Kafka消费者客户端心跳请求
Posted 敲代码的程序狗
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka消费者客户端心跳请求相关的知识,希望对你有一定的参考价值。
1. 发起心跳请求
在Consumer客户端启动的时候,就会构建心跳监测线程HeartbeatThread并启动,
心跳监测线程名:kafka-coordinator-heartbeat-thread|group.id
例如:kafka-coordinator-heartbeat-thread | consumer0
/**
* Java学习资料
* wx: javataozi888
**/
private boolean enabled = false;
private synchronized void startHeartbeatThreadIfNeeded()
if (heartbeatThread == null)
heartbeatThread = new HeartbeatThread();
heartbeatThread.start();
虽然这个时候启动了, 但是run方法里面有个逻辑标志为enabled=false,实际上这个时候并不会发出心跳监测的。
它会根据整个消费组的状态变化而变化。
1.1 启动心跳线程
比如, 当我们的消费者客户端发起JoinGroupRequest并成功回调, 则就会设置enabled=true
JoinGroupResponseHandler#handle
从下面的代码可以看到, JoinGroupRequest回调的时候,把客户端的状态流转为了 COMPLETING_REBALANCE,并启动的监测线程
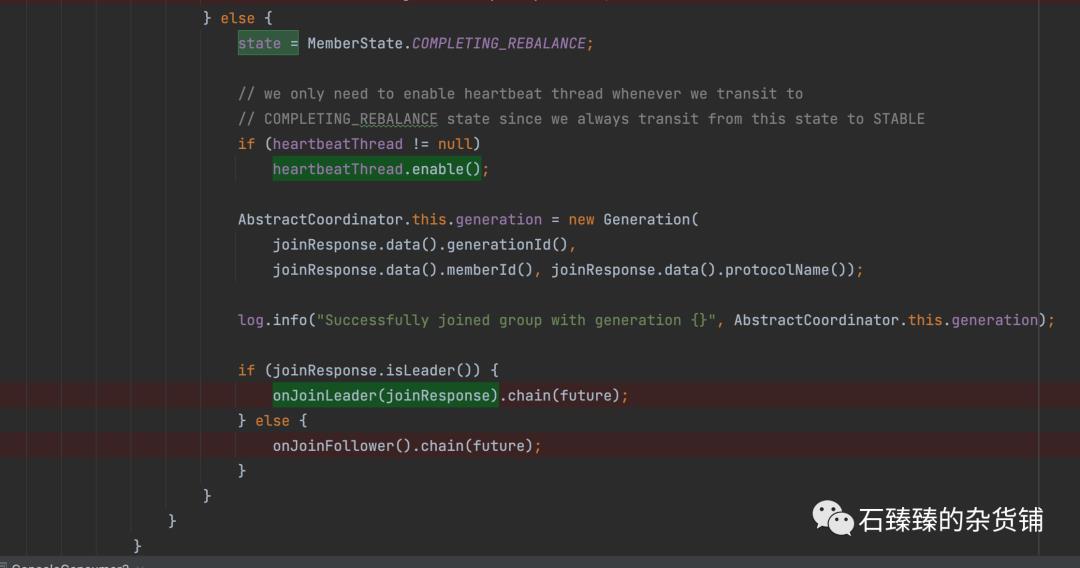
1.2 暂停心跳线程
- 当客户端的状态变更为 UNJOINED 或者 PREPARING_REBALANCE 的时候
- 又或者心跳线程有异常的时候
那么心跳线程就会暂时停止, 因为 UNJOINED 或者 PREPARING_REBALANCE 的状态 本身并不需要去定时检查协调器在不在线, 并不关心。
1.3 发起心跳请求
有个相关的配置如下
熟悉描述默认值heartbeat.interval.ms消费者协调器与消费者协调器之间的心跳间隔时间,心跳用于确保消费者的会话保持活跃,并在新的消费者加入或者离开Group的时候促进Rebalance, 该值必须设置为低于session.timeout.ms,但通常应该设置为不高于该值的1/3, 也可以设置得更低3000(3 秒)
synchronized RequestFuture<Void> sendHeartbeatRequest()
log.debug("Sending Heartbeat request with generation and member id to coordinator ",
generation.generationId, generation.memberId, coordinator);
HeartbeatRequest.Builder requestBuilder =
new HeartbeatRequest.Builder(new HeartbeatRequestData()
.setGroupId(rebalanceConfig.groupId)
.setMemberId(this.generation.memberId)
.setGroupInstanceId(this.rebalanceConfig.groupInstanceId.orElse(null))
.setGenerationId(this.generation.generationId));
return client.send(coordinator, requestBuilder)
.compose(new HeartbeatResponseHandler(generation));
把客户端的基本信息带上发起请求
1.4 发起LeaveGroup(离组)请求
当客户端检测到当前时候超过了 session.timeout.ms的时候,会判定会话超时,这个时候将客户端持有的消费者协调器标记为空,需要重新寻找协调器去。
当客户端检测到当前时间具体上一次客户端poll消息超过了max.poll.interval.ms默认值300000(5 分钟)的时候, 就会执行LeaveGroup离组请求
AbstractCoordinator# maybeLeaveGroup
public synchronized RequestFuture<Void> maybeLeaveGroup(String leaveReason)
RequestFuture<Void> future = null;
// 从 2.3 开始,只有动态成员才会向 broker 发送 LeaveGroupRequest,group.instance.id 有效的 consumer 被视为从不发送 LeaveGroup 的静态成员,成员过期仅受 session timeout 控制
if (isDynamicMember() && !coordinatorUnknown() &&
state != MemberState.UNJOINED && generation.hasMemberId())
// this is a minimal effort attempt to leave the group. we do not
// attempt any resending if the request fails or times out.
log.info("Member sending LeaveGroup request to coordinator due to ",
generation.memberId, coordinator, leaveReason);
LeaveGroupRequest.Builder request = new LeaveGroupRequest.Builder(
rebalanceConfig.groupId,
Collections.singletonList(new MemberIdentity().setMemberId(generation.memberId))
);
future = client.send(coordinator, request).compose(new LeaveGroupResponseHandler(generation));
client.pollNoWakeup();
// 重置状态为UNJOINED
resetGenerationOnLeaveGroup();
return future;
- 在2.3之后, 只有动态成员才会向 broker 发送 LeaveGroupRequest,group.instance.id 有效的 consumer 被视为从不发送 LeaveGroup 的静态成员,成员过期仅受 session.timeout.ms 控制
- 重置客户端状态为 UNJOINED
具体的就不分析了。客户端向GroupCoordinator发送LeaveGroupRequest之后,协调器做的是
3.移除Member,尝试重平衡
2. GroupCoordinator处理请求
下面的代码看着很多, 其实也没有很复杂,基本上都是一些校验逻辑。
GroupCoordinator#handleHeartbeat
def handleHeartbeat(groupId: String,
memberId: String,
groupInstanceId: Option[String],
generationId: Int,
responseCallback: Errors => Unit): Unit =
validateGroupStatus(groupId, ApiKeys.HEARTBEAT).foreach error =>
if (error == Errors.COORDINATOR_LOAD_IN_PROGRESS)
// the group is still loading, so respond just blindly
responseCallback(Errors.NONE)
else
responseCallback(error)
return
groupManager.getGroup(groupId) match
case None =>
responseCallback(Errors.UNKNOWN_MEMBER_ID)
case Some(group) => group.inLock
if (group.is(Dead))
// if the group is marked as dead, it means some other thread has just removed the group
// from the coordinator metadata; this is likely that the group has migrated to some other
// coordinator OR the group is in a transient unstable phase. Let the member retry
// finding the correct coordinator and rejoin.
responseCallback(Errors.COORDINATOR_NOT_AVAILABLE)
else if (group.isStaticMemberFenced(memberId, groupInstanceId, "heartbeat"))
responseCallback(Errors.FENCED_INSTANCE_ID)
else if (!group.has(memberId))
responseCallback(Errors.UNKNOWN_MEMBER_ID)
else if (generationId != group.generationId)
responseCallback(Errors.ILLEGAL_GENERATION)
else
group.currentState match
case Empty =>
responseCallback(Errors.UNKNOWN_MEMBER_ID)
case CompletingRebalance =>
// consumers may start sending heartbeat after join-group response, in which case
// we should treat them as normal hb request and reset the timer
val member = group.get(memberId)
completeAndScheduleNextHeartbeatExpiration(group, member)
responseCallback(Errors.NONE)
case PreparingRebalance =>
val member = group.get(memberId)
completeAndScheduleNextHeartbeatExpiration(group, member)
responseCallback(Errors.REBALANCE_IN_PROGRESS)
case Stable =>
val member = group.get(memberId)
completeAndScheduleNextHeartbeatExpiration(group, member)
responseCallback(Errors.NONE)
case Dead =>
throw new IllegalStateException(s"Reached unexpected condition for Dead group $groupId")
简单来说就是
- 校验一下Group协调器存不存在当前Member
- 校验 Group的状态是否Dead,如果是Dead的话则客户端要重新寻找新的GroupCoordinator并JoinGroup
- 判断客户端和GroupCoordinator是否在同一个年代,如果不是一个年代说明客户端需要重新JoinGroup了。
- 如果GroupCoordinator 当前状态是 PreparingRebalance的话, 客户端会判断自身如果是STABLE的话,则会重新JoinGroup。
- 如果GroupCoordinator当前状态是CompletingRebalance、Stable , 则会清理一下GroupCoordinator设置的延迟过期任务, 并重新设置一个新的任务。这个任务执行的时间是配置 session.timeout.ms 之后。如果假设没有心跳线程请求过来了, 那么这个任务就会被执行。如果执行了会有啥问题呢?请继续看下面的消费组协调器超时任务
关于JoinGroupRequest, 是客户端发起加入到消费组的请求。
具体讲解请看:Kafka消费者JoinGroupRequest流程解析
2.1 消费组协调器超时任务
如果在session.timeout.ms 期间一直没有收到客户端来的信跳请求,那么消费组协调器超时任务就会被执行
def onExpireHeartbeat(group: GroupMetadata, memberId: String, isPending: Boolean): Unit =
group.inLock
if (group.is(Dead))
// 如果当前心跳监测到Group协调器已经Dead了,仅仅只是打印一下日志, 因为它自身可能已经不是组协调器了,他已经不能再被允许做什么了
info(s"Received notification of heartbeat expiration for member $memberId after group $group.groupId had already been unloaded or deleted.")
else if (isPending)
info(s"Pending member $memberId in group $group.groupId has been removed after session timeout expiration.")
// 客户端在发起第一次JoinGroup请求的时候,并没有带上memberId,但是Group会生成一个给客户端返回
// 这个时候这个member就是Pending状态的,属于待加入状态, 因为它还会发起第二次JoinGroup请求并带上这个memberId,才算是真的Join了Group
// 在这里 直接把这个memberId从Pending缓存中移除了,因为它心跳监测过期了,这意味着客户端需要重新发起第一次Join
removePendingMemberAndUpdateGroup(group, memberId)
else if (!group.has(memberId))
debug(s"Member $memberId has already been removed from the group.")
else
val member = group.get(memberId)
if (!member.hasSatisfiedHeartbeat)
info(s"Member $member.memberId in group $group.groupId has failed, removing it from the group")
removeMemberAndUpdateGroup(group, member, s"removing member $member.memberId on heartbeat expiration")
- 如果Group状态是Dead,那么什么也不做,它都不是组协调器了,它什么也做不了
- 如果当前的member 是Pending状态,(首先了解一下Pending状态,Member第一次JoinGroup的时候由于没有带上memberId参数,组协调器会生成一个MemberId返回给客户端,并且组协调器会在自身保持一份这个Member的数据,但是这个时候的Member是Pending状态的,意识是等待加入的状态, 因为它还会再发起第二次JoinGroup请求,并且带上这个MemberId。这个时候才是真正的JoinGroup。) 则把这个Member从Pending缓存中移除。也就意味着这个Member需要再次发起第一次JoinGroup请求。
- 其他状态就是确定期间没有心跳请求的话, 那么要把这个Member移除掉并更新Group元信息。①. 将这个Member在Group协调器缓存中移除 ②. 如果当前的状态是Stable | CompletingRebalance 的话, 直接走prepareRebalance流程
prepareRebalance 流程主要做的事情就是
- 将状态流转到PreparingRebalance
- 设置一个DelayedJoin超时过期任务,超时时间是max.poll.interval.ms 默认300000(5 分钟)。
- 这个任务会在满足要求(所有Member都JoinGroup了)的时候,去执行onCompleteJoin。这个就是跟JoinGroup后面的流程是一样的。主要动作就是通知所有的Member,你们都Join成功了, 接下来你们该发起SyncGroup请求了。 具体请看:Kafka消费者JoinGroupRequest流程解析
3. 客户端处理返回数据
HeartbeatResponseHandler#handle
这一块的代码就不贴了,主要就是根据返回的异常做具体的事情。
如果没有异常的话啥也不干。
异常映射关系如下:
- COORDINATOR_NOT_AVAILABLE | NOT_COORDINATOR 该去重新寻找新的GroupCoordinator
- REBALANCE_IN_PROGRESS;当前组协调器正在Rebalance中, 如果当前客户端是STABLE状态,说明它该重新发起JoinGroupRequest了,赶紧的它也要去Join并参与分配了呢。
- ILLEGAL_GENERATION | UNKNOWN_MEMBER_ID | FENCED_INSTANCE_ID :将Member的状态设置为 UNJOINED,并重新JoinGroup
4. 心跳线程状态图
我们可以先看一下 消费者客户端Member的状态流转图。
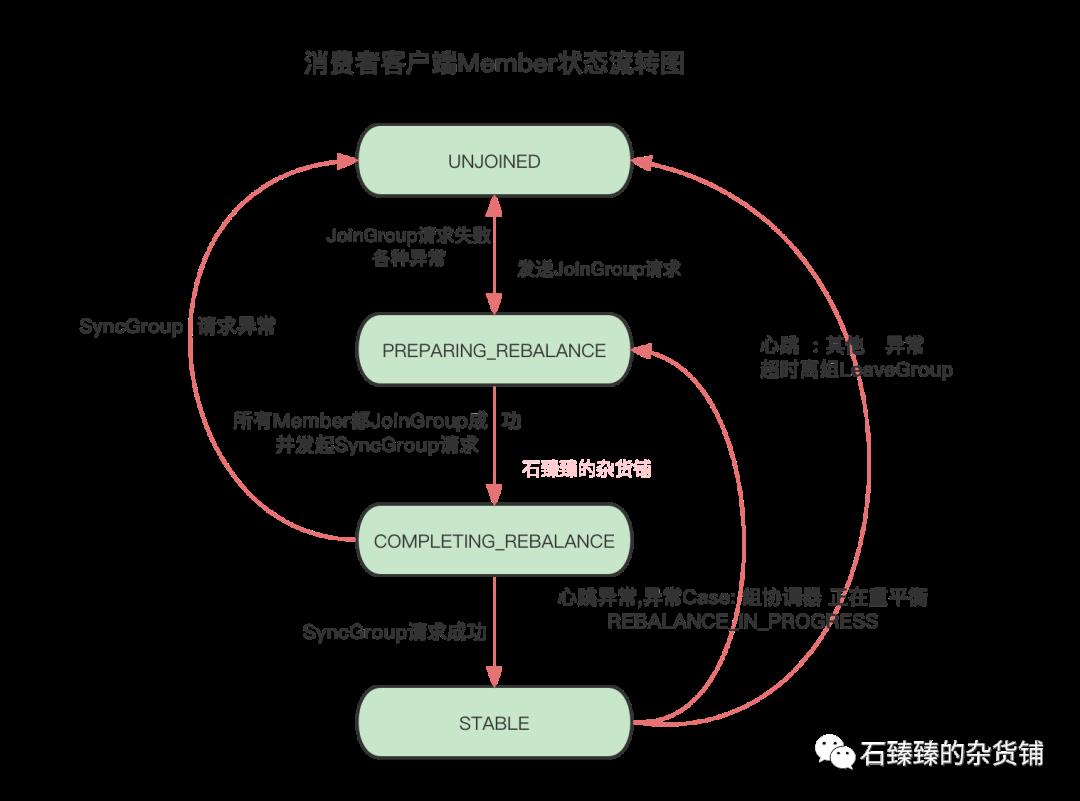
了解了这个状态流转图, 也就可以知道心跳线程状态流转图了
因为心跳线程的运行只有在 两个状态:COMPLETING_REBALANCE 、STABLE

以上是关于Kafka消费者客户端心跳请求的主要内容,如果未能解决你的问题,请参考以下文章