PaddleHub提供的ERNIE进行文本分类
Posted xiximayou
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PaddleHub提供的ERNIE进行文本分类相关的知识,希望对你有一定的参考价值。
可直接在百度的aistudio中进行实验:
地址:https://aistudio.baidu.com/aistudio/projectdetail/305830
ERNIE 通过建模海量数据中的词、实体及实体关系,学习真实世界的语义知识。相较于 BERT 学习原始语言信号,ERNIE 直接对先验语义知识单元进行建模,增强了模型语义表示能力,以 Transformer 为网络基本组件,以Masked Bi-Language Model和 Next Sentence Prediction 为训练目标,通过预训练得到通用语义表示,再结合简单的输出层,应用到下游的 NLP 任务。本示例展示利用ERNIE进行文本分类任务。
1、导入需要的包:在jupyter notebook中安装所需的包需要在前面加上感叹号,如果是本地,直接pip即可
!pip install --upgrade paddlehub -i https://pypi.tuna.tsinghua.edu.cn/simple
2、下载模型
#下载ernie的module !hub install ernie
3、导入模型和数据集
# -*- coding: utf8 -*- import paddlehub as hub module = hub.Module(name="ernie") dataset = hub.dataset.ChnSentiCorp()
在PaddleHub中选择ernie作为预训练模型,进行Fine-tune。ChnSentiCorp数据集是一个中文情感分类数据集。PaddleHub已支持加载该数据集。关于该数据集,详情请查看ChnSentiCorp数据集使用。
还可以尝试其它的一些模型:只需要在Module中传入name参数

也可以自己定义数据集:详细参见自定义数据集
4、生成Reader
接着生成一个文本分类的reader,reader负责将dataset的数据进行预处理,首先对文本进行切词,接着以特定格式组织并输入给模型进行训练。
ClassifyReader的参数有以下三个:
dataset: 传入PaddleHub Dataset;vocab_path: 传入ERNIE/BERT模型对应的词表文件路径;max_seq_len: ERNIE模型的最大序列长度,若序列长度不足,会通过padding方式补到max_seq_len, 若序列长度大于该值,则会以截断方式让序列长度为max_seq_len;
reader = hub.reader.ClassifyReader( dataset=dataset, vocab_path=module.get_vocab_path(), max_seq_len=128)
NOTE: Reader参数max_seq_len、moduel的context接口参数max_seq_len三者应该保持一致,最大序列长度max_seq_len是可以调整的参数,建议值128,根据任务文本长度不同可以调整该值,但最大不超过512。
5、选择优化策略(Fine-Tune)
用于ERNIE/BERT这类Transformer模型的迁移优化策略为AdamWeightDecayStrategy。详情请查看Strategy。
AdamWeightDecayStrategy的参数有以下三个:
learning_rate: 最大学习率lr_scheduler: 有linear_decay和noam_decay两种衰减策略可选warmup_proprotion: 训练预热的比例,若设置为0.1, 则会在前10%的训练step中学习率逐步提升到learning_rateweight_decay: 权重衰减,类似模型正则项策略,避免模型overfittingoptimizer_name: 优化器名称,使用Adam
strategy = hub.AdamWeightDecayStrategy( weight_decay=0.01, warmup_proportion=0.1, learning_rate=5e-5)
PaddleHub提供了许多优化策略,如AdamWeightDecayStrategy、ULMFiTStrategy、DefaultFinetuneStrategy等,详细信息参见策略
6、选择运行时配置
在进行Finetune前,我们可以设置一些运行时的配置,例如如下代码中的配置,表示:
-
use_cuda:设置为False表示使用CPU进行训练。如果您本机支持GPU,且安装的是GPU版本的PaddlePaddle,我们建议您将这个选项设置为True; -
epoch:要求Finetune的任务只遍历1次训练集; -
batch_size:每次训练的时候,给模型输入的每批数据大小为32,模型训练时能够并行处理批数据,因此batch_size越大,训练的效率越高,但是同时带来了内存的负荷,过大的batch_size可能导致内存不足而无法训练,因此选择一个合适的batch_size是很重要的一步; -
log_interval:每隔10 step打印一次训练日志; -
eval_interval:每隔50 step在验证集上进行一次性能评估; -
checkpoint_dir:将训练的参数和数据保存到ernie_txt_cls_turtorial_demo目录中; -
strategy:使用DefaultFinetuneStrategy策略进行finetune;
更多运行配置,请查看RunConfig
config = hub.RunConfig( use_cuda=True, num_epoch=1, checkpoint_dir="ernie_txt_cls_turtorial_demo", batch_size=100, eval_interval=50, strategy=strategy)
7、组建微调任务
有了合适的预训练模型和准备要迁移的数据集后,我们开始组建一个Task。
- 获取module的上下文环境,包括输入和输出的变量,以及Paddle Program;
- 从输出变量中找到用于情感分类的文本特征pooled_output;
- 在pooled_output后面接入一个全连接层,生成Task;
inputs, outputs, program = module.context( trainable=True, max_seq_len=128) # Use "pooled_output" for classification tasks on an entire sentence. pooled_output = outputs["pooled_output"] feed_list = [ inputs["input_ids"].name, inputs["position_ids"].name, inputs["segment_ids"].name, inputs["input_mask"].name, ] cls_task = hub.TextClassifierTask( data_reader=reader, feature=pooled_output, feed_list=feed_list, num_classes=dataset.num_labels, config=config)
如果想改变迁移任务组网,详细参见自定义迁移任务
8、开始微调
我们选择finetune_and_eval接口来进行模型训练,这个接口在finetune的过程中,会周期性的进行模型效果的评估,以便我们了解整个训练过程的性能变化。
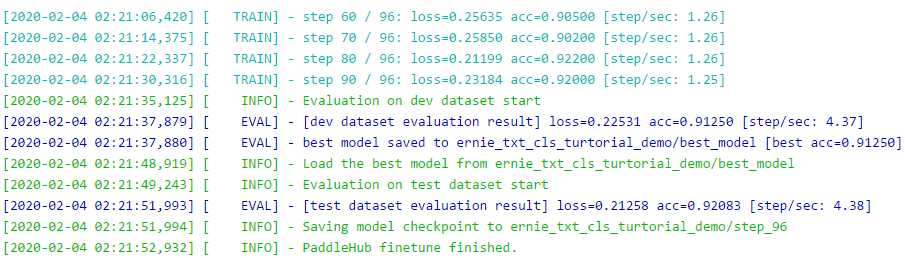
run_states = cls_task.finetune_and_eval()
9、使用模型进行预测
import numpy as np # Data to be prdicted data = [ ["这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般"], ["交通方便;环境很好;服务态度很好 房间较小"], [ "还稍微重了点,可能是硬盘大的原故,还要再轻半斤就好了。其他要进一步验证。贴的几种膜气泡较多,用不了多久就要更换了,屏幕膜稍好点,但比没有要强多了。建议配赠几张膜让用用户自己贴。" ], [ "前台接待太差,酒店有A B楼之分,本人check-in后,前台未告诉B楼在何处,并且B楼无明显指示;房间太小,根本不像4星级设施,下次不会再选择入住此店啦" ], ["19天硬盘就罢工了~~~算上运来的一周都没用上15天~~~可就是不能换了~~~唉~~~~你说这算什么事呀~~~"] ] index = 0 run_states = cls_task.predict(data=data) results = [run_state.run_results for run_state in run_states] for batch_result in results: # get predict index batch_result = np.argmax(batch_result, axis=2)[0] for result in batch_result: print("%s predict=%s" % (data[index][0], result)) index += 1
[2020-02-04 02:21:52,942] [ INFO] - The best model has been loaded [2020-02-04 02:21:52,944] [ INFO] - PaddleHub predict start share_vars_from is set, scope is ignored. [2020-02-04 02:21:53,007] [ INFO] - PaddleHub predict finished. 这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般 predict=0 交通方便;环境很好;服务态度很好 房间较小 predict=1 还稍微重了点,可能是硬盘大的原故,还要再轻半斤就好了。其他要进一步验证。贴的几种膜气泡较多,用不了多久就要更换了,屏幕膜稍好点,但比没有要强多了。建议配赠几张膜让用用户自己贴。 predict=0 前台接待太差,酒店有A B楼之分,本人check-in后,前台未告诉B楼在何处,并且B楼无明显指示;房间太小,根本不像4星级设施,下次不会再选择入住此店啦 predict=0 19天硬盘就罢工了~~~算上运来的一周都没用上15天~~~可就是不能换了~~~唉~~~~你说这算什么事呀~~~ predict=0
分为正面的和负面的两类。
以上是关于PaddleHub提供的ERNIE进行文本分类的主要内容,如果未能解决你的问题,请参考以下文章