS使用deadline,这个其实就是磁盘一种调度文件方式,ssd用noop,因为ssd的读写速度比较快,就给把循环读的方式关掉了,sata用deadline,也是一种调度方式SATA的优势:支持热插拔 ,传输速度快,执行效率高,同样这一块是操作系统方面的优化方案,所以主要的作用也是用于优化磁盘性能,提供读写速率
echo "deadline" >/sys/block/sd[x]/queue/scheduler
echo "noop" >/sys/block/sd[x]/queue/scheduler三、安装内网yum源
1、安装httpd、createrepo和epel源,这里相当于自己搭建一个服务器网站,使用httpd,将所需要依赖的文件放在我们的网站根目录下,因为在新版nautilus需要很多的依赖包,我们更新yum源的时候就能读取到我们的依赖,就不用每台去下载这些文件了。
yum install httpd createrepo epel-release -y
systemctl start httpd2、编辑yum源文件
[root@cephyumresource01 ~]# more /etc/yum.repos.d/ceph.repo
[Ceph]
name=Ceph packages for $basearch
baseurl=http://mirrors.163.com/ceph/rpm-nautilus/el7/$basearch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http://mirrors.163.com/ceph/rpm-nautilus/el7/noarch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
[ceph-source]
name=Ceph source packages
baseurl=http://mirrors.163.com/ceph/rpm-nautilus/el7/SRPMS
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc3、下载Ceph安装包,下载ceph依赖文件,由于依赖文件比较多,下载也会耽误时间,部署找这些依赖包就耽搁很多的时间,所以这里我打成包,需要的找我要
已托管百度云盘:链接:https://pan.baidu.com/s/1vOhcdN09tL1i222Jhy-8mg
使用我打包好的文件mkdir -pv /var/www/html/
将ceph的包放进这个目录去解压
4、更新yum源createrepo --update /var/www/html/ceph/rpm-nautilus
四、安装Ceph集群
1、编辑内网yum源,将yum源同步到其它节点并提前做好yum makecache
如果makecache不了,那么就去找相关的包进行去下载
使用sed -i ‘s/192.168.1.14/xxxxx/‘g /etc/yum.repos.d/ceph.repo将自己的yum内网地址放进去,执行makecahe,少包的对应网站去下载
[root@cephnode01 ~]# cat /etc/yum.repos.d/ceph.repo
[Ceph]
name=Ceph packages for $basearch
baseurl=http://192.168.1.14/ceph/rpm-nautilus/el7/$basearch
gpgcheck=0
priority=1
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http://192.168.1.14/ceph/rpm-nautilus/el7/noarch
gpgcheck=0
priority=1
[ceph-source]
name=Ceph source packages
baseurl=http://192.168.1.14/ceph/rpm-nautilus/el7/SRPMS
gpgcheck=0
priority=12、安装ceph-deploy(确认ceph-deploy版本是否为2.0.1),官方提供部署软件的一个工具,这个在一个节点安装就可以,作为管理的工具yum install -y ceph-deploy
创建一个my-ceph目录,所有命令在此目录下进行(文件位置和名字可以随意),这个也是在一个节点创建
mkdir /my-cluster
cd /my-cluster创建一个Ceph集群,new创建一个新的
ceph-deploy new cephnode01 cephnode02 cephnode03
[ceph_deploy.new][DEBUG ] Resolving host cephnode02
[ceph_deploy.new][DEBUG ] Monitor cephnode02 at 192.168.1.8
[ceph_deploy.new][DEBUG ] Monitor initial members are [‘cephnode01, ‘cephnode02, ‘cephnode03‘]
[ceph_deploy.new][DEBUG ] Monitor addrs are [‘192.168.1.2, ‘192.168.1.8‘, ‘192.168.1.11‘]
[ceph_deploy.new][DEBUG ] Creating a random mon key...
[ceph_deploy.new][DEBUG ] Writing monitor keyring to ceph.mon.keyring...
[ceph_deploy.new][DEBUG ] Writing initial config to ceph.conf...
这个显示的是里面的成员,下面是monitor的地址
[ceph_deploy.new][DEBUG ] Monitor initial members are [‘cephnode01, ‘cephnode02, ‘cephnode03‘]
[ceph_deploy.new][DEBUG ] Monitor addrs are [‘192.168.1.2, ‘192.168.1.8‘, ‘192.168.1.11‘]创建好之后可以看到我们默认的配置文件
[root@cephnode01 my-cluster]# more ceph.conf
[global]
fsid = e56c3ad6-c2f9-40e6-9c87-9891b3d9a418 集群编号
mon_initial_members = cephnode01, cephnode02, cephnode03 mon主机名名称
mon_host = 192.168.1.2,192.168.1.8,192.168.1.11 mon地址
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx5、安装Ceph软件(每个节点执行)
yum -y install epel-release
yum install -y ceph可以看到最新版nautilus版本
ceph -v
ceph version 14.2.7 (3d58626ebeec02d8385a4cefb92c6cbc3a45bfe8) nautilus (stable)执行安装完ceph,会在默认的目录下生成配置文件,还会将一些基础的配置都写进去
6、生成monitor检测集群所使用的的秘钥,这个组件是使用密钥来通信的,包括组件的心跳检测,通过密钥来获取文件,生成秘钥,就是所有的rgw,mgr,都是拿这个秘钥进行交互的,安装的时候就会把这个秘钥推送下去,
ceph-deploy mon create-initial 将部署监控中定义“mon”,等到它们形成之后然后通过gatherkeys,7、沿着过程报告监控状态
安装Ceph Client,方便执行一些管理命令,执行这布也主要是让你在ceph上执行一些命令,如果不写进去的话,它不会认为这是一个集群的
ceph-deploy admin cephnode01 cephnode02 cephnode03
8、执行完可以看到在其他的节点已经写入了,包含了管理员的秘钥,以及配置文件都推送过来了
[root@cephnode02 ceph]# ls
ceph.client.admin.keyring ceph.conf rbdmap tmpDWFr_S9、配置mgr,用于管理集群ceph-deploy mgr create cephnode01 cephnode02 cephnode03
10、部署rgw,这个使用对象存储的时候才会用到,这个rgw可以放在多个机器上,一般生产环境都是装在多个机器上,然后拿nginx做负载均衡
yum install -y ceph-radosgw
ceph-deploy rgw create cephnode01 加入到集群里11、部署MDS(CephFS)ceph-deploy mds create cephnode01 cephnode02 cephnode03
12、添加osd。平衡之后,那么这个ceph集群就安装完了
我这个机器就加了三个盘
[root@cephnode01 my-cluster]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 40G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 39G 0 part
├─centos-root 253:0 0 35.1G 0 lvm /
└─centos-swap 253:1 0 3.9G 0 lvm [SWAP]
sdd 8:16 0 20G 0 disk
sde 8:32 0 20
sdf 8:80 0 20G 0 diskG 0 disk
sr0 11:0 1 4.2G 0 rom /run/media/root/CentOS 7 x86_64这里根据自己的设备去添加,如果遇到添加磁盘之后fdisk -l 或者lsblk发现没有磁盘
可以通过2个办法去解决,不用关机
1)查看主机总线号
[root@cephnode01 my-cluster]# ls /sys/class/scsi_host
host0 host1 host22)重新扫描总线scsi设备
[root@cephnode02 ceph]# echo "- - -" > /sys/class/scsi_host/host0/scan
[root@cephnode02 ceph]# echo "- - -" > /sys/class/scsi_host/host1/scan
[root@cephnode02 ceph]# echo "- - -" > /sys/class/scsi_host/host2/scan
................................................................................................host10/scan这个只在cephnode01操作就可以,直接将盘加入上
ceph-deploy osd create --data /dev/sdb cephnode01
ceph-deploy osd create --data /dev/sdb cephnode02
ceph-deploy osd create --data /dev/sdb cephnode03
ceph-deploy osd create --data /dev/sdc cephnode01
ceph-deploy osd create --data /dev/sdc cephnode02
ceph-deploy osd create --data /dev/sdc cephnode03
ceph-deploy osd create --data /dev/sdd cephnode01
ceph-deploy osd create --data /dev/sdd cephnode02
ceph-deploy osd create --data /dev/sdd cephnode0313、加完之后可以通过ceph osd tree查看到添加的盘
[root@cephnode01 my-cluster]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.01859 root default
-3 0.01859 host cephnode01
0 hdd 0.01859 osd.0 up 1.00000 1.00000 五、Ceph集群维护命令小结
1、查看集群状态
[root@cephnode01 my-cluster]# ceph -s
cluster:
id: e56c3ad6-c2f9-40e6-9c87-9891b3d9a418
health: HEALTH_WARN
Reduced data availability: 8 pgs inactive
Degraded data redundancy: 8 pgs undersized
OSD count 1 < osd_pool_default_size 3
too few PGs per OSD (8 < min 30)
services:
mon: 3 daemons, quorum cephnode01,cephnode02,cephnode03 (age 45m)
mgr: cephnode01(active, since 35m), standbys: cephnode02, cephnode03
osd: 1 osds: 1 up (since 3m), 1 in (since 3m)
data:
pools: 1 pools, 8 pgs
objects: 0 objects, 0 B
usage: 1.0 GiB used, 18 GiB / 19 GiB avail
pgs: 100.000% pgs not active
8 undersized+peered2、将三个节点都加进来可以通过tree 查看
[root@cephnode01 my-cluster]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.05576 root default
-3 0.01859 host cephnode01
0 hdd 0.01859 osd.0 up 1.00000 1.00000
-5 0.01859 host cephnode02
1 hdd 0.01859 osd.1 up 1.00000 1.00000
-7 0.01859 host cephnode03
2 hdd 0.01859 osd.2 up 1.00000 1.00000 3、将盘都加进来平衡之后就OK状态了
[root@cephnode01 my-cluster]# ceph -s
cluster:
id: e56c3ad6-c2f9-40e6-9c87-9891b3d9a418
health: HEALTH_OK
services:
mon: 3 daemons, quorum cephnode01,cephnode02,cephnode03 (age 50m)
mgr: cephnode01(active, since 41m), standbys: cephnode02, cephnode03
osd: 3 osds: 3 up (since 68s), 3 in (since 68s)
rgw: 1 daemon active (cephnode01)
data:
pools: 4 pools, 32 pgs
objects: 187 objects, 1.2 KiB
usage: 3.0 GiB used, 54 GiB / 57 GiB avail
pgs: 32 active+clean要是在生产当中,数据量比较大的时候,在加盘的时候,它会做平衡,集群通过crush算法平衡把这些pg,对象写到新盘上,它会做些运算,会把数据均衡到新加的盘上,等所有的平衡完之后,这个就能给用户正常提供访问了,它有三种状态,一种是OK,一种是WARN,
4、查看集群日志,详细信息,一般集群出现问题可以使用这条命令进行排错
[root@cephnode01 my-cluster]# ceph health detail
HEALTH_OK或者使用ceph -w,观察集群正在发生的事件
[root@cephnode01 my-cluster]# ceph -w
cluster:
id: e56c3ad6-c2f9-40e6-9c87-9891b3d9a418 集群唯一标识符
health: HEALTH_OK 集群健康状态
services:
mon: 3 daemons, quorum cephnode01,cephnode02,cephnode03 (age 64m) 监视器法定人数
mgr: cephnode01(active, since 55m), standbys: cephnode02, cephnode03
osd: 3 osds: 3 up (since 15m), 3 in (since 15m) osd状态
rgw: 1 daemon active (cephnode01)
data:
pools: 4 pools, 32 pgs
objects: 187 objects, 1.2 KiB
usage: 3.0 GiB used, 54 GiB / 57 GiB avail
pgs: 32 active+clean5、检查集群的数据用量及其存储池内的分布情况,可以使用df命令
[root@cephnode01 my-cluster]# ceph df
RAW STORAGE:
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 57 GiB 54 GiB 14 MiB 3.0 GiB 5.29
TOTAL 57 GiB 54 GiB 14 MiB 3.0 GiB 5.29
POOLS:
POOL ID STORED OBJECTS USED %USED MAX AVAIL
.rgw.root 1 1.2 KiB 4 768 KiB 0 17 GiB
default.rgw.control 2 0 B 8 0 B 0 17 GiB
default.rgw.meta 3 0 B 0 0 B 0 17 GiB
default.rgw.log 4 0 B 175 0 B 0 17 GiB 6、也可以查看osd盘的数据使用量,数据有没有平衡,可以详细列出集群每块磁盘的使用情况,包括大小、权重、使用多少空间、使用率等等
[root@cephnode01 my-cluster]# ceph osd df
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS
0 hdd 0.01859 1.00000 19 GiB 1.0 GiB 4.6 MiB 0 B 1 GiB 18 GiB 5.29 1.00 32 up
1 hdd 0.01859 1.00000 19 GiB 1.0 GiB 4.6 MiB 0 B 1 GiB 18 GiB 5.29 1.00 32 up
2 hdd 0.01859 1.00000 19 GiB 1.0 GiB 4.6 MiB 0 B 1 GiB 18 GiB 5.29 1.00 32 up
TOTAL 57 GiB 3.0 GiB 14 MiB 0 B 3 GiB 54 GiB 5.29
MIN/MAX VAR: 1.00/1.00 STDDEV: 0查看pools
[root@cephnode01 my-cluster]# ceph osd lspools
1 .rgw.root
2 default.rgw.control
3 default.rgw.meta
4 default.rgw.log查看osd的状态
[root@cephnode01 my-cluster]# ceph osd dump
epoch 34
fsid e56c3ad6-c2f9-40e6-9c87-9891b3d9a418
created 2020-03-01 17:33:06.948592
modified 2020-03-01 18:22:55.149810
flags sortbitwise,recovery_deletes,purged_snapdirs,pglog_hardlimit
crush_version 11
full_ratio 0.95
backfillfull_ratio 0.9
nearfull_ratio 0.85
require_min_compat_client jewel
min_compat_client jewel
require_osd_release nautilus查看pg状态,可以看到每天pg创建的时间,存储的大小
[root@cephnode01 my-cluster]# ceph pg dump
dumped all
version 2838
stamp 2020-03-01 19:16:43.668988
last_osdmap_epoch 0
last_pg_scan 0
[root@cephnode01 my-cluster]# ceph pg stat
32 pgs: 32 active+clean; 1.2 KiB data, 14 MiB used, 54 GiB / 57 GiB avail7、检查集群状态
ceph status 和ceph -s是一样的命令
[root@cephnode01 my-cluster]# ceph status
cluster:
id: e56c3ad6-c2f9-40e6-9c87-9891b3d9a418
health: HEALTH_OK
services:
mon: 3 daemons, quorum cephnode01,cephnode02,cephnode03 (age 82m)
mgr: cephnode01(active, since 72m), standbys: cephnode02, cephnode03
osd: 3 osds: 3 up (since 32m), 3 in (since 32m)
rgw: 1 daemon active (cephnode01)
data:
pools: 4 pools, 32 pgs
objects: 187 objects, 1.2 KiB
usage: 3.0 GiB used, 54 GiB / 57 GiB avail
pgs: 32 active+clean8、检查monitor状态
查看监视图
可以使用两条命令查看
[root@cephnode01 my-cluster]# ceph mon stat
e1: 3 mons at {cephnode01=[v2:192.168.1.2:3300/0,v1:192.168.1.2:6789/0],cephnode02=[v2:192.168.1.8:3300/0,v1:192.168.1.8:6789/0],cephnode03=[v2:192.168.1.11:3300/0,v1:192.168.1.11:6789/0]}, election epoch 8, leader 0 cephnode01, quorum 0,1,2 cephnode01,cephnode02,cephnode03
[root@cephnode01 my-cluster]# ceph mon dump
dumped monmap epoch 1
epoch 1
fsid e56c3ad6-c2f9-40e6-9c87-9891b3d9a418
last_changed 2020-03-01 17:32:48.597113
created 2020-03-01 17:32:48.597113
min_mon_release 14 (nautilus)
0: [v2:192.168.1.2:3300/0,v1:192.168.1.2:6789/0] mon.cephnode01
1: [v2:192.168.1.8:3300/0,v1:192.168.1.8:6789/0] mon.cephnode02
2: [v2:192.168.1.11:3300/0,v1:192.168.1.11:6789/0] mon.cephnode039、检查监视器的法定人数状态
[root@cephnode01 my-cluster]# ceph quorum_status
{"election_epoch":8,"quorum":[0,1,2],"quorum_names":["cephnode01","cephnode02","cephnode03"],"quorum_leader_name":"cephnode01","quorum_age":5173,"monmap":{"epoch":1,"fsid":"e56c3ad6-c2f9-40e6-9c87-9891b3d9a418","modified":"2020-03-01 17:32:48.597113","created":"2020-03-01 17:32:48.597113","min_mon_release":14,"min_mon_release_name":"nautilus","features":{"persistent":["kraken","luminous","mimic","osdmap-prune","nautilus"],"optional":[]},"mons":[{"rank":0,"name":"cephnode01","public_addrs":{"addrvec":[{"type":"v2","addr":"192.168.1.2:3300","nonce":0},{"type":"v1","addr":"192.168.1.2:6789","nonce":0}]},"addr":"192.168.1.2:6789/0","public_addr":"192.168.1.2:6789/0"},{"rank":1,"name":"cephnode02","public_addrs":{"addrvec":[{"type":"v2","addr":"192.168.1.8:3300","nonce":0},{"type":"v1","addr":"192.168.1.8:6789","nonce":0}]},"addr":"192.168.1.8:6789/0","public_addr":"192.168.1.8:6789/0"},{"rank":2,"name":"cephnode03","public_addrs":{"addrvec":[{"type":"v2","addr":"192.168.1.11:3300","nonce":0},{"type":"v1","addr":"192.168.1.11:6789","nonce":0}]},"addr":"192.168.1.11:6789/0","public_addr":"192.168.1.11:6789/0"}]}}10、mgr的状态[root@cephnode01 my-cluster]# ceph mgr dump
六、Ceph.conf 配置文件详解
默认生成的ceph.conf文件如果需要改动的话需要加一些参数
如果配置文件变化也是通过ceph-deploy进行推送
1、该配置文件采用init文件语法,#和;为注释,ceph集群在启动的时候会按照顺序加载所有的conf配置文件。 配置文件分为以下几大块配置
global:全局配置。
osd:osd专用配置,可以使用osd.N,来表示某一个OSD专用配置,N为osd的编号,如0、2、1等。
mon:mon专用配置,也可以使用mon.A来为某一个monitor节点做专用配置,其中A为该节点的名称,ceph-monitor-2、ceph-monitor-1等。使用命令 ceph mon dump可以获取节点的名称。
client:客户端专用配置2、配置文件可以从多个地方进行顺序加载,如果冲突将使用最新加载的配置,其加载顺序为。
$CEPH_CONF环境变量
-c 指定的位置
/etc/ceph/ceph.conf
~/.ceph/ceph.conf
./ceph.conf3、配置文件还可以使用一些元变量应用到配置文件,如。
$cluster:当前集群名。
$type:当前服务类型。
$id:进程的标识符。
$host:守护进程所在的主机名。
$name:值为$type.$id。4、ceph.conf详细参数
[global]#全局设置
fsid = xxxxxxxxxxxxxxx #集群标识ID
mon host = 10.0.1.1,10.0.1.2,10.0.1.3 #monitor IP 地址
auth cluster required = cephx #集群认证
auth service required = cephx #服务认证
auth client required = cephx #客户端认证
osd pool default size = 3 #最小副本数 默认是3
osd pool default min size = 1 #PG 处于 degraded 状态不影响其 IO 能力,min_size是一个PG能接受IO的最小副本数,也就是副本到1个就不能用了,副本的降级。保护数据的安全性
public network = 10.0.1.0/24 #公共网络(monitorIP段) 给用户专门的网络
cluster network = 10.0.2.0/24 #集群网络,它要和集群直接要进行数据同步,比如要提高osd节点,数据需要复制进行迁移,那么在迁移的过程中可能会需要很大的网络带宽,一般这个在公司网络里面都是万兆网,给用户用的看访问量,一般也都是万兆网,除了公共网络和集群网络之外还可以使用一个管理网络,来单独的管理这个集群池,主要用于数据进行同步的时候,传递更快一些。
max open files = 131072 #默认0#如果设置了该选项,Ceph会设置系统的max open fds ceps打开的最大文件数。
mon initial members = node1, node2, node3 #初始monitor (由创建monitor命令而定)初始化monitor,前面就是一些全局的配置
##############################################################
[mon]
mon data = /var/lib/ceph/mon/ceph-$id
mon clock drift allowed = 1 #默认值0.05#monitor间的clock drift,保证集群之间是一致的
mon osd min down reporters = 13 #默认值1#向monitor报告down的最小OSD数,最低是13个,也就是超过13个这个集群就是不能用了
mon osd down out interval = 600 #默认值300 #标记一个OSD状态为down和out之前ceph等待的秒数
##############################################################
[osd]
osd data = /var/lib/ceph/osd/ceph-$id
osd mkfs type = xfs #格式化系统类型,默认的ceph使用的就是这种模式,生产一般也是使用这个文件系统
osd max write size = 512 #默认值90 #OSD一次可写入的最大值(MB)
osd client message size cap = 2147483648 #默认值100 #客户端允许在内存中的最大数据(bytes)
osd deep scrub stride = 131072 #默认值524288 #在Deep Scrub时候允许读取的字节数(bytes)集群的健康检查,就是存放数据,它有可能会损坏,一个副本少了一个字节,那么这个md5就不一致了,scrub就是去扫描这些数据,保证这些数据是一致的,这个一般对一些元数据信息做对比,所以这里设置了允许scrbu的字节数,
osd op threads = 16 #默认值2 #并发文件系统操作数
osd disk threads = 4 #默认值1 #OSD密集型操作例如恢复和Scrubbing时的线程
osd map cache size = 1024 #默认值500 #保留OSD Map的缓存(MB)
osd map cache bl size = 128 #默认值50 #OSD进程在内存中的OSD Map缓存(MB)
osd mount options xfs = "rw,noexec,nodev,noatime,nodiratime,nobarrier" #默认值rw,noatime,inode64 #Ceph OSD xfs Mount选项
osd recovery op priority = 2 #默认值10 #恢复操作优先级,取值1-63,值越高占用资源越高
osd recovery max active = 10 #默认值15 #同一时间内活跃的恢复请求数 ,当一定量恢复比较快的时候,集群有可能就会卡住,可能写数据读数据不到,要是对这些做一些限制的话,可能会对集群的压力会小一点,有处理承载请求的能力,如果集群压力比较大,不做这些限制的话,内部不做限制的话,有可能就会卡住
osd max backfills = 4 #默认值10 #一个OSD允许的最大backfills数
osd min pg log entries = 30000 #默认值3000 #修建PGLog是保留的最大PGLog数
osd max pg log entries = 100000 #默认值10000 #修建PGLog是保留的最大PGLog数
osd mon heartbeat interval = 40 #默认值30 #OSD ping一个monitor的时间间隔(默认30s)
ms dispatch throttle bytes = 1048576000 #默认值 104857600 #等待派遣的最大消息数
objecter inflight ops = 819200 #默认值1024 #客户端流控,允许的最大未发送io请求数,超过阀值会堵塞应用io,为0表示不受限
osd op log threshold = 50 #默认值5 #一次显示多少操作的log
osd crush chooseleaf type = 0 #默认值为1 #CRUSH规则用到chooseleaf时的bucket的类型
##############################################################
[client]
rbd cache = true #默认值 true #RBD缓存
rbd cache size = 335544320 #默认值33554432 #RBD缓存大小(bytes)内存大的话可以设置大一些,内存小的话可以设置小一些,看生产服务器的配置了。
rbd cache max dirty = 134217728 #默认值25165824 #缓存为write-back时允许的最大dirty字节数(bytes),如果为0,使用write-through
rbd cache max dirty age = 30 #默认值1 #在被刷新到存储盘前dirty数据存在缓存的时间(seconds)
rbd cache writethrough until flush = false #默认值true #该选项是为了兼容linux-2.6.32之前的virtio驱动,避免因为不发送flush请求,数据不回写
#设置该参数后,librbd会以writethrough的方式执行io,直到收到第一个flush请求,才切换为writeback方式。
rbd cache max dirty object = 2 #默认值0 #最大的Object对象数,默认为0,表示通过rbd cache size计算得到,librbd默认以4MB为单位对磁盘Image进行逻辑切分
#每个chunk对象抽象为一个Object;librbd中以Object为单位来管理缓存,增大该值可以提升性能
rbd cache target dirty = 235544320 #默认值16777216 #开始执行回写过程的脏数据大小,不能超过 rbd_cache_max_dirty以上是关于# IT明星不是梦 # Ceph持久化存储为k8s应用提供存储方案的主要内容,如果未能解决你的问题,请参考以下文章