字符集专题
Posted yizhangheka
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字符集专题相关的知识,希望对你有一定的参考价值。
=======================================================================
张贺,多年互联网行业工作经验,担任过网络工程师、系统集成工程师、LINUX系统运维工程师
笔者微信:zhanghe15069028807,现居济南历下区
=======================================================================
?
字符集专题
预备知识
1、字符
在美国,26个字母,每个字母就是一个字符。
在中国,每个汉字就是一个字符
2、字符集合
多个字符的集合就叫字符集合
3、字符集
给字符集合加上编码就是字符集了。
一组字符加上编码,比如ASCII字符集,就是26个字母的字符集。通常一个字符集代表一个国家或者一个民族。我们中国也有字符集:GB2312(中文简体),BIG5(中文繁体)。
值得一提的是unicode是最大的字符集,包括了现存所有的字符。
4、字符编码
给字符集里面每个字符编的序号就是字符编码。
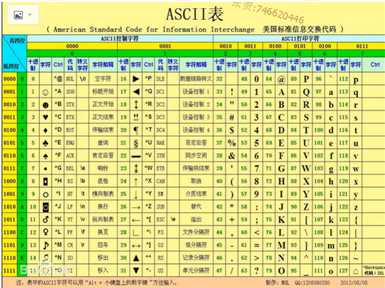
5、计算机如何存储字符?
当我们在notepad里面写入Apple----save的时候,计算机如何保存呢?计算机只会保存二进制,所以它要把apple转化为二进制才能保存,会根据notepad程序设定的字符集进行保存,假如说是根据ASCII字符集进行保存的话,那么保存的其实是:
0100 0001---------->A
0111 0000----------->p
…………
6、计算机又是如何展现字符?为何展示的时候会出现乱码?
上面我们讲了如何存储这些字符,这里面我们讲一下如何展现字符?
notepad保存的时候根据字符集将Apple转换成二进制,展现的时候也必须通过字符集,这个字符集必须是一样的,否则会出现乱码,这一点很好理解。
7、补充说明----字符序collation
再补充一个概念,一个字符集合可以有多个字符序,所谓的字符序指的是字符集合不同的编码方式,所以同样的字符集合,如果字符序不一样的话,也代表不同的字符集。
8.数据库--表当中的字符集和字符序
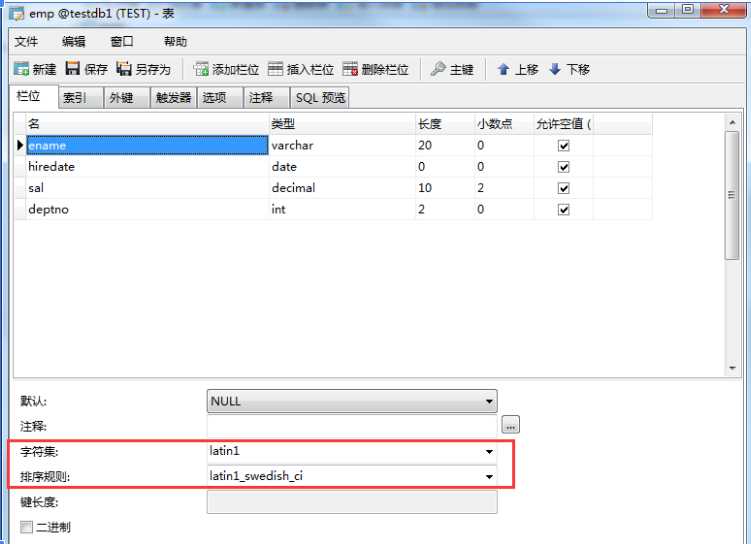
以ci结尾的字符序不区分大小写
以cs结尾的字符序列区分大小写
常见字符集
英语国家字符集(占8位,实际7位)
- ASCII
英语国家的字符集,定义了128个字符,即2的7次方,但计算机的最小存储单位是字节,而不是bit,所以多占一位。
- 扩展ASCII
扩展ASCII字符集是一个大类,里面有latin1,ladin2,ladin5,ladin7,在ASCII字符集的基础上又扩展了拉丁语系的一些字符集,扩展ASCII字符集包括ASCII字符集。
二、中国(16二进制标识)
- GBK2312
中国简体中文字符集
- BIG5
中国繁体中文字符集
- GBK
注意:中国类的字符集是建立在英语国家字符集的基础上,也就是说中国的三大字符集:GBK,BGK2312,BIG5都是包涵扩展ASCII字符集的。
三、全球范围
unicode 全球语言字符集(16位)
UTF8也是由unicode演进的
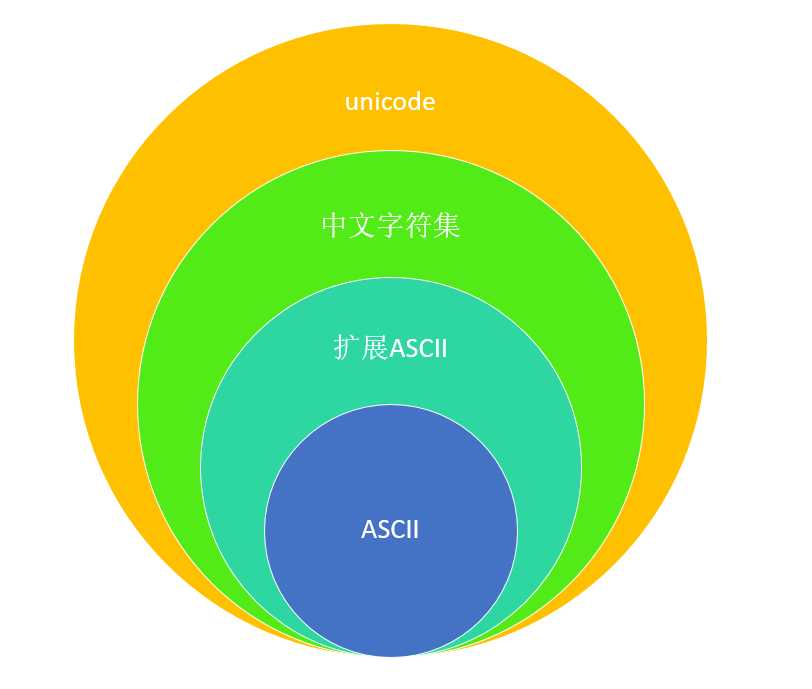
包含关系
普通的ASCII字符集标识128个字符
扩展的ASCII字符集标识了256个字符
GBK,BGK2312,BIG5都是包涵扩展ASCII字符集的。
unicode即包涵英语国家的字符集,也包涵中国的字符集,是最大的字符集。
转换关系
转换关系相当简单了,范围大的可以向范围小的转换,而范围小的没有能力向范围大的转换。
客户端使用字符集A
服务器使用字符集B
假设客户端给服务器发送消息的时候使用字符集A进行编码,当服务器收到之后能用B解码吗?可以,但是解出来是乱码!!所以就要求服务器在解码时也要使用字符集A,这样解析出来才不会有乱码。现在多数软件都是使用UTF8来进行编码,UTF8是全球范围的,也说是说解码的时候必须使用相同的字符集或者比发送者范围大的字符集。发送者会根据接收者的字符集来进行发送,发送者会尽量使用与接收者一样的字符集或者范围比其大的字符集,那么发送者如何知道接收者支持的字符集呢?三次握手时告诉的。
但是在存储的时候不一定使用与发送者一样的字符集进行存储,也有可能是根据其它的字符集进行存储的,但前提是,接收者一定要使用相同的或范围比其大的字符集将发送者发过来的内容进行解码,解码之后再转换成自己存储使用的字符集,但是很少这么做,因为这样效率很低,而且一旦存储字符集比读取字符集范围要小的话,这就尴尬了,读取字符集好不容易读取出来了,而存储字符集无法存储,计算机在这里并不怎么智能,不能存它就强行存储,结果就是存入到计算机内部的就是乱码了。
unicode与UTF8
unicode占两个字节,16位,无论中文还是英文都要占16位,占不够用0补,这样格式就统一了,但是空间会在一定程度上浪费。
如果使用unicode写程序的话,是无法进行编译的,为什么?编译器的字符集是ASCII,编译器只能编译英文,而不能编译中文,编译器只能编译8位二进制的ASCII字符集,如果给它16位的unicode字符集,它就不知道怎么编了!怎样解决呢?这时候出现了UTF8,UTF8较之unicode就是比较有弹性了,并不是像unicode那样,一个字符为了统一必须得使用16位进行存储。
UTF8在存储英文字符时使用8位,存储中文时使用24位,就是这么神奇!其实想想也没啥神奇的,仅是UTF8顺应了ASCII字符集编码而已,这样的话,编译器就能识别通过utf8写的程序的,当然,仅仅是识别用英文写的代码,还是不能识别中文。
假设我在记事本里面存储zhang,通过ASCII字符集进行存储,会占用40个bit,也就是5个B(字节)
假设我在记事本里面存储zhang,通过unicode字符集进行存储,会占用5*16=80,也就是10个B(字节)
假设我在记事本里面存储zhang,通过UTF8字符集进行存储,会占用40个bit,也就是5个B(字节)
NOTE:记事本结尾也有一个占位符号。
mysql与字符集
#查看数据库支持的字符集
show character set; 
我们还可以服务器的默认字符集,当我们创建数据库的时候,如果不指定字符集就会继承服务器的字符集。
当我们创建数据表的时候,如果不指定字符集就会继承数据库的字符集。
当我们创建数据列的时候,如果不指定字符集就会继承表的字符集
client和connection字符集的关系
character_set_client指的是客户端字符集,什么是客户端字符集呢?
比如我们通过CRT或者XSHELL连接数据库我们就是客户端,通过客户端给MYSQL服务器发送的命令编码的时候就是通过上图显示的latin1进行编码,通过客户端字符集进行编码完成之后,在向服务器发送的时候使用什么字符集还取决于character_set_connection的字符集,如果两者不一样,还要进行转换,不过一般这都是一样的,转换起来效率太低了。
MYSQL服务器收到之后就得解码,解码的字符集也需要和客户端一样或者范围大于,解码完成之后,向数据库,表存储的时候还要取决于存储时的字符集,如果不一样,解码之后还要重新进行编码。
服务器会迁就客户端的字符集。
查看服务器级别的字符集:
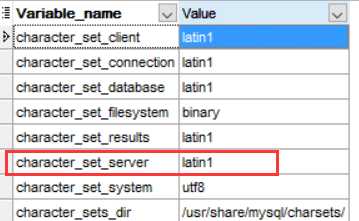
新创建的数据库TEST2继承了latin1
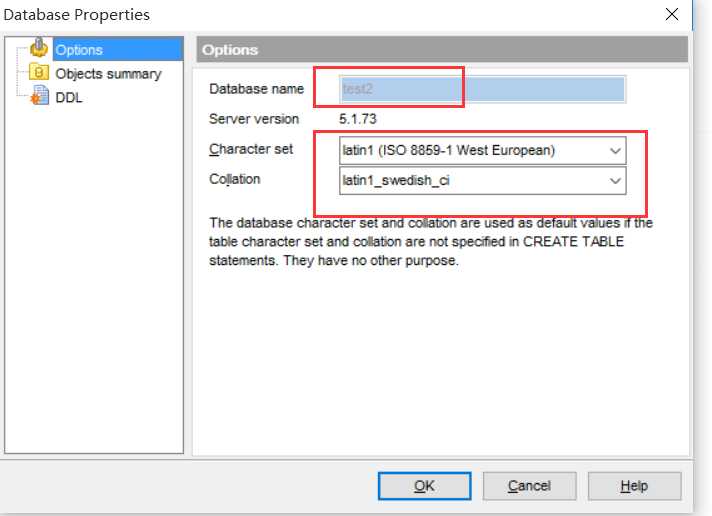
服务器级别的默认字符集当前是latin11,我们下面将其改变成UTF8.
root@zhanghe ~]# vim /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
user=mysql
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
default-character-set=utf8 #加了这一行
[mysqld_safe]
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
[root@zhanghe ~]# /etc/init.d/mysqld restart
mysql> show variables like 'character_set_%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | latin1 |
| character_set_connection | latin1 |
| character_set_database | utf8 | #变了
| character_set_filesystem | binary |
| character_set_results | latin1 |
| character_set_server | utf8 | #变了
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+新建的数据库如下所示,就变成了UTF8了,之前的数据库字符集没有变化。
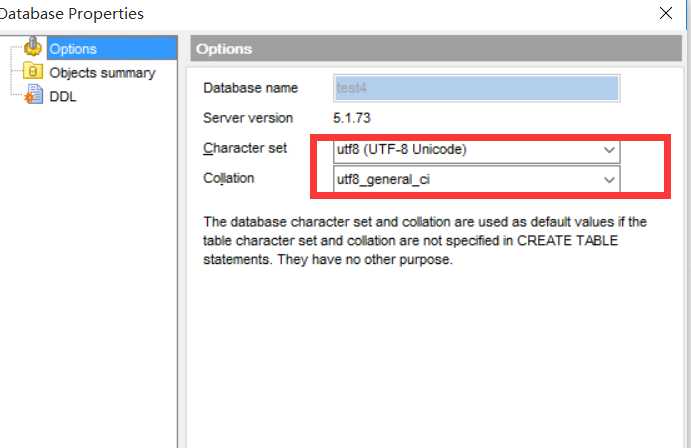
create database test5 default charset latin1; 创建数据库的时候指定字符集
create table student 创建表的时候指定字符集
(
sid INT,
sname char(10),
adress char(20) character set latin1 列也可以不继承表
)default charset utf8 指定表的字符集
alter detabase db character set 'latin1' 直接更改更改数据库的字符集是latin1
alter table student character set 'latin1' 直接更改表的字符集
alter table student change address address character char(20)) sets 'utf8' 直接更改列的字符集 更改数据库默认字符集对现有表的字符集没有影响,只会影响新建表的默认字符集。
总结
更改表的默认字符集,对表中现在列的字符集没有影响,只会影响在表中新增列的默认字符集。
更改列的字符集,不会更改列中存储的数据,现在数据还是以以前的字符集编码存储,但你的数据库会使用新的字符集解码,将会产生乱码,以后在列中插入的数据将会使用新的字符集编码存储,一般不要轻易更改列的字符集。
以上是关于字符集专题的主要内容,如果未能解决你的问题,请参考以下文章
2021-12-24:划分字母区间。 字符串 S 由小写字母组成。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。返回一个表示每个字符串片段的长度的列表。 力扣763。某大厂面试