第31课 std::atomic原子变量
Posted 5iedu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第31课 std::atomic原子变量相关的知识,希望对你有一定的参考价值。
一. std::atomic_flag和std::atomic
(一)std::atomic_flag
1. std::atomic_flag是一个bool类型的原子变量,它有两个状态set和clear,对应着flag为true和false。
2. std::atomic_flag使用前必须被ATOMIC_FLAG_INIT初始化,此时的flag为clear状态,相当于静态初始化。
3. 三个原子化操作
(1)test_and_set():检查当前flag是否被设置。若己设置直接返回true,若没设置则将flag置为true ,并返回false。
(2)clear();清除flag标志,即flag=false。
(3)析构函数
4. 和所有atomic类型一样,std::atomic_flag不支持拷贝和赋值等操作。因为赋值和拷贝调用了两个对象,从第一个对象中读值,然后再写入另一个。对于两个独立的对象,这里就有两个独立的操作,合并这两个操作必定不是原子的。
5. std::atomic_flag 类型不提供is_lock_free()。 该类型是一个简单的布尔标志, 并且在这种类型上的操作都是无锁的。但atomic_flag的可操作性不强,导致其应用局限性,还不如std::atomic<bool>。
(二)std::atomic<T>模板类
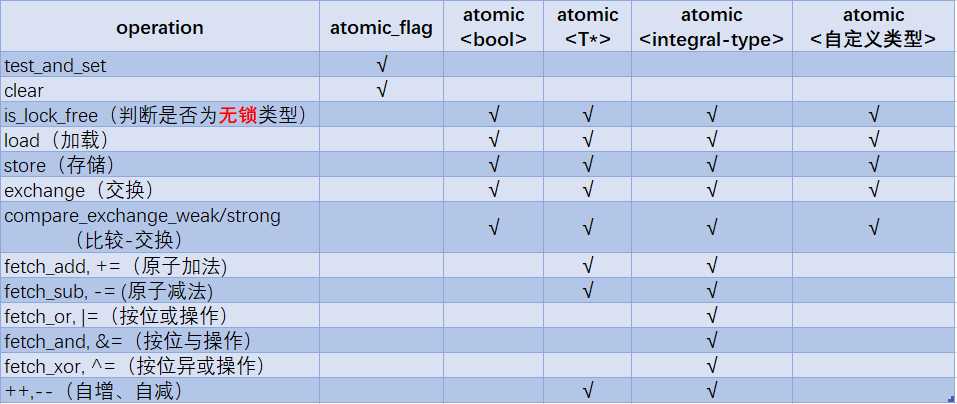
1. std::atomic_flag是无锁类型的,但是atomic<bool>不一定是lock free的,可以用atomic<T>::is_lock_free()来判断。通常情况下,编译器不会为std::atomic<UDT>生成无锁代码,所有操作使用一个内部锁(UDT为用户自定义类型,如果其类型大小如同int或void*时,大多数平台仍会使用原子指令)。
2. fetch_系列函数返回的是旧值,复合赋值运算返回的是新值,但它们返回的都不是引用类型。因为任何依赖与这个结果的代码都需要显式加载该值。潜在的问题是,结果可能会被其他线程修改。而通过非原子值进行赋值,可以避免多余的加载过程,并且得到实际存储的值。
3. compare_exchange_weak/strong函数可以保证“比较-交换”的原子化。compare_exchange_weak可能失败,即此函数可能与expected值相等的情形下atomic的T值没有替换为disired(atomic值未变)且返回false,这可能发生在缺少单条CAS操作(“比较-交换”指令)的机器上,所以通常使用一个循环中。


bool compare_exchange_strong(T& expected, const T desired) volatile noexcept { if (*this == expected) *this = desired; else expected = *this; return (*this == expected) }
4. 整数原子类型没有乘法、除法、位移操作,因为整数原子类型通常用于计数或者掩码等,如果需要,可以将compare_change_weak()放入循环中完成。
5. std::atomic<UDT>,UDT类不能有任何虚函数或虚基类,以及必须使用编译器创建的拷贝赋值操作。所有的基类和非静态数据成员也都需要支持拷贝赋值操作。其比较-交换操作就类似于memcmp使用按位比较,而非为UDT类定义一个比较操作符。
6. 每个函数的操作都有一个内存排序参数。这个参数可以用来指定存储的顺序。
(1)store操作,可选如下顺序:memory_order_relaxed、memory_order_release、memory_order_seq_cst。
(2)load操作,可选顺序:memory_order_relaxed、memory_order_consume、memory_order_acquire和memory_order_seq_cst。
(3)读-改-写操作(RMW):memory_order_relaxed、memory_order_consume、memory_order_acquire、memory_order_release、memory_order_acq_rel和memory_order_seq_cst。
【编程实验】std::atomic<T> 初体验
#include <atomic> #include <thread> #include <iostream> #include <vector> #include <sstream> #include <cassert> //自己封装的自旋锁 class spinlock { std::atomic_flag flag = ATOMIC_FLAG_INIT; public: void lock() { while (flag.test_and_set(std::memory_order_acquire)) { std::this_thread::yield(); } } void unlock() { flag.clear(std::memory_order_release); } }; spinlock g_lock; std::stringstream stream; void append_number(int x) { g_lock.lock(); stream << "thread(" << std::this_thread::get_id() << "): " << x << " "; g_lock.unlock(); } std::vector<int> data; std::atomic<bool> data_read(false); void reader_thread() { while (!data_read.load()) { std::this_thread::sleep_for(std::chrono::microseconds(1)); } std::cout << "The answer=" << data[0] << std::endl; //1 } void writer_thread() { data.push_back(42); //2。 由于1和2处发生了data race,所以使用atomic<boo>进行同步。 data_read = true; } class Foo{}; //线程安全的简单链表 struct linkList { struct Node { int value; Node* next; }; void append(int val) { Node* newNode = new Node{val,list_head }; //将头结点移动到newNode的后面(即next下) //注意,由于线程的data race,这里可能出现多个线程 //同时创建新结点,并将newNode->next = list_head // 头插法 //这里需要用while循环,因为第1个抢到compare_exchange_strong的线程,会成功将list_head改为 //newNode,使得newNode成为新的list_head(头插法) 。而其余线程第1次调用compare_exchange_strong //时会因为newNode->next不等于新的list_head而失败,该函数会将新的list_head挂在newNode->next下面, //如此当再次循环时,就能够成功将newNode设置为新的list_head(这里可能再次遇到data race,会重复上述 //过程,直到成功)。 while (!(list_head.compare_exchange_strong(newNode->next, newNode))); //函数体为空 } void print() { for (Node* it = list_head; it != nullptr; it = it->next) { std::cout << " " << it->value; } std::cout << std::endl; } void clear() { Node* it; while (it = list_head) { list_head = it->next; delete it; } } std::atomic<Node*> list_head = nullptr; }; std::atomic<int> g_count = 0; void test() { for (int i = 0; i < 100000; ++i) { //count++; //原子操作 //g_count += 1; //原子操作 g_count = g_count + 1; //注意,不是原子操作 } } int main() { //1. 自旋琐的实现 std::vector<std::thread> threads; for (int i = 1; i < 10; ++i) { threads.push_back(std::thread(append_number, i)); } for (auto& th : threads) th.join(); std::cout << stream.str(); //2. std::atomic<bool>的使用 std::thread reader(reader_thread); std::thread writer(writer_thread); reader.join(); writer.join(); //3. std::atomic<T*>的使用(指针的原子相加减操作) Foo fArr[5]; std::atomic<Foo*> pF(fArr); Foo* x = pF.fetch_add(2); //fetch_add返回旧值,即x==fArr assert(x == fArr); x = (pF -= 1); //x ==pF == &fArr[1]; assert(x == &fArr[1]); assert(pF.load() == &fArr[1]); //4. 线程安全链表 std::vector<std::thread> ths; linkList lst; for (int i = 0; i < 10; ++i) ths.push_back(std::thread(&linkList::append, &lst, i)); for (auto& th : ths) th.join(); //打印内容 lst.print(); lst.clear(); //5.原子和非原子的加减操作 std::thread t1(test); std::thread t2(test); t1.join(); t2.join(); std::cout << g_count << std::endl; return 0; } /*输出结果 thread(10120): 1 thread(15320): 3 thread(18112): 2 thread(6668): 6 thread(11856): 5 thread(18100): 7 thread(5124): 4 thread(13808): 8 thread(7528): 9 The answer=42 8 4 9 7 6 5 3 0 2 1 109388 */
二. 内存屏障与同步
(一)乱序的原因
从源码变成可以被机器识别的程序,至少要经过编译期和运行期。重排序分为两类:编译期重排序和运行期重排序。由于重排序的存在,指令实际的执行顺序,并不是源码中看到的顺序。
1. 编译器出于优化的目的,在编译阶段将源码的顺序进行交换。
2. 对计算机来说,通常内存的写操作相对于读操作要昂贵很多。因此,写操作一般会在 CPU 内部的store buffer缓存。这就导致在一个 CPU 里执行一个写操作之后,不一定马上就被另一个 CPU 所看到。这从另一个角度讲,效果上其实就是读写乱序了。
(二)CPU cache 工作机制及内存屏障【个人理解,不一定正确】
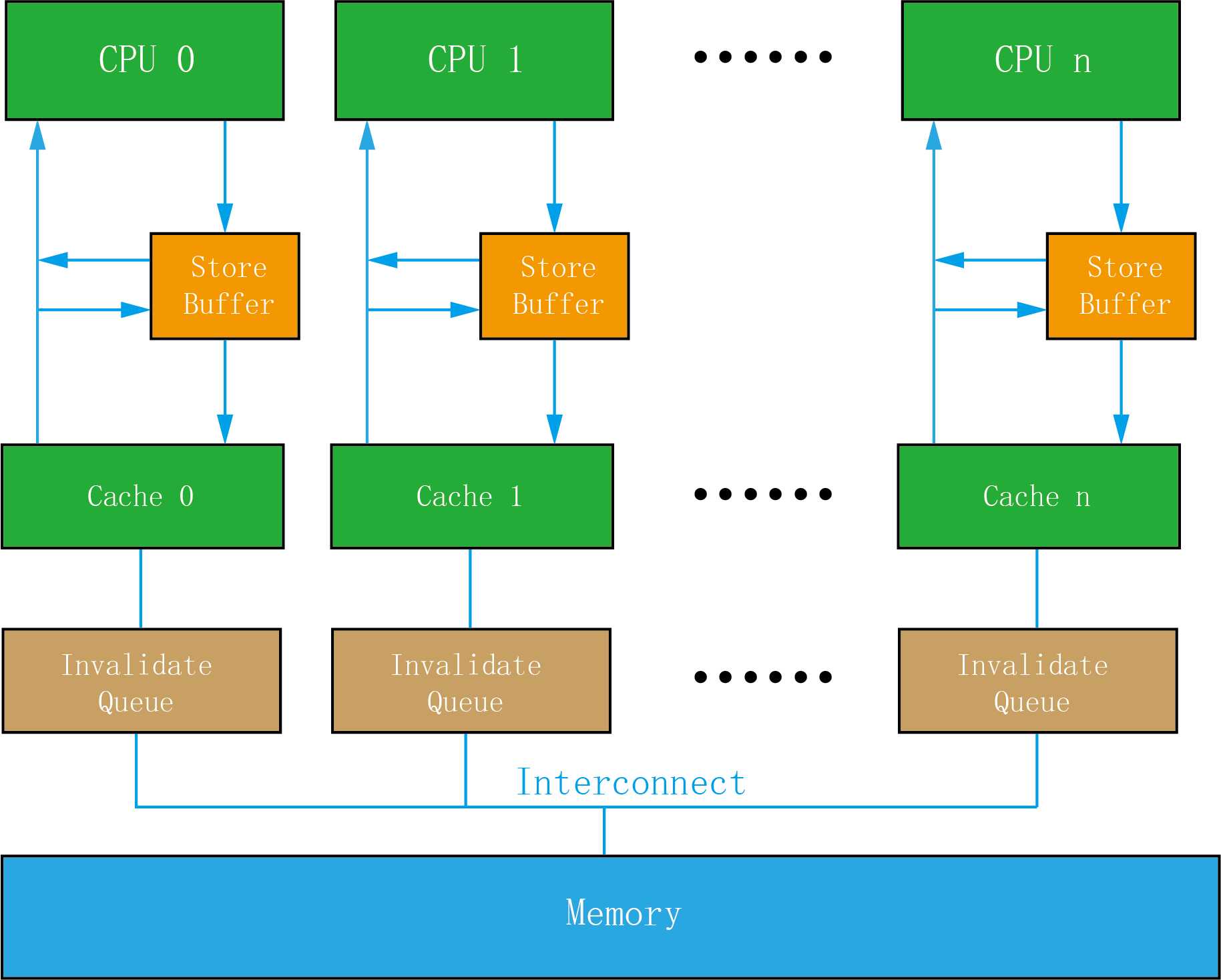
1. 为了提高CPU效率,每个CPU中都有两块私有的特殊内存:store buffer和Invalidate队列。其中,store buffer,用于CPU临时写入数据的缓冲区。Invalidate队列为该CPU cache即将无效数据项的请求队列。只有位于cache或memory中的数据才会被CPUs共享,并且他们通过MESI协议保证了数据的一致性。即不论哪个CPU发生了cache miss,它们从其他CPU嗅探到的或从内存加载的数据都是一样的。
2. 存在于store buffer中的数据是最新的(因为执行了写操作),该CPU下次的读操作往往优先从这里而不是cache中获取。但store buffer中的数据是该CPU私有的,不能被其他CPU共享。而且经常也不会立即刷新到cache或memory中,一般需要等到写这个数据的CPU接收到来自其他CPU的invalidate acknowledgement回复后才会进行刷新。即store buffer和cache中数据可能是不一样的,store buffer的较新,而cache中是旧值。此外,读操作时,只有该项数据是无效的才会从其他CPU或memory中读取,如果仍处于有效状态则会从本地cache中读取。因此,如果invalidate请求还保存在队列中的话,就可能读到旧值。只有等该CPU处理完队列中的这条invalidate消息,才会从cache或memory中读取。因此,store buffer和Invalidate队列都可能引起memory oder问题。
3. 内存屏障的作用
(1)写屏障指令:作用于store buffer,它只是约束执行CPU上的store操作的顺序。该指令有两个作用:A. 确保写屏障之前的store操作不会被重排到指令之后。B.执行当遇到该指令时首先flush store buffer(也就是将指令之前store操作写入于store buffer中的值刷新到cacheline中)。如memory_order_release的作用就类似于加入写屏障。
(2)读屏障指令:作用于Invalidate queue上,它只是约束执行CPU上的load操作的顺序。该指令有两个作用:A. 确保读屏障之后的load操作不会被重排到指令之前。B.执行后续的load操作之前,先将Invalidate Queue队列中相关项执行完,确保后续的load操作触发cache miss,从而读到最新的数据。读屏障指令就象一道栅栏,严格区分了之前和之后的load操作。如memory_order_acquire的作用就类似于加入读屏障。
(三)C++11的6种memory order(个人理解,不保证正确性)
|
内存顺序 |
作用 |
|
memory_order_relexed |
①只保证当前操作的原子性。 ②不考虑线程间的同步,其它线程可能读到旧值(因为不指定内存屏障,所以内存操作执行时可能是乱序的) |
|
memory_order_acquire |
①对读取(load)实施acquire语义。相当于插入一个内存读屏障,保证之后的读操作不会被重排到该操作之前。 ②类似于mutex的lock操作,但不会阻塞。只是保证如果其它线程的release己经发生,则本线程其后对该原子变量的load操作一定会获取到该变量release之前发生的写入。因此,acuquire一般需要用循环,等待其他线程release的发生。 |
|
memory_order_release |
①对写入(store)实施release语义(类似于mutex的unlock操作)。保证之前的写操作不会被重排到该操作之后,同时确保该操作之前的store操作将数据写入cache或memory中,确保cache或memory是最新数据。(相当于插入一个写屏障)。 ②该操作之前当前线程内的所有写操作,对于其他对这个原子变量进行acquire或assume的线程可见。(对于assume,写操作指对依赖变量的写操作) ③该操作本身是原子操作。 |
|
memory_order_consume |
类似memory_order_acquire,但只对与这块内存有关的读写操作起作用。 |
|
memory_order_acq_rel |
①对读取和写入施加acquire-release语义,无法被重排(相当于同时插入读写两种内存屏障)。 ②可以看见其他线程施加release语义的所有写入,同时自己release结束后所有写入对其他acquire线程可见。 |
|
memory_order_seq_cst |
①如果是读取就是acquire语义,写入就是release语义,读写就施加acquire-release语义。 ②同时会对所有使用此memory-order的原子操作建立一个全局顺序。这样,所有线程都将看到同样一个的内存操作顺序。 |
【编程实验】内存顺序
#include <iostream> #include <thread> #include <atomic> #include <memory> #include <vector> #include <cassert> #include <mutex> using namespace std; std::mutex io_mutex; //Acuqire-Release、relaxed语义 class CAcqRel { int m; std::atomic<bool> x, y; std::atomic<int> z; public: CAcqRel():x(false),y(false),z(0),m(0){} void write_x_then_y() { m = 1; //非原子变量 x.store(true, std::memory_order_relaxed); //relaxed语义,无法保证a和x写入的先后顺序。 y.store(true, std::memory_order_release); //对x实施release语义,保证a/x一定在y之前被写入 } void read_y_then_x() { while (!y.load(std::memory_order_acquire)); //对y实施acuqire语义,同时使用循 //等待y原子变量的release的发生。 if (x.load(std::memory_order_relaxed)) //acquire线程可见到release之前的写操作,因此x为true。 ++z; } void test() { std::thread a(&CAcqRel::write_x_then_y, this); std::thread b(&CAcqRel::read_y_then_x, this); a.join(); b.join(); assert(z.load() != 0); //条件成立 assert(m == 1); //条件成立 } }; //Consume语义 class CConsume { std::atomic<std::string*> ptr; int data; std::atomic<int> atData; public: CConsume():data(0),atData(0),ptr(nullptr){} void producer() { std::string* p = new std::string("Hello"); data = 42; atData.store(2019, std::memory_order_relaxed); ptr.store(p, std::memory_order_release); } void consumer() { std::string* p2; while (!(p2 = ptr.load(std::memory_order_consume))); //consume语义,只能保证额ptr //依赖的变量p己被存储,但不保证 //data和atData的值。 assert(*p2 == "Hello"); //条件一定成立。 assert(data == 42); //无法保证data一定等于42。因为ptr对其无依赖。 assert(atData == 2019); //无法保证atData一定等于2019,因为ptr对其无依赖 } void test() { std::thread t1(&CConsume::consumer, this); std::thread t2(&CConsume::producer, this); t1.join(); t2.join(); } }; //seq_cst语义 class CSeqCst { std::string work; std::atomic<bool> ready; std::atomic<int> data; public: CSeqCst():ready(false),data(0){} void write() { //以下的写操作由于采用memory_order_seq_cst语义,因此当写入时会产生一个全局 //的写入顺序,即先work再data,最后写入ready。这个顺序对所有使用该语义的 //线程可见,即 work = "done"; data.store(2019, std::memory_order_seq_cst); ready = true; //默认采用memory_order_seq_cst语义 } void read() { //默认采用memory_order_seq_cst语义。当ready发生时,由于全局顺序必然知道data //和work的存储己发生 while (!ready.load()); std::cout << work << std::endl; //done,全局顺序,work一定为done std::cout << data << std::endl; //2019,全局顺序,data一定等于2019 } void test() { std::thread t1(&CSeqCst::write, this); std::thread t2(&CSeqCst::read, this); t1.join(); t2.join(); } }; //实现一个无锁的线程安全栈 template<typename T> class stack { struct node { std::shared_ptr<T> data; node* next; node(const T& d):next(nullptr),data(std::make_shared<T>(d)){} //用shared_ptr指向新分配出来的T }; private: std::atomic<node*> head; public: void push(const T& data) { node* newNode = new node(data); //创建新节点 newNode->next = head.load(); //将原head移到新节点的后驱节点。这里可能出现多线程 //同时将head节点作为其后驱 //compare_exchange_weak是原子操作。先进行比较再交换。由于多线程的竞争,每次只允许 //一个线程compared_exchange_weak,第1个抢到的线程会交换成功,成为新的head。而其它 //线程则会失败,并将newNode的后驱改为新的head并继续循环比较-交换操作,直至所有 //线程的push操作结束。 while (!head.compare_exchange_weak(newNode->next, newNode)); //新节点变为新的head } std::shared_ptr<T> pop() { node* oldHead = head.load(); //多线程时,会出现head被多个线程抢到。 //每次只有一个线程可以执行compare_exchange_weak操作,并将head的后驱变成新的head //其它线程会返回失败,并重置oldhead为新的head,然后开始另一轮的循环。 while (oldHead && !head.compare_exchange_weak(oldHead, oldHead->next)); return oldHead ? oldHead->data : std::shared_ptr<T>();//处理空链表的情况。 } }; int main() { //1. 测试memory-order CAcqRel ar; ar.test(); CConsume cs; cs.test(); CSeqCst sc; sc.test(); //2. 线程安全的无锁栈结构 stack<int> st; vector<std::thread> producers; for (int i = 0; i < 10; ++i) { producers.emplace_back([&st,i]() {st.push(i); }); } for (auto& p : producers) p.join(); vector<std::thread> consumers; for (int i = 0; i < 10; ++i) { consumers.emplace_back([&st]() { std::lock_guard<std::mutex> lck(io_mutex); std::cout << *st.pop() << " "; }); } for (auto& c : consumers) c.join(); return 0; } /*输出结果 done 2019 9 8 6 7 5 4 2 3 1 0 */
以上是关于第31课 std::atomic原子变量的主要内容,如果未能解决你的问题,请参考以下文章
C++ error: use of deleted function ‘std::atomic<short unsigned int>::atomic(const std::atomic<short