学号20182317 2019-2020-1 《数据结构与面向对象程序设计》第十周学习总结
Posted pytznb
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学号20182317 2019-2020-1 《数据结构与面向对象程序设计》第十周学习总结相关的知识,希望对你有一定的参考价值。
学号20182317 2019-2020-1 《数据结构与面向对象程序设计》第十周学习总结
教材学习内容总结
三种常用的查找算法(顺序查查找,折半查找,二叉排序树查找)
图
基本概念:
1、顶点(vertex)
- 表示某个事物或对象。由于图的术语没有标准化,因此,称顶点为点、节点、结点、端点等都是可以的。
2、边(edge)
- 通俗点理解就是两个点相连组合成一条边,表示事物与事物之间的关系。需要注意的是边表示的是顶点之间的逻辑关系,粗细长短都无所谓的。包括上面的顶点也一样,表示逻辑事物或对象,画的时候大小形状都无所谓。
3、同构(Isomorphism )
- 这两个图看起来是完全不一样的但是从图(graph)的角度出发,这2个图是一样的,即它们是同构的。前面提到顶点和边指的是事物和事物的逻辑关系,不管顶点的位置在哪,边的粗细长短如何,只要不改变顶点代表的事物本身,不改变顶点之间的逻辑关系,那么就代表这些图拥有相同的信息,是同一个图。同构的图区别仅在于画法不同。
4、有向/无向图(Directed Graph/ Undirected Graph)
- 最基本的图通常被定义为“无向图”,与之对应的则被称为“有向图”。两者唯一的区别在于,有向图中的边是有方向性的。有向图和无向图的许多原理和算法是相通的
- 以下是有向图和无向图的邻接表
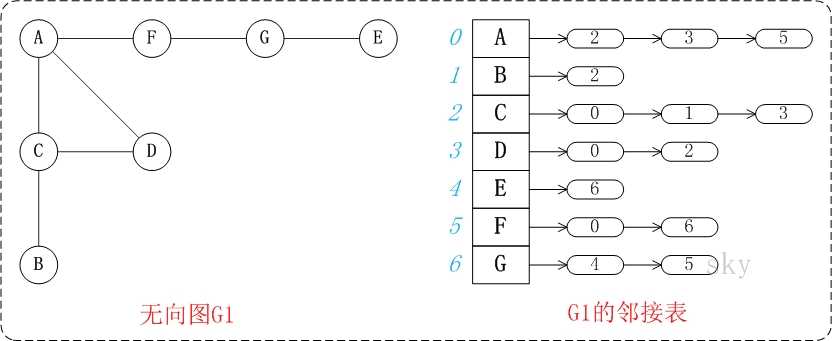
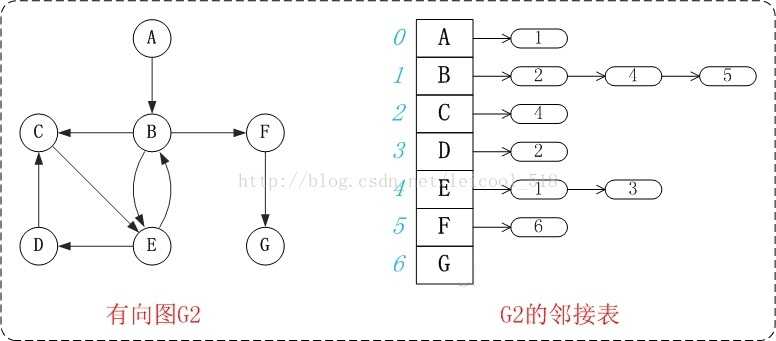
5、常用的图算法:
- 广度优先遍历(breadth-first traversal) : 类似于树的层次遍历
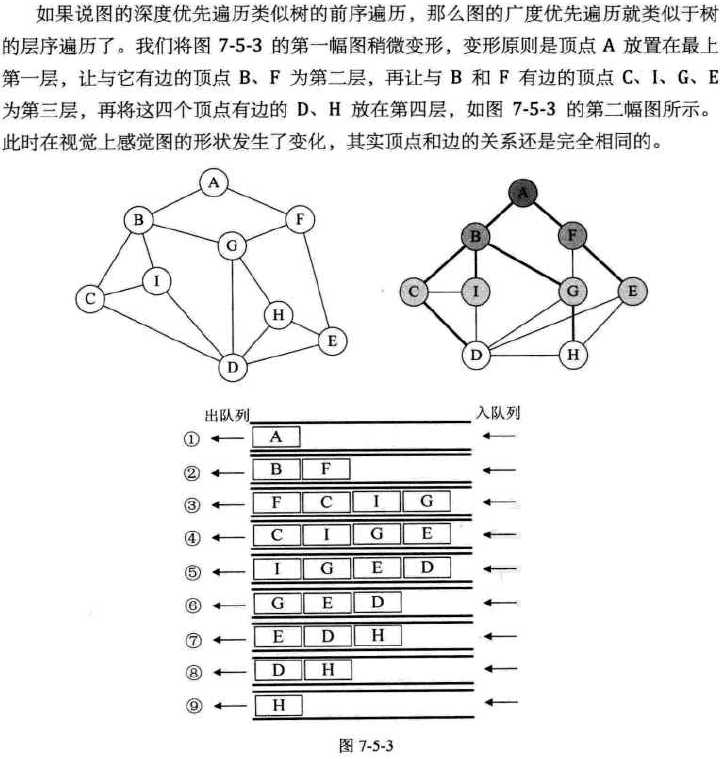
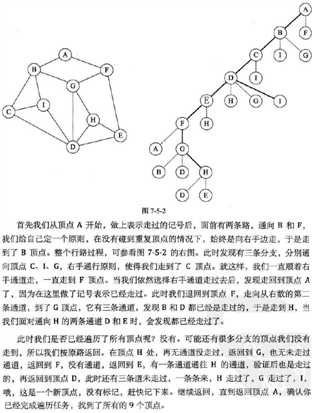
- 深度优先遍历(depth-first traversal) : 类似于树的前序遍历。
教材学习中的问题和解决过程
- 问题1:图的应用跟队列等线性结构有什么区别
问题1解决方案:图是非线性结构,在进行排序和查找的时候时间复杂度更低,且稳定性更高一点
- 问题2:为什么深度优先遍历在顶点尚未添加到 resultList之前,并不想标记该顶点为visited?
问题2解决方案:从图的某个顶点v出发,访问此顶点,然后从v的未被访问过的邻接点出发深度优先遍历图,直至图中的所有和v有路径相通的顶点都被访问到(对于连通图来讲)
广度优先遍历中,顶点进入队列然后标记为已访问,然后开始循环,该循直持续到队列为空时停止,在这个循环中,从队列中取出这个首顶点,并将它添加到 resultList的末端
而深度优先遍历不同的就在这里:在顶点尚未添加到 resultList之前,并不想标记该顶点为visited
代码调试中的问题和解决过程
- 问题1:拓扑排序的代码编写
- 问题1解决方案:
public int topologicalSort() {
int index = 0;
int num = mVexs.size();
int[] ins; // 入度数组
char[] tops; // 拓扑排序结果数组,记录每个节点的排序后的序号。
Queue<Integer> queue; // 辅组队列
ins = new int[num];
tops = new char[num];
queue = new LinkedList<Integer>();
// 统计每个顶点的入度数
for(int i = 0; i < num; i++) {
ENode node = mVexs.get(i).firstEdge;
while (node != null) {
ins[node.ivex]++;
node = node.nextEdge;
}
}
// 将所有入度为0的顶点入队列
for(int i = 0; i < num; i ++)
if(ins[i] == 0)
queue.offer(i); // 入队列
while (!queue.isEmpty()) { // 队列非空
int j = queue.poll().intValue(); // 出队列。j是顶点的序号
tops[index++] = mVexs.get(j).data; // 将该顶点添加到tops中,tops是排序结果
ENode node = mVexs.get(j).firstEdge;// 获取以该顶点为起点的出边队列
// 将与"node"关联的节点的入度减1;
// 若减1之后,该节点的入度为0;则将该节点添加到队列中。
while(node != null) {
// 将节点(序号为node.ivex)的入度减1。
ins[node.ivex]--;
// 若节点的入度为0,则将其"入队列"
if( ins[node.ivex] == 0)
queue.offer(node.ivex); // 入队列
node = node.nextEdge;
}
}
if(index != num) {
System.out.printf("Graph has a cycle
");
return 1;
}
// 打印拓扑排序结果
System.out.printf("== TopSort: ");
for(int i = 0; i < num; i ++)
System.out.printf("%c ", tops[i]);
System.out.printf("
");
return 0;
}代码托管
(statistics.sh脚本的运行结果截图)
上周考试错题总结
上周无测试
结对及互评
- 博客中值得学习的或问题:
- 问题总结做得很全面:对课本上不懂的代码会做透彻的分析,即便可以直接拿过来用而不用管他的含义
- 对教材中的细小问题都能够关注,并且主动去百度学习
- 代码中值得学习的或问题:
- 对于编程的编写总能找到角度去解决
评分标准
- 基于评分标准,我给本博客打分:14分。得分情况如下:
正确使用Markdown语法(加1分):
不使用Markdown不加分
有语法错误的不加分(链接打不开,表格不对,列表不正确...)
排版混乱的不加分
- 模板中的要素齐全(加1分)
- 缺少“教材学习中的问题和解决过程”的不加分
- 缺少“代码调试中的问题和解决过程”的不加分
- 代码托管不能打开的不加分
- 缺少“结对及互评”的不能打开的不加分
- 缺少“上周考试错题总结”的不能加分
- 缺少“进度条”的不能加分
- 缺少“参考资料”的不能加分
教材学习中的问题和解决过程, 一个问题加1分
代码调试中的问题和解决过程, 一个问题加1分
- 本周有效代码超过300分行的(加2分)
- 一周提交次数少于20次的不加分
- 其他加分:
- 感想,体会不假大空的加1分
- 排版精美的加一分
- 进度条中记录学习时间与改进情况的加1分
- 有动手写新代码的加1分
- 课后选择题有验证的加1分
- 代码Commit Message规范的加1分
- 错题学习深入的加1分
- 点评认真,能指出博客和代码中的问题的加1分
- 结对学习情况真实可信的加1分
点评过的同学博客和代码
- 本周结对学习情况
- 对队列的一些讨论和学习。包括链表和数组实现队列,入队、出队等等
- 上周博客互评情况
经过本周的学习,我对曾经学过的知识有了更深一步的了解同时对数据查找和排序等方法的应用也更加熟悉,同时也弄懂了一些过去不是很懂的知识点可谓是受益匪浅。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 126/126 | 2/2 | 20/20 | |
| 第二周 | 0/126 | 2/2 | 20/40 | |
| 第三周 | 353/479 | 2/6 | 20/60 | |
| 第四周 | 1760/2239 | 2/8 | 30/90 | |
| 第五周 | 1366/3615 | 2/10 | 20/110 | |
| 第六周 | 534/4149 | 2/12 | 20/130 | |
| 第七周 | 2800/6949 | 2/12 | 20/150 | |
| 第八周 | 883/7832 | 2/14 | 20/170 | |
| 第九周 | 2550/10382 | 2/16 | 20/190 | |
| 第十周 | 2219/12601 | 2/18 | 20/210 |
参考资料
以上是关于学号20182317 2019-2020-1 《数据结构与面向对象程序设计》第十周学习总结的主要内容,如果未能解决你的问题,请参考以下文章