编译原理-如何使用flex和yacc工具构造一个高级计算器
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编译原理-如何使用flex和yacc工具构造一个高级计算器相关的知识,希望对你有一定的参考价值。
Flex工具的使用方法
Lex 是一种生成扫描器的工具。 Lex是Unix环境下非常著名的工具,主要功能是生成一个扫描器(Scanner)的C源码。
扫描器是一种识别文本中的词汇模式的程序。 这些词汇模式(或者常规表达式)在一种特殊的句子结构中定义。一种匹配的常规表达式可能会包含相关的动作。这一动作可能还包括返回一个标记。 当 Lex 接收到文件或文本形式的输入时,它试图将文本与常规表达式进行匹配。 它一次读入一个输入字符,直到找到一个匹配的模式。 如果能够找到一个匹配的模式,Lex 就执行相关的动作(可能包括返回一个标记)。 另一方面,如果没有可以匹配的常规表达式,将会停止进一步的处理,Lex 将显示一个错误消息。
Lex 和 C 是强耦合的。一个 .lex 文件(Lex 文件具有 .lex 的扩展名)通过 lex 公用程序来传递,并生成 C 的输出文件。这些文件被编译为词法分析器的可执行版本。
Lex程序
一个典型的Lex程序的大致结构:
declarations
%%
translation rules
%%
auxiliary procedures
分别是声明,转换规则和其它函数。%用作在单个部分之间做分隔。
字符及其含义列表:
A-Z, 0-9, a-z 构成了部分模式的字符和数字。
. 匹配任意字符,除了 \\n。
- 用来指定范围。例如:A-Z 指从 A 到 Z 之间的所有字符。
[ ] 一个字符集合。匹配括号内的 任意 字符。如果第一个字符是 ^ 那么它表示否定模式。
例如: [abC] 匹配 a, b, 和 C中的任何一个。
* 匹配 0个或者多个上述的模式。
+ 匹配 1个或者多个上述模式。
? 匹配 0个或1个上述模式。
$ 作为模式的最后一个字符匹配一行的结尾。
{ } 指出一个模式可能出现的次数。 例如: A{1,3} 表示 A 可能出现1次或3次。
\\ 用来转义元字符。同样用来覆盖字符在此表中定义的特殊意义,只取字符的本意。
^ 否定。
| 表达式间的逻辑或。
"<一些符号>" 字符的字面含义。元字符具有。
/ 向前匹配。如果在匹配的模版中的“/”后跟有后续表达式,只匹配模版中“/”前 面的部分。
如:如果输入 A01,那么在模版 A0/1 中的 A0 是匹配的。
( ) 将一系列常规表达式分组。
标记声明:
数字(number) ([0-9])+ 1个或多个数字
字符(chars) [A-Za-z] 任意字符
空格(blank) " " 一个空格
字(word) (chars)+ 1个或多个 chars
变量(variable) (字符)+(数字)*(字符)*(数字)*
值得注意的是,lex 依次尝试每一个规则,尽可能地匹配最长的输入流。如果有一些内容根本不匹配任何规则,那么 lex 将只是把它拷贝到标准输出。
Lex 编程可以分为三步:
- 以 Lex 可以理解的格式指定模式相关的动作。
- 在这一文件上运行 Lex,生成扫描器的 C 代码。
- 编译和链接 C 代码,生成可执行的扫描器。
例如,对于一下的Lex代码:
%{
#include <stdio.h>
int k = 0;
%}
%%
[0-9]+ {
k = atoi(yytext);
if(k % 6 == 0 && k % 8 == 0) {
printf("%d\\n", k);
}
}
执行:
lex prog.lex
gcc lex.yy.c -o prog -ll
然后将会得到一个可执行文件,这个可执行文件的功能是:如果输入的字符串不是数字,原样输出,如果是数字,判断是否为6和8的公倍数,若是,则输出。
其中,-ll表示链接lex的相关库文件,要想编译时不带-ll选项,就必须实现main函数和yywrap函数(return 1即可)。
Lex中,一般声明为如下形式:
%{
int wordCount = 0;
%}
chars [A-Za-z\\_\\‘\\.\\"]
numbers ([0-9])+
delim [" "\\n\\t]
whitespace {delim}+
words {chars}+模式匹配规则如下例:
{words} { wordCount++; /* increase the word count by one*/ }
{whitespace} { /* do nothing*/ }
{numbers} { /* one may want to add some processing here*/ }含义为针对不同的模式采取不同的策略(状态机)。
Lex程序的最后一段一般为C代码,为如下形式:
void main()
{
yylex(); /* start the analysis*/
// ... do some work.
}
int yywrap()
{
return 1;
}
最后一段覆盖了 C 的函数声明(有时是主函数)。注意这一段必须包括 yywrap() 函数。
在上文中的判断公倍数的例子中,省略了程序的第三段,Lex生成了默认的C风格的main()函数。
在使用Lex做文法解析时,某些特殊结构的表达式会使由表格转化的确定的自动机成指数增长,并因此造成指数级的空间和时间复杂度消耗。
Lex变量和函数
一些常用的Lex变量如下所示:
yyin FILE* 类型。 它指向 lexer 正在解析的当前文件。
yyout FILE* 类型。 它指向记录 lexer 输出的位置。 缺省情况下,yyin 和 yyout 都指向标准输入和输出。
yytext 匹配模式的文本存储在这一变量中(char*)。
yyleng 给出匹配模式的长度。
yylineno 提供当前的行数信息。 (lexer不一定支持。)
Lex函数:
yylex() 这一函数开始分析。 它由 Lex 自动生成。
yywrap() 这一函数在文件(或输入)的末尾调用。 如果函数的返回值是1,就停止解析。
因此它可以用来解析多个文件。 代码可以写在第三段,这就能够解析多个文件。
方法是使用 yyin 文件指针(见上表)指向不同的文件,直到所有的文件都被解析。
最后,yywrap() 可以返回 1 来表示解析的结束。
yyless(int n) 这一函数可以用来送回除了前 n 个字符外的所有读出标记。
yymore() 这一函数告诉 Lexer 将下一个标记附加到当前标记后。
Lex内部预定义宏:
ECHO #define ECHO fwrite(yytext, yyleng, 1, yyout) 也是未匹配字符的默认动作。
一个简单的Lex的例子:
%{
#include <stdio.h>
%}
%%
[\\n] { printf("new line\\n"); }
[0-9]+ { printf("int: %d\\n", atoi(yytext)); }
[0-9]*\\.[0-9]+ { printf("float: %f\\n", atof(yytext)); }
[a-zA-Z][a-zA-Z0-9]* { printf("var: %s\\n", yytext); }
[\\+\\-\\*\\/\\%] { printf("op: %s\\n", yytext); }
. { printf("unknown: %c\\n", yytext[0]); }
%%
Yacc
Yacc 代表 Yet Another Compiler Compiler。 Yacc 的 GNU 版叫做 Bison。它是一种工具,将任何一种编程语言的所有语法翻译成针对此种语言的 Yacc 语 法解析器。它用巴科斯范式(BNF, Backus Naur Form)来书写。按照惯例,Yacc 文件有 .y 后缀。
用 Yacc 来创建一个编译器包括四个步骤:
- 通过在语法文件上运行 Yacc 生成一个解析器。
-
说明语法:
- 编写一个 .y 的语法文件(同时说明 C 在这里要进行的动作)。
- 编写一个词法分析器来处理输入并将标记传递给解析器。 这可以使用 Lex 来完成。
- 编写一个函数,通过调用 yyparse() 来开始解析。
- 编写错误处理例程(如 yyerror())。
- 编译 Yacc 生成的代码以及其他相关的源文件。
- 将目标文件链接到适当的可执行解析器库。
Yacc程序
如同 Lex 一样, 一个 Yacc 程序也用双百分号分为三段。 它们是:声明、语法规则和 C 代码。 每两段内容之间用%%。
一个Yacc程序示例:
%{
typedef char* string;
#define YYSTYPE string
%}
%token NAME EQ AGE
%%
file: record file
| record
;
record: NAME EQ AGE {
printf("name: %s, eq: %d, age: %d\\n, $1, $2, $3);
}
;
%%
int main()
{
yyparse();
return 0;
}
int yyerror(char *msg)
{
printf("ERORR MESSAGE: %s\\n", msg);
}Lex和YACC内部工作原理
在YACC文件中,main函数调用了yyparse(),此函数由YACC替你生成的,在y.tab.c文件中。函数yyparse从yylex中读取符号/值组成的流。你可以自己编码实现这点,或者让Lex帮你完成。在我们的示例中,我们选择将此任务交给Lex。
Lex中的yylex函数从一个称作yyin的文件指针所指的文件中读取字符。如果你没有设置yyin,默认是标准输入(stdin)。输出为yyout,默认为标准输出(stdout)。
你可以在yywrap函数中修改yyin,此函数在每一个输入文件被解析完毕时被调用,它允许你打开其它的文件继续解析,如果是这样,yywarp的返回值为0。如果想结束解析文件,返回1。
每次调用yylex函数用一个整数作为返回值,表示一种符号类型,告诉YACC当前读取到的符号类型,此符号是否有值是可选的,yylval即存放了其值。
默认yylval的类型是整型(int),但是可以通过重定义YYSTYPE以对其进行重写。分词器需要取得yylval,为此必须将其定义为一个外部变量。原始YACC不会帮你做这些,因此你得将下面的内容添加到你的分词器中,就在#include<y.tab.h>下即可:
extern YYSTYPE yylval;
Bison会自动做这些工作(使用-d选项生成y.tab.h文件)。
Lex与Yacc配合
使用Lex和Yacc实现一个高级计算器
Lex代码的内容:
%{
#include <stdlib.h>
#include "test.tab.h"
extern int yyerror(const char *);
%}
%%
[" "; \\t] { }
(0(\\.[0-9]+)?)|([1-9][0-9]*(\\.[0-9]+)?) { yylval.dv = strtod(yytext,0);return NUMBER;}
[a-zA-Z] { yylval.cv = *yytext; return CHARA;}
[-+*/()^%~!=\\n] {return *yytext;}
"&" {return AND;}
"|" {return OR;}
"||" {return or;}
"&&" {return and;}
"log" {return LOG;}
"cos" {return COS;}
"sin" {return SIN;}
"tan" {return TAN;}
"++" {return PP;}
"--" {return SS;}
"<<" {return LOL;}
">>" {return LOR;}
"cot" {return COT;}
"ans" {return ANS;}
"drop" {return DROP;}
"list" {return LIST;}
"erase" {return ERASE;}
"clear" {return CLEAR;}
"help" {return HELP;}
%%
int yywrap()
{
return 1;
}
Yacc代码的内容:
%{
#define Pi 3.14159265358979
#include <stdlib.h>
#include <stdio.h>
#include <math.h>
int yylex();
int yyerror(char *);
void convert(int num ,int mode);
double vars[26]={0};
double last=0;
long var;
int i;
int flag=1;
%}
%token ANS
%token <dv> NUMBER
%token <cv> CHARA
%type <dv> expr
%type <cv> cmdline
%union
{
double dv;
char cv;
}
%token DROP HELP CLEAR LIST ERASE
%token ‘+‘ ‘-‘ ‘*‘ ‘/‘ ‘^‘ ‘%‘ ‘`‘ ‘~‘ ‘!‘ ‘=‘
%token COS SIN TAN OR AND PP SS LOR LOL COT or and
%token LOG
%left ‘=‘
%left ‘+‘ ‘-‘
%left ‘*‘ ‘/‘ ‘%‘
%left AND OR and or
%left COS SIN TAN LOG PP SS LOR LOL COT
%left ‘^‘
%left ‘~‘ ‘!‘
%right ‘(‘ ‘)‘
%%
program:
program expr ‘\\n‘ {
if(flag)
{
printf( "你的结果是:\\t=%g\\n" , $2 );
last = $2;
}
else
{printf("");}
flag=1;
}
| program cmdline ‘\\n‘
| program stat ‘\\n‘
|
;
stat :
CHARA ‘=‘ expr
{
if(islower($1))
i = $1 - ‘a‘;
else
i = $1 - ‘A‘;
vars[i] = $3;
flag =1;
}
expr :
NUMBER { $$ = $1; }
| ANS { $$ = last; }
| CHARA
{
if(islower($1))
i = $1 - ‘a‘;
else
i = $1 - ‘A‘;
$$ = vars[i];
}
| expr ‘+‘ expr { $$ = $1 + $3; }
| expr ‘-‘ expr { $$ = $1 - $3; }
| expr ‘*‘ expr { $$ = $1 * $3; }
| expr ‘/‘ expr { $$ = $1 / $3; }
| expr ‘^‘ expr { $$ = pow($1, $3);}
| ‘~‘ expr {
$$=~(int)$2;
}
| ‘!‘ expr {
if(!(int)$2)
printf("true\\n");
else
printf("false\\n");
flag=0;
}
| expr ‘%‘ expr { $$ = (int)$1 % (int)$3; }
| ‘-‘ expr { $$ = -$2; }
| ‘(‘ expr ‘)‘ { $$ = $2; }
| COS expr { $$ = cos($2 * Pi /180); }
| SIN expr { $$ = sin($2 * Pi /180); }
| TAN expr { $$ = tan($2 * Pi /180); }
| COT expr { $$ =1/sin($2 * Pi /180);}
| expr LOG expr { $$ = log($1)/log($3); }
| expr AND expr {
printf("与前的二进制($1):\\n");
convert($1,2);
printf("\\n");
printf("与前的二进制($3):\\n");
convert($3,2);
printf("\\n");
$$=(int)$1&(int)$3;
printf("结果的二进制($$):\\n");
convert($$,2);
printf("\\n");
}
| expr OR expr {
printf("或前的二进制($1):\\n");
convert($1,2);
printf("\\n");
printf("或前的二进制($3):\\n");
convert($3,2);
printf("\\n");
$$ =(int)$1|(int)$3;
printf("结果的二进制($$):\\n");
convert($$,2);
printf("\\n");
}
| expr and expr {
if( (int)$1 && (int)$3)
printf("true\\n");
else
printf("false\\n");
flag=0;
}
| expr or expr {
if( (int)$1 || (int)$3)
printf("true\\n");
else
printf("false\\n");
flag=0;
}
| expr PP { $$ =$1+1;}
| expr SS { $$ =$1-1;}
| expr LOL expr {
printf("移位前的二进制:");
convert($1,2);
printf("\\n");
$$ =(int)$1<<(int)$3;
printf("移位后的二进制:");
convert($$,2);
printf("\\n");
}
| expr LOR expr {
printf("移位前的二进制:");
convert($1,2);
printf("\\n");
$$ =(int)$1>>(int)$3;
printf("移位后的二进制:");
convert($$,2);
printf("\\n");
}
;
cmdline : DROP { exit(0);}
| CLEAR {
system("clear");
}
| LIST {
for(i=0;i<26;i++)
printf("\\t%c=%g\\n",‘a‘+i,vars[i]);
}
| ERASE { for(i=0;i<26;i++) vars[i]=0; printf("已经清空所有的寄存器的值!\\n");}
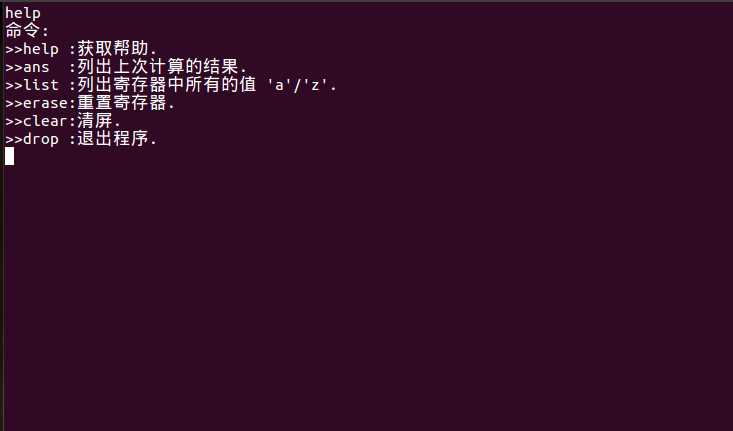
| HELP {
printf("命令:\\n");
printf(">>help :获取帮助.\\n");
printf(">>ans :列出上次计算的结果.\\n");
printf(">>list :列出寄存器中所有的值 ‘a‘/‘z‘.\\n");
printf(">>erase:重置寄存器.\\n");
printf(">>clear:清屏.\\n");
printf(">>drop :退出程序.\\n");
}
;
%%
int yyerror(char *s)
{
printf("%s\\n", s);
return 1;
}
void convert(int num ,int mode)
{
if(num/mode==0)
{
printf("\\t%d",num);return;}
else
{
convert(num/mode,mode);
printf("%d",num%mode);
}
}
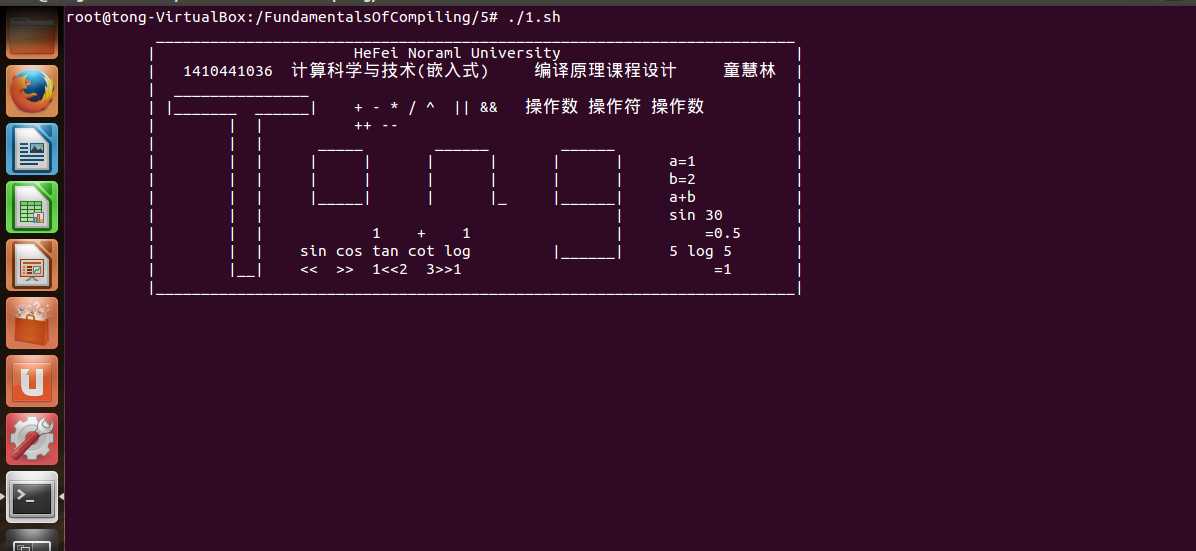
int main(int argc,char **argv)
{
printf("\\t _______________________________________________________________________ \\n");
printf("\\t | HeFei Noraml University |\\n");
printf("\\t | 1410441036 计算科学与技术(嵌入式) 编译原理课程设计 童慧林 |\\n");
printf("\\t | _______________ |\\n");
printf("\\t | |_______ ______| + - * / ^ || && 操作数 操作符 操作数 |\\n");
printf("\\t | | | ++ -- |\\n");
printf("\\t | | | _____ ______ ______ |\\n");
printf("\\t | | | | | | | | | a=1 |\\n");
printf("\\t | | | | | | | | | b=2 |\\n");
printf("\\t | | | |_____| | |_ |______| a+b |\\n");
printf("\\t | | | | sin 30 |\\n");
printf("\\t | | | 1 + 1 | =0.5 |\\n");
printf("\\t | | | sin cos tan cot log |______| 5 log 5 |\\n");
printf("\\t | |__| << >> 1<<2 3>>1 =1 |\\n");
printf("\\t |_______________________________________________________________________|\\n");
yyparse();
}
执行脚本1.sh
#!/bin/bash # bison -d test.y flex test.l gcc lex.yy.c test.tab.c -lm -o test ./test
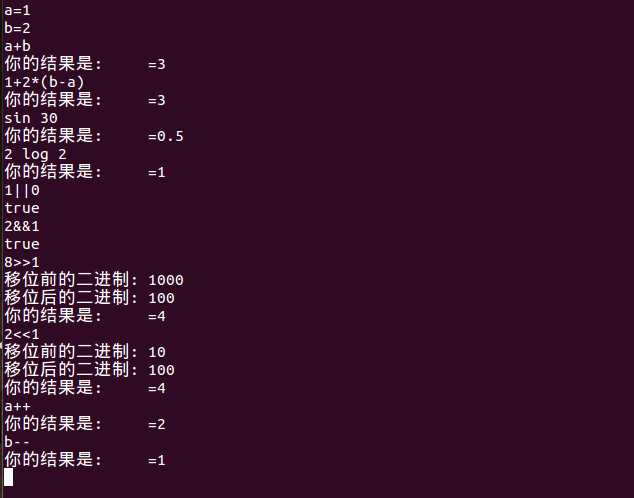
运行结果:
以上是关于编译原理-如何使用flex和yacc工具构造一个高级计算器的主要内容,如果未能解决你的问题,请参考以下文章