第十三章大规模数据库架构
Posted shaoyayu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第十三章大规模数据库架构相关的知识,希望对你有一定的参考价值。
第十三章、大规模数据库架构
内容提要:
1、了解分布式数据库技术
2、了解并行数据库技术
3、了解云数据库技术
4、了解XML数据库技术
第一节 分布式数据库
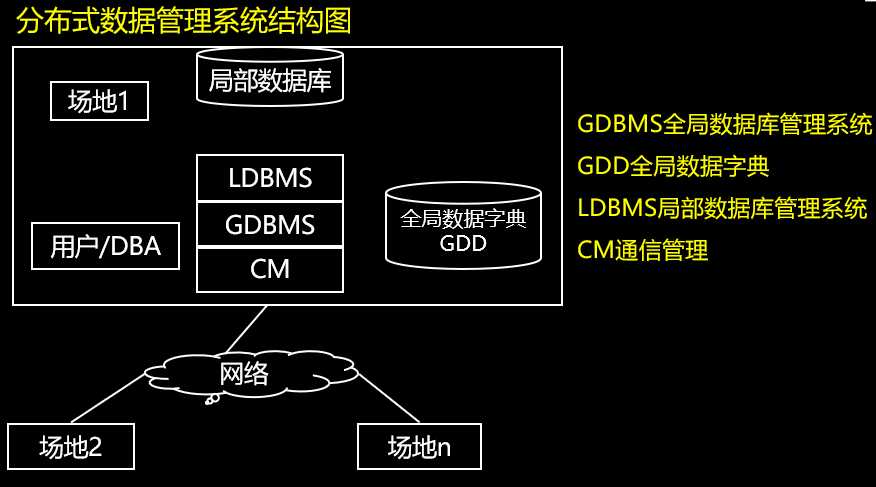
1.1、分布式数据库系统概述
分布式数据库系统与分布式数据库的区别:
分布式数据库系统——数据分布存储于若干场地,并且每个场地由独立于其它场地的DBMS进行数据管理。物理上分散、逻辑上集中的数据库系统。
分布式数据库——分布式数据库系统中各场地上数据库的逻辑集合。
1.2、分布式数据库目标与数据分布策略
分布式数据库目标:
12个目标:
本地自治、非集中式管理、高可用性。(最基本特征)
位置独立性、数据分片独立性、数据复制独立性。(分布透明性)
分布式查询、事务管理。(复杂性)
硬件独立性、操作系统独立性、网络独立性、
数据库管理系统独立性。
数据分布策略:
从数据分片和数据分配考虑
数据分片(对关系操作)
按一定规则将某一个全局关系划分为多个片断。
四种基本方法:
水平分片——每个分片是原始关系所有数据行的子集合。
垂直分片——每个分片是原始关系所有数据列的子集合。
导出分片——导出水平分片。
混合分片——以上三种的混合。
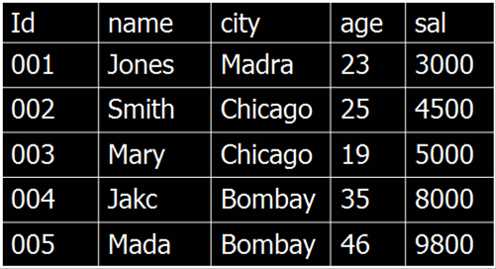
水平划分
例:来自同一个城市的雇员位于一个分片将Chicago数据存储于场地Chicago 。相当多的查询是本地查询
垂直划分
id,name.
数据分配(对分片结果操作)
将分片产生的片断分配存储在各个场地上。解决数据分配的方法:
集中式——所有数据片断安排在一个场地上。
分割式——所有全局数据有且只有一份,分割成若干被分配在特定场地上的片断。
全复制式——全局数据有多个副本,每个场地上有一个完整的数据副本。
混合式—— 介于分割与全复制式 之间。
1.3、分布式数据库系统的体系结构
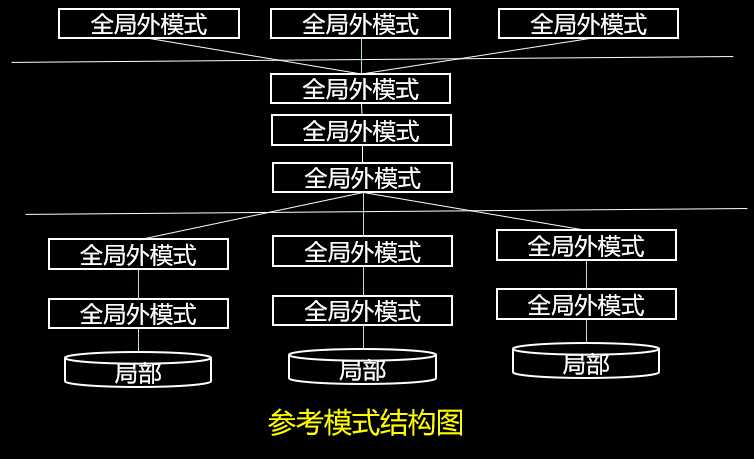
分布透明性
分片透明性。用户无需考虑数据分片。
位置透明性。用户只需考虑数据分片情况,无需考虑数据分片位置。
局部数据模型透明性。用户既要了解全局数据的分片情况,还要了解各片断的副本复制情况及位置分配情况。
1.4、分布式数据库的相关技术
分布式查询
用户与分布式数库系统的接口。分布式查询优化需考虑:
①操作执行的顺序。
②操作的执行算法(连接操作和并操作)。
③不同场地间的数据流动的顺序。
分布式事务管理
主要包括:
①恢复控制
基于两阶段的提交协议。
②并发控制
基于封锁协议。
第二节 并行数据库
2.1、并行数据库概述
并行数据库系统——通过并行实现各种数据操作,如数据载入、索引建立、数据查询等,可以提高系统的性能。
优势:增强的可用性:当存储某个关系的场地系统崩溃时,可继续使用存储在别的场地的副本。
2.2、并行数据库系统结构
实现并行DBMS的三种硬件结构:
(1)共享内存系统(Shared Memory)
(2)共享磁盘系统(Shared Disk)
(3)无共享资源系统(Shared Nothing)
(4)层次结构(Hierachical)
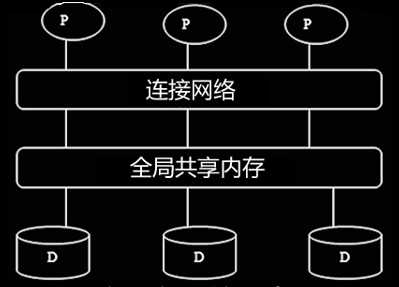
(1)共享内存系统:
? 多个cpu通过连接网络进行通信,并能访问公共的主存。
随着CPU增加,造成内存冲突。
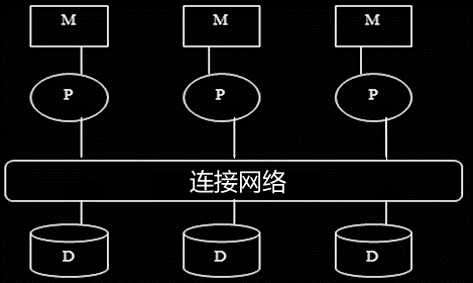
(2)共享磁盘系统:
? 每个cpu拥有自己的私有内存,并通过连接网络直接访问所有磁盘。
通过网络实现CPU之间的数据交换,增加了通信代价。
大型并行数据库系统的最优结构
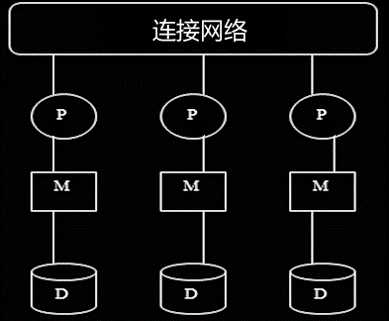
(3)无共享资源系统:
每个cpu拥有自己的内存和磁盘空间,并无公共区域,cpu之间所有通信通过连接网络来完成。
存在通信代价,非本地磁盘访问代价高。
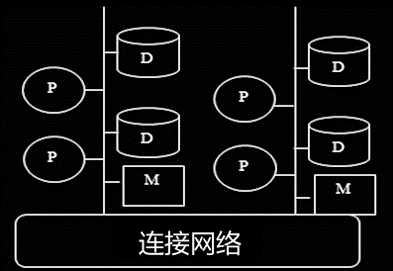
(4)层次结构:
前三种体系的结合。分为两层,顶层是无共享结构,底层是共享内存或共享磁盘结构。
集成了以上三种结构的优缺点。
2.3、数据划分与并行算法
一维数据划分:将大数据集水平划分到多个磁盘上,可以通过并行读写有效地利用多磁盘的I/O带宽。
(1)轮转法——如果系统有n个cpu,将第i条记录划分到第i mod n 处理器的方法称为轮转划分方法。
(2)散列法——使用特定的哈希函数,作用于选定的属性,将记录划分到不同的处理机。
(3)范围划分法——首先对记录进行排序,然后按照排序码将其划分成n个区域,使每个区域中近似含有相同数目的记录,处于第i个区域的记录分布于处理机i。
优势劣势:
(1)轮转法可有效应用于需要访问整个关系的查询处理,当需要访问部分记录时,散列法和范围更优。
(2)范围法可能会导致数据偏斜,也就是不同分片含有的记录数目差别很大。数据偏斜会造成存有大片数据分片的处理机的性能瓶颈问题。
(3)散列法优点是:即使数据随时间增加或减少,也能保持均匀分布。
多维数据划分:
- CMD多维划分法
- BERD多维划分法
- MAGIC多维划分法。
2.3.1、并行算法:
(1)并行排序:
a.用区域划分法先将关系的所有记录重新分布再进行排序。
b.每个cpu使用排序算法对分配给它的记录排序。每个处理机得到分配给它的所有记录的有序序列。
c.通过按照区域划分的对应次序访问处理机得到完整的有序关系。
例:employee按属性salary排序 ,salary的取值范围从10~210,处理机数目20
10~20的所有记录分布于处理机1
21~30…………………………… 2
……
……
200~210…………………………20难点:如何进行区域划分来使得每个处理机分布的记录数目近似相等。否则,对具有大量记录的处理机排序时将产生性能瓶颈,从而限制并行排序的可扩展性。
(2)并行连接:
假设:对关系A和B进行划分时,连接属性为age,关系初始分布在若干磁盘上,但不是基于连接属性分布的。
方法:对关系A和B重新划分:把连接属性age的取值分成k个区域
例:假设10个处理机,age取值范围0~100
记录按照相应的age值进行分布
0<=age<1 处理机1
10<=age<20 处理机2
……
……
90<=age<100 处理机10
缺点:产生由对数据偏斜不同分片的记录数目差别很大 第三节 云计算数据库架构.
3.1、云计算概述
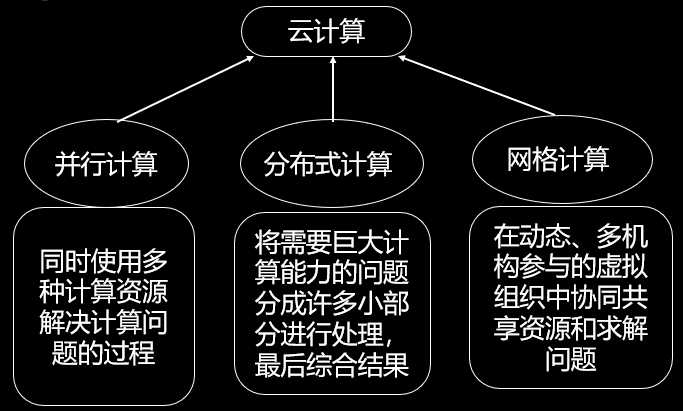
云计算是一种商业计算模型。它将计算任务分布在大量计算机构成的资源池上,使各种应用系统能够根据需要获取计算力、存储空间和信息服务。
云计算服务类型

1、IaaS
将硬件设备等基础资源封装成服务供用户使用
2、PaaS
对资源的抽象层次更进一步,提供用户应用程序运行环境
3、SaaS
针对性更强,它将某些特定应用软件功能封装成服务
云(cloud):
即云计算提供商的数据中心的软硬件设施。
云分为:
公共云:以即用即付的方式提供给公众。
私有云:不对公众开放的云。
混合云
3.2、云数据库体系结构
云数据库(CloudDB,简称云库):云+数据库。
目前主要的云计算平台:
AWS(Amazon Web Services)
GAE(Google AppEngine)
Hadoop
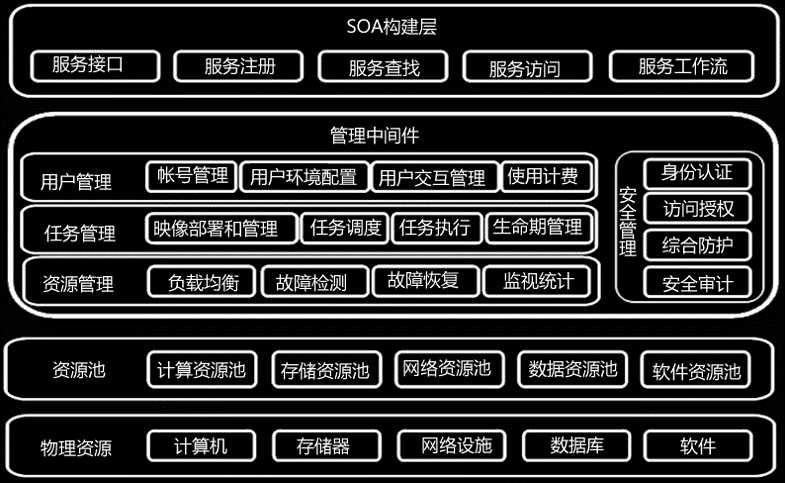
谷歌云 计算基础架构模式(4个子系统)
Google File System文件系统
Map/Reduce分布式编程环境
Chubby分布式锁机制
BigTable大规模分布式数据库
3.3、云数据库与传统数据库比较
云数据库的缺点:
数据安全问题
对云的管理问题
对因特网的依赖
第四节 XML数据库
4.1、XML数据库概述
XML,eXtensible Markup Language.可扩展标识语言。
XML数据库——支持对XML文档格式进行存储和查询等操作的数据库管理系统。
三种类型的XML数据库 :
XML Enabled Database(XEDB) )——能处理XML的数据库。
Native XML Database(NXD) )——纯XML数据库。
Hybird XML Database(HXD)——混合XML数据库。
与传统数据库比较,XML数据库 的优势:
能够对半结构化数据进行处理。
提供 对标签和路径的操作。
能清晰地表达数据的层次特征。
4.2、SQL Server 2008 与 XML
SQL Server中的XML语句:
FOR XML:将返回结果变为XML格式。
示例:
SELECT * FROM Table_cus
WHERE …. FOR XML RAWSQL Server中的XML数据类型:
XML类型的字段
示例:
CREATE TABLE T_info
(
cid int ,
Content xml
) 例题讲解
1、Google的云数据库是一个分布式的结构化数据存储系统,称作( )。
答案:Bigtable
2、在分布式数据库中,使用( )模式来描述各片段到物理存放场地的映像。
答案:分配
3、在并行数据库中,有关系R(A, B)和S(A, C),需要将它们根据A属性拆分到不同的磁盘上。现有查询SELECT B FROM R, S WHERE R.A = S.A。下列拆分方式中最适合该查询的是( )
A.散列划分
B.轮转法
C.范围划分
D.列表划分
答案:A
4、关于分布式数据库,下列说法错误的是( )
A.分布式数据库系统的目标是利用多处理机结点并行地完成数据库任务,以提高数据库系统的整体性能
B.分布式数据库中位置透明性是指数据分片的分配位置对用户是透明的,使得用户在编程时只需考虑数据分片情况,而不用关心具体的分配情况
C.分布式数据库的事务管理包括恢复控制和并发控制,恢复控制一般采用的策略是基于两阶段的提交协议
D.分布式数据库的查询代价需要考虑站点间数据传输的通信代价,一般来说导致数据传输量大的主要原因是数据间的连接操作和并操作
答案:A
5、关于分布式数据库,下列说法错误的是( )
A.分布式数据库的查询代价需要考虑站点间数据传输的通信代价,一般来说导致数据传输量大的主要原因是数据间的连接操作和并操作
B.分布式数据库中位置透明性是指数据分片的分配位置对用户是透明的,使得用户在编程时只需考虑数据分片情况,而不用关心具体的分配情况
C.分布式数据库的事务管理包括恢复控制和并发控制,恢复控制一般采用的策略是基于两阶段的提交协议
D.分布式数据库系统的目标是利用多处理机结点并行地完成数据库任务,以提高数据库系统的整体性能
答案:D
6、在分布式数据库应用系统中,对全局关系进行分片设计时,下列说法正确的是( )
A.对于一个全局关系中的任意数据,不允许其不属于任何一个片段,也不允许某些数据同时属于不同的片段
B.对于一个全局关系中的任意数据,可以允许其不属于任何一个片段,也允许某些数据同时属于不同的片段
C.对于一个全局关系中的任意数据,不允许其不属于任何一个片段,但允许某些数据同时属于不同的片段
D.对于一个全局关系中的任意数据,对于一个全局关系,可以允许某些数据属于不同片段,但不允许某些数据同时属于不同的片段
答案:A
7、在分布式数据库的数据分配中,若所有全局数据有且只有一份,他们被分割成若干切片,每个片段被分配在一个特定场地上,则该策略属于( )
A.分割式
B.集中式
C.全复制式
D.混合式
答案:A
8、分布式数据库系统的“分片透明性”位于( )
A.全局概念模式与分片模式之间
B.分片模式与分配模式之间
C.全局模式与全局概念模式之间
D.分配模式与局部概念模式之间
答案:A
9、在云计算中,当云以即用即付的方式提供给公众的时候,我们称其为( )
A.公共云
B.私有云
C.共享云
D.混合云
答案:A
以上是关于第十三章大规模数据库架构的主要内容,如果未能解决你的问题,请参考以下文章