DOM-XSS攻击原理与防御
Posted mysticbinary
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DOM-XSS攻击原理与防御相关的知识,希望对你有一定的参考价值。
XSS的中文名称叫跨站脚本,是WEB漏洞中比较常见的一种,特点就是可以将恶意html/javascript代码注入到受害用户浏览的网页上,从而达到劫持用户会话的目的。XSS根据恶意脚本的传递方式可以分为3种,分别为反射型、存储型、DOM型,前面两种恶意脚本都会经过服务器端然后返回给客户端,相对DOM型来说比较好检测与防御,而DOM型不用将恶意脚本传输到服务器在返回客户端,这就是DOM型和反射、存储型的区别,所以我这里就单独的谈一下DOM型XSS。
DOM文档
为了更好的理解DOM型XSS,先了解一下DOM,毕竟DOM型XSS就是基于DOM文档对象模型的。对于浏览器来说,DOM文档就是一份XML文档,当有了这个标准的技术之后,通过JavaScript就可以轻松的访问它们了。
下面举例一个DOM将HTML代码转化成树状结构:
<html>
<head>
<meta charset="gbk" />
<title> TEST </title>
</head>
<body>
<p>The is p.<p>
<h1>Product:</h1>
<ul>
<li>Apple</li>
<li>Pear</li>
<li>Corn</li>
</ul>
</body>
</html>
转化成模型如下图:
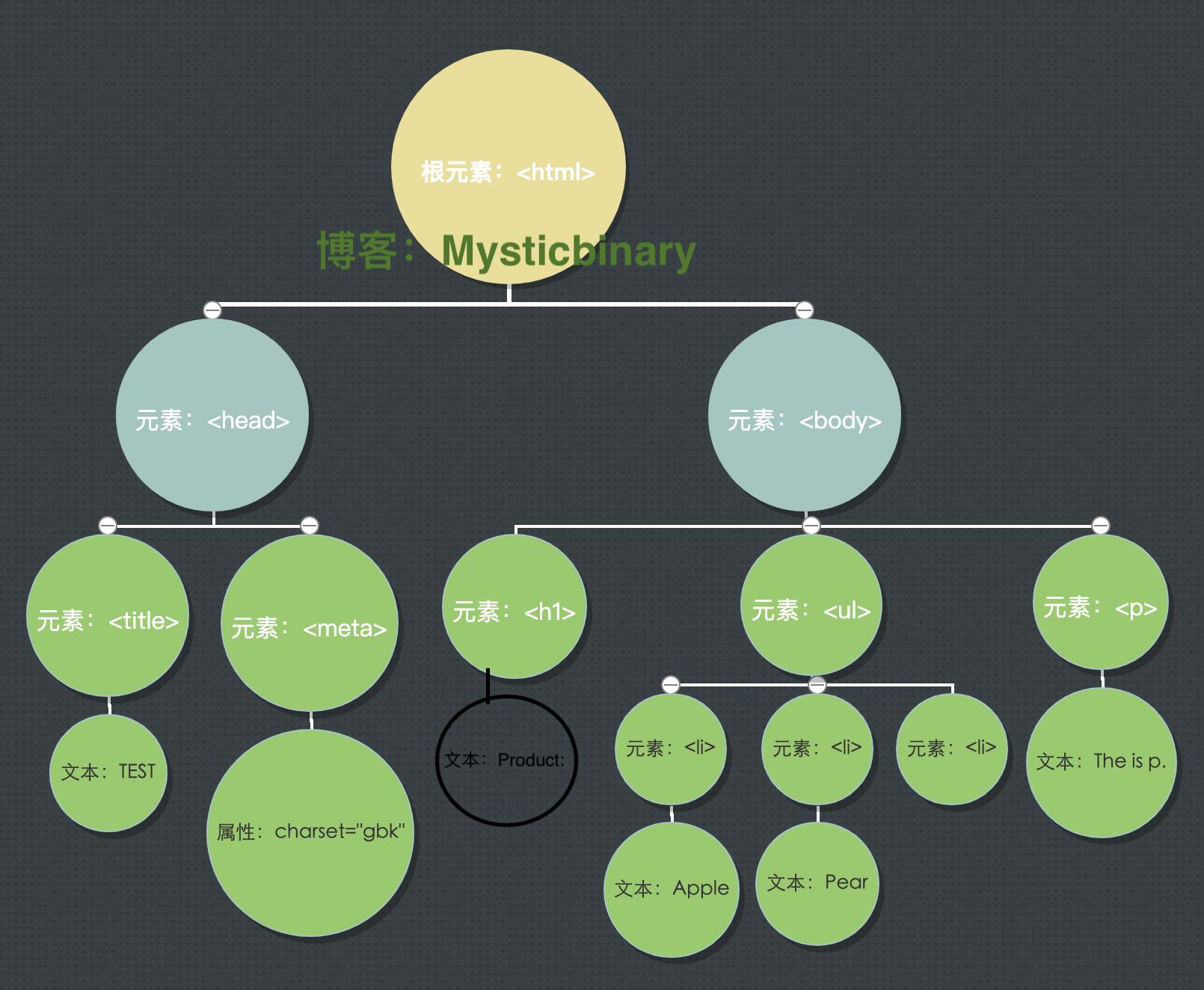
这样做的好处就是,通过这种简单的树状结构,就能把元素之间的关系简单明晰的表示出来,方便客户端的JavaScript脚本通过DOM动态的检查和修改页面内容,不依赖服务端的数据。
利用原理
客户端JavaScript可以访问浏览器的DOM文本对象模型是利用的前提,当确认客户端代码中有DOM型XSS漏洞时,并且能诱使(钓鱼)一名用户访问自己构造的URL,就说明可以在受害者的客户端注入恶意脚本。利用步骤和反射型很类似,但是唯一的区别就是,构造的URL参数不用发送到服务器端,可以达到绕过WAF、躲避服务端的检测效果。
为了更方便大家的理解,下面我举几个场景给大家理解。
场景一:innerHTML
<html>
<head>
<title> DOM-XSS TEST </title>
<style>
#box{width:250px;height:200px;border:1px solid #e5e5e5;background:#f1f1f1;}
</style>
</head>
<body>
<script>
window.onload= function(){
var oBox=document.getElementById("box");
var oSpan=document.getElementById("span1");
var oText=document.getElementById("text1");
var oBtn=document.getElementById("Btn");
oBtn.onclick = function(){
oBox.innerHTML = oBox.innerHTML + oSpan.innerHTML + oText.value + "<br/>";
// oBox.innerHTML += oSpan.innerHTML + oText.value + "<br/>";//这是简便的写法,在js中 a=a+b ,那么也等同于 a+=b
oText.value=""
};
}
</script>
<div id="box"></div>
<span id="span1">小明:</span>
<input type="text" id="text1"/>
<input id="Btn" type="button" value="发送消息" name=""/>
</body>
</html>
第一次是正常访问:
hellow
第二次是将JavaScript代码作为参数写入值中:
<svg/onload=alert(1)>
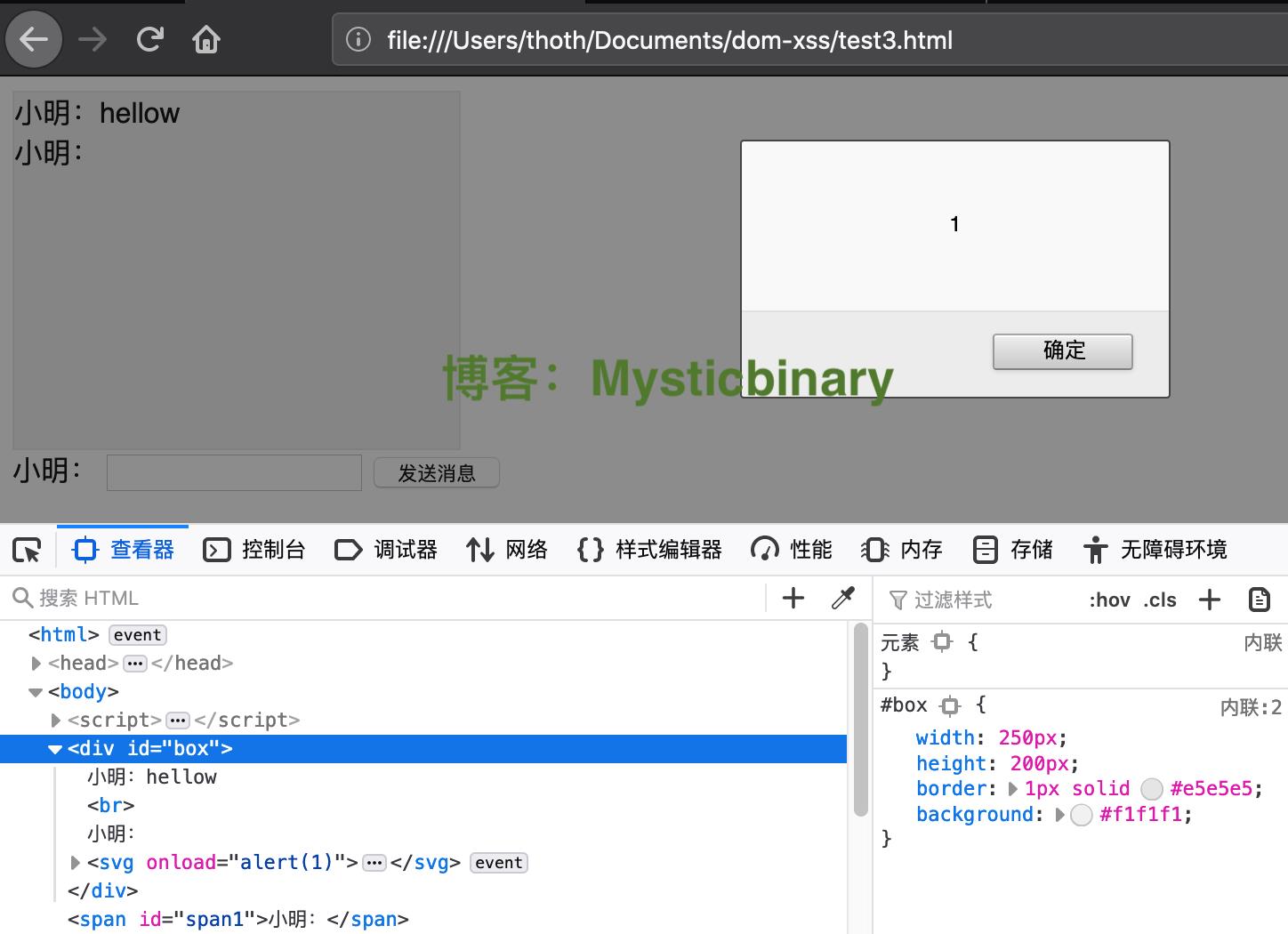
这里我只在火狐浏览器利用成功,在chrome利用失败,我猜可能chrome对安全防护做得比较好,这里不继续各个浏览器版本问题。
使用innerHTML、outerHTML 时要注意,标签需不进行编码处理,可能会导致XSS。防护方法就是替换成innerText,它自动将HTML标签解析为普通文本,所以HTML标签不会被执行,避免XSS攻击。
oBox.innerText = oBox.innerHTML + oSpan.innerHTML + oText.value + "<br/>";
场景二:跳转
<html>
<head>
<title> DOM-XSS TEST </title>
</head>
<body>
<script>
var hash = location.hash;
if(hash){
var url = hash.substring(1);
location.href = url;
}
</script>
</body>
</html>
正常访问是用#去实现页面跳转,但是因为跳转部分参数可控,可能导致Dom xss。
通过 location.hash 的方式,将参数写在 # 号后,既能让JS读取到该参数,又不让该参数传入到服务器,从而避免了WAF的检测。
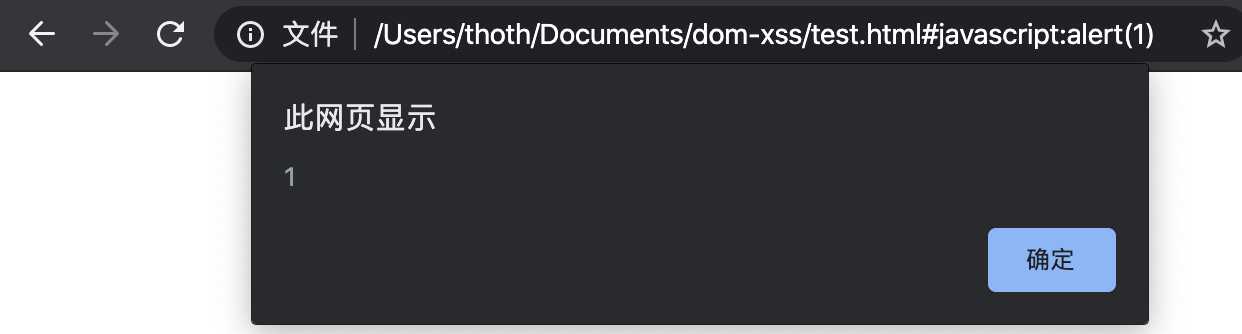
变量hash作为可控部分,并带入url中,变量hash控制的是#之后的部分,可以使用伪协议#javascript:alert(1)。常见的几种伪协议有javascript:、vbscript:、data:等。而现在的移动端(android和ios),都可以自定义这种协议从浏览器打开本地app,具体可以看看https://www.cnblogs.com/WuXiaolong/p/8735226.html
#javascript:alert(1)
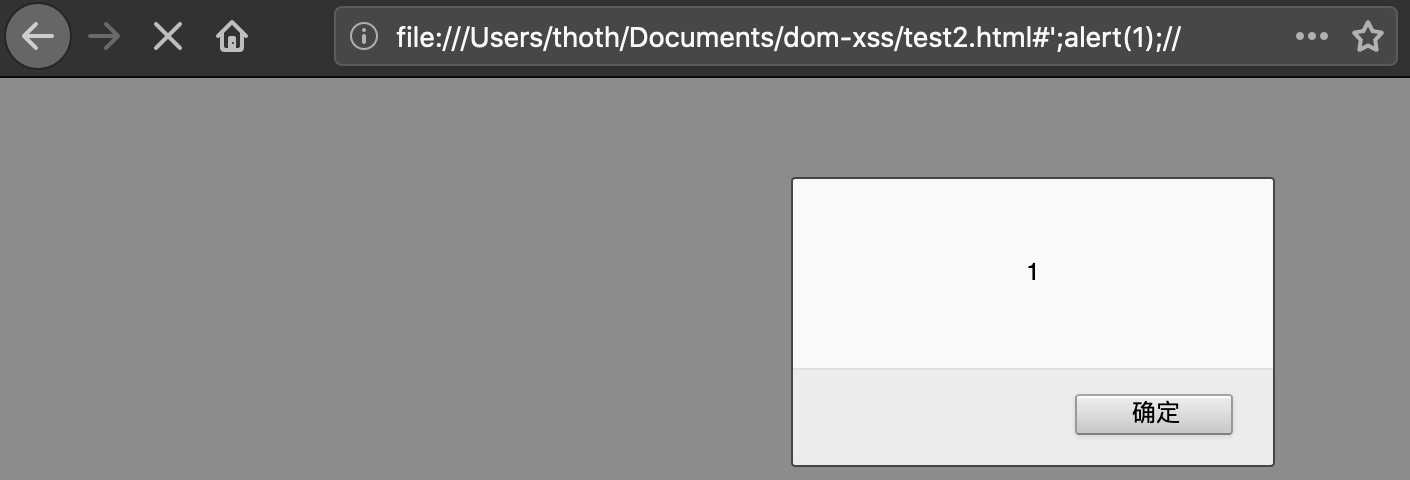
场景三:eval
#‘;alert(1);//
直接将用户输入数据拼接到代码里。
eval("var x = ‘" + location.hash + "‘");
场景四:cookie、referrer
从localStorage、SessionStorage、Cookies储存源中取数据,这些值往往会被开发者忽略,认为这些值都是在浏览器获取的,是安全的,就未进行处理。
var cookies = document.cookie;
document.write(cookies);
场景五:document.write 、document.URL.indexOf("id=")
var ids = document.URL;
document.writeln(ids.substring(ids.indexOf("id=")+3,ids.length));
indexOf获取url里面的参数,然后通过writeln( )或者write( )输出到HTML,造成xss,不过我现在(2020.3)在chrome和firefox浏览器测试,write()函数很难利用,除非结合一些特殊场景。
防护策略
还有一些正则匹配缺陷、业务逻辑型缺陷、配合移动端跳转等、使用第三方前端框架(比如多媒体编辑框)等场景没有一一进行说明(精力实在有限了...),后期有空可能会继续补全这些场景。
检测的流程就是通过查看代码是否有document.write、eval、window之类能造成危害的地方,然后通过回溯变量和函数的调用过程,查看用户是否能控制输入。如果能控制输入,就看看是否能复习,能复习就说明存在DOM XSS,需要对输入的数据进行编码。
代码审计时审计的特征点(包括但不限于):
var elements = location.hash;
elements.indexOf
var oBtn=document.getElementById("Btn");
oBtn.innerHTML
oBtn.outerHTML
document.createElement
oBtn.setAttribute
oBtn.appendChild
document.write
document.writeln
eval("var x = ‘" + location.hash + "‘");
setTimeout("alert(‘xss‘)", 1000)
window.setTimeout
document.setTimeout
window.setInterval
document.execCommand(‘ForeColor‘,false,‘#BBDDCC‘);
document.createElement
document.createElementNS
document.createEvent
document.createXxx
js语法很灵活、库函数也很多,这里没法完全列举全,我觉得需要对js语法体系有一定了解,才可能更多的找全这些特征。
当业务需要必须得将用户输入的数据放入html,那就要尽量使用安全的方法,比如innerText(),testContent()等。在使用框架时尽量使用框架自带的安全函数。
参考文档
《XSS跨站脚本-攻击剖析与防御》
《Web漏洞防护》
https://xz.aliyun.com/t/5181
https://domgo.at/cxss/example
https://www.secpulse.com/archives/92286.html
以上是关于DOM-XSS攻击原理与防御的主要内容,如果未能解决你的问题,请参考以下文章