SIGAI机器学习第四集 基本概念
Posted wisir
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SIGAI机器学习第四集 基本概念相关的知识,希望对你有一定的参考价值。
大纲:
算法分类
有监督学习与无监督学习
分类问题与回归问题
生成模型与判别模型
强化学习
评价指标
准确率与回归误差
ROC曲线
交叉验证
模型选择
过拟合与欠拟合
偏差与方差
正则化
半监督学习归类到有监督学习中去。
有监督学习大部分问题都是分类问题,有监督中的分类问题分为生成式模型和判别模型。
分类问题常用的评价指标是准确率,对于回归问题常用的评价指标是回归误差均方误差。
二分类问题中常为它做ROC曲线。
过拟合通用的解决手段是正则化。
算法分类:
监督信号,就是样本的标签值,根据知否有标签值将机器学习分类为有监督学习、无监督学习、半监督学习。
有监督学习与无监督学习:
有监督学习分两个过程:训练和预测。
预测根据输入样本(x,y),训练出一个模型y=f(x)来预测新的样本的标签值。
无监督学习:聚类和数据降维。
数据降维是为了避免维数灾难,高维数据算法处理起来比较困难,数据之间具有相关性。
强化学习:
是从策略控制领域诞生出来的一种算法,它根据环境数据预测动作,目标是最大化奖励值。
分类问题与回归问题:
有监督学习分为分类问题和回归问题,如判断一个水果的类别就是分类问题,根据个人信息预测收入就是回归问题。
分类问题:
Rn-->Z,把n维向量映射为一个整数值,该值对应一个分类。
人脸检测就是而分类问题,图像中某个位置区域是人脸还是不是人脸。
二分类问题最简单办法是找到一个直线方程进行分类,线性分类器sgn(wTx+b),输出+1或-1。
回归问题:
Rn-->R,R是要预测的实数值。
最简单的算法是线性回归f(x)=wTx+b,相比分类问题省去了sgn函数。
损失函数也叫误差函数,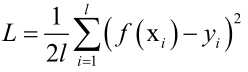 ,几乎对于所有的有监督学习,它的目标都是最小化损失函数或者最大化的对数似然函数,在确定了这个优化目标以后,工作就完成一半了,剩下的就是完成最优化求解问题了,可以标准的算法如梯度下降法、牛顿法等,根据自己算法的特点选用一个合适的最优化算法来求解,这是标准化的流程,求解完之后,就求解出了f(x)参数值完成了训练,之后就可以用f(x)来预测新的样本用来做分类或者回归。
,几乎对于所有的有监督学习,它的目标都是最小化损失函数或者最大化的对数似然函数,在确定了这个优化目标以后,工作就完成一半了,剩下的就是完成最优化求解问题了,可以标准的算法如梯度下降法、牛顿法等,根据自己算法的特点选用一个合适的最优化算法来求解,这是标准化的流程,求解完之后,就求解出了f(x)参数值完成了训练,之后就可以用f(x)来预测新的样本用来做分类或者回归。
线性回归:
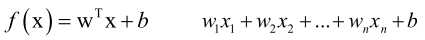 ,是一个线性函数。
,是一个线性函数。
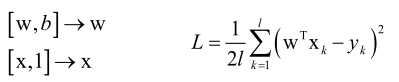
训练的目标是最小化均方误差MSE,训练的时候要求解的是一个无约束条件的凸优化问题(要证明是均方误差损失函数是凸函数,就要证明它的Hession矩阵半正定),凸优化问题就可以找到L的全局极小值点。
证明MSE损失函数是凸函数:
求L的Hession矩阵:
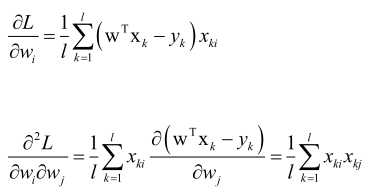
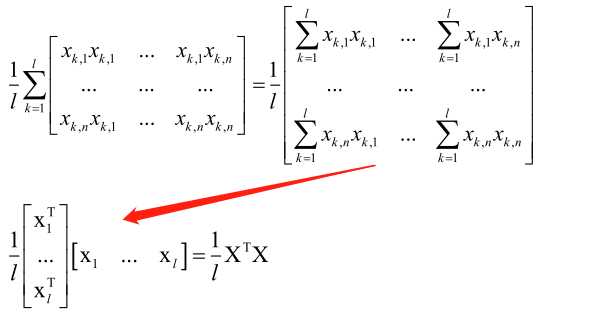
1/lXTX矩阵对应的二次型为xT1/lXTXx,即1/l(xTXT)(Xx),即(Xx)T(Xx),由于(Xx)T是一个行向量,(Xx)是列向量,它们两个相乘是向量做内积,大于等于零,所以Hession矩阵半正定,所以MSE损失函数L是凸函数,存在全局极小值点。
生成模型与判别模型:
对于分类问题按照求解思路可以把它分为两种类型:
①判别模型,直接根据函数判断它是属于哪一个模型。
第一种是y=f(x),直接根据一个预测函数sgn(wT+b)预测出标签值y来。
第二种是p(y|x),算它的后验概率,根据特征x计算它属于每个类的概率,根据特征反推它所属的类,这就是后验概率。
②生成模型
对x、y联合分布建模,p(x,y)=p(x|y)p(y),即假设x服从某种分布对p(x|y)、p(y)进行建模。
生成模型的另一种定义是用来生成数据的算法,如GAN。
判别模型和生成模型区别:
判别模型是求p(y|x),生成模型是求p(x|y)。
学习的大部分的分类算法都是判别模型。
生成模型:贝叶斯分类器,高斯混合模型,隐马尔可夫模型,受限玻尔兹曼机,生成对抗网络等。
判别模型:决策树,kNN算法,人工神经网络,支持向量机,logistic回归,AdaBoost算法等(虽然logistic中用到概率了,但是它是直接计算的p(y|x),即样本属于某类的概率,并没有假设x服从某种概率分布对p(x|y)、p(y)进行建模)。
在解决分类问题时是有本质区别的:
判别模型直接找一个分界线出来,至于两边样本服从哪一种分布,哪里密集哪里稀疏并不关注。生成模型是先算出两边样本服从的分布,再来算样本属于某个类的概率的。
评价指标:
因为要比较算法的优劣,所以引入评价指标。对于同一类问题可能有不同的算法都可以解决它,要判断哪一种算法更好,其中衡量的一个依据就是它的准确率或是叫精度,还有另一个指标是算法的速度。
对于分类和回归问题它的精度的定义是不一样的。
对于分类问题用准确率表示,即正确分类的样本数/测试样本总数,样本分为训练集和测试集,用测试集(和训练集不相交)来统计准确率,因为用训练集统计准确率是没有意义的。
回归误差是回归问题的评价指标,因为分类问题是一个是和否的问题,而回归问题它是一个连续实数值,不能用是和否来回答,所以用回归误差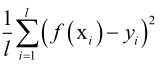 。
。
准确率与回归误差:
以上是关于SIGAI机器学习第四集 基本概念的主要内容,如果未能解决你的问题,请参考以下文章