Lua 截取字符串(截取utf-8格式字符串)
Posted yougoo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Lua 截取字符串(截取utf-8格式字符串)相关的知识,希望对你有一定的参考价值。
对utf-8完全没概念的可以看看我上一篇随笔:
另外,还要知道string.sub 和 string.byte 的用法。


先上完整代码:
local StringHelper = {}
--[[
utf-8编码规则
单字节 - 0起头
1字节 0xxxxxxx 0 - 127
多字节 - 第一个字节n个1加1个0起头
2 字节 110xxxxx 192 - 223
3 字节 1110xxxx 224 - 239
4 字节 11110xxx 240 - 247
可能有1-4个字节
--]]
function StringHelper.GetBytes(char)
if not char then
return 0
end
local code = string.byte(char)
if code < 127 then
return 1
elseif code <= 223 then
return 2
elseif code <= 239 then
return 3
elseif code <= 247 then
return 4
else
-- 讲道理不会走到这里^_^
return 0
end
end
function StringHelper.Sub(str, startIndex, endIndex)
local tempStr = str
local byteStart = 1 -- string.sub截取的开始位置
local byteEnd = -1 -- string.sub截取的结束位置
local index = 0 -- 字符记数
local bytes = 0 -- 字符的字节记数
startIndex = math.max(startIndex, 1)
endIndex = endIndex or -1
while string.len(tempStr) > 0 do
if index == startIndex - 1 then
byteStart = bytes+1;
elseif index == endIndex then
byteEnd = bytes;
break;
end
bytes = bytes + StringHelper.GetBytes(tempStr)
tempStr = string.sub(str, bytes+1)
index = index + 1
end
return string.sub(str, byteStart, byteEnd)
end
基本思路:
之所以要自己写一个截取函数,是因为lua的库函数string.sub实际是字节的截取函数。
uft-8编码格式中,大部分中文是3个字节表示的,数字和字母等是一个字节的,还有某些国家的语言是2字节的,直接用string.sub就可能截出乱码来,因为不确定要截多少个字节。
所以,
定义一个GetBytes函数,获取字符的字节数(根据首个字节的高位标记,判断是几字节的字符)
然后不断后移,记录字节数和字符数。
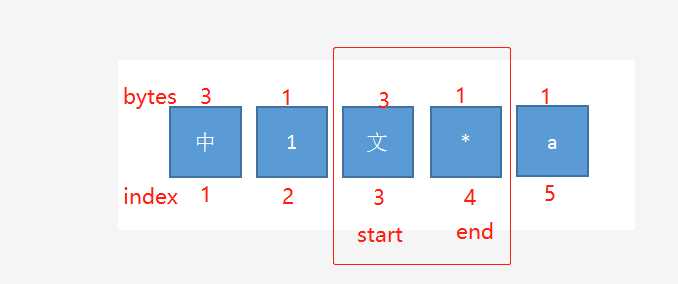
如上图,假设要取字符3-4,那么应该从第3个字符的第一个字节取到第4个字最后一个字节
即:
当前字符数为截取的起始字符(startIndex)前一个位置时,说明从下一个字节开始截取字符串 即 index == startIndex - 1 时 byteStart = bytes+1
当前字符数为截取的终止字符(endIndex)时,说明要截取的字符串到此为止 即 index == endIndex 时 byteEnd = bytes
用 string.sub(str, byteStart, byteEnd) 就能截取byteStart 到 byteEnd 的字节
测试代码:
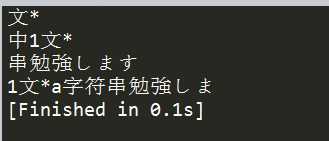
str = "中1文*a字符串勉強します"; print(StringHelper.Sub(str, 3, 4)) print(StringHelper.Sub(str, 1, 4)) print(StringHelper.Sub(str, 8)) print(StringHelper.Sub(str, 2, 12))
测试结果:
以上是关于Lua 截取字符串(截取utf-8格式字符串)的主要内容,如果未能解决你的问题,请参考以下文章