布隆过滤器基于Hutool库实现的布隆过滤器Demo
Posted july-sunny
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了布隆过滤器基于Hutool库实现的布隆过滤器Demo相关的知识,希望对你有一定的参考价值。
布隆过滤器出现的背景:
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路,存储位置要么是磁盘,要么是内存。很多时候要么是以时间换空间,要么是以空间换时间。
在响应时间要求比较严格的情况下,如果我们存在内里,那么随着集合中元素的增加,我们需要的存储空间越来越大,以及检索的时间越来越长,导致内存开销太大、时间效率变低。
布隆过滤器的特点:
此时需要考虑解决的问题就是,在数据量比较大的情况下,既满足时间要求,又满足空间的要求。即我们需要一个时间和空间消耗都比较小的数据结构和算法。Bloom Filter就是一种解决方案。
布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
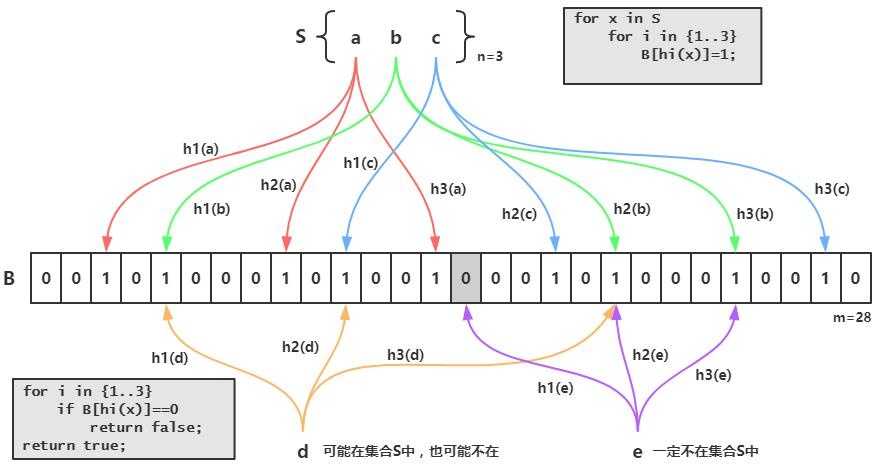
Bloom Filter的缺点
bloom filter之所以能做到在时间和空间上的效率比较高,是因为牺牲了判断的准确率、删除的便利性
- 存在误判,可能要查到的元素并没有在容器中,但是hash之后得到的k个位置上值都是1。如果bloom filter中存储的是黑名单,那么可以通过建立一个白名单来存储可能会误判的元素。
- 删除困难。一个放入容器的元素映射到bit数组的k个位置上是1,删除的时候不能简单的直接置为0,可能会影响其他元素的判断。可以采用Counting Bloom Filter
参考:https://www.cnblogs.com/z941030/p/9218356.html
// 初始化 注意 构造方法的参数大小10 决定了布隆过滤器BitMap的大小 BitMapBloomFilter filter = new BitMapBloomFilter(10); filter.add("123"); filter.add("abc"); filter.add("ddd"); // 查找 filter.contains("abc")
以上是关于布隆过滤器基于Hutool库实现的布隆过滤器Demo的主要内容,如果未能解决你的问题,请参考以下文章