PySpark任务在YARN集群上运行python 算法
Posted ljtyxl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PySpark任务在YARN集群上运行python 算法相关的知识,希望对你有一定的参考价值。
由于python的算法开发常常会用到pytorch、sklearn、tensorflow这种动不动几个G的大包和大的语料,而我们开发的模型常常需要用于大数据环境的预测,所以避免不了使用pyspark、greenplum这种集群环境去跑数据。
Spark on YARN又分为client模式和cluster模式:在client模式下,Spark Application运行的Driver会在提交程序的节点上,而该节点可能是YARN集群内部节点,也可能不是,一般来说提交Spark Application的客户端节点不是YARN集群内部的节点,那么在客户端节点上可以根据自己的需要安装各种需要的软件和环境,以支撑Spark Application正常运行。在cluster模式下,Spark Application运行时的所有进程都在YARN集群的NodeManager节点上,而且具体在哪些NodeManager上运行是由YARN的调度策略所决定的。
对比这两种模式,最关键的是Spark Application运行时Driver所在的节点不同,而且,如果想要对Driver所在节点的运行环境进行配置,区别很大,但这对于PySpark Application运行来说是非常关键的。
PySpark Application运行原理
理解PySpark Application的运行原理,有助于我们使用Python编写Spark Application,并能够对PySpark Application进行各种调优。PySpark构建于Spark的Java API之上,数据在Python脚本里面进行处理,而在JVM中缓存和Shuffle数据,数据处理流程如下图所示 :
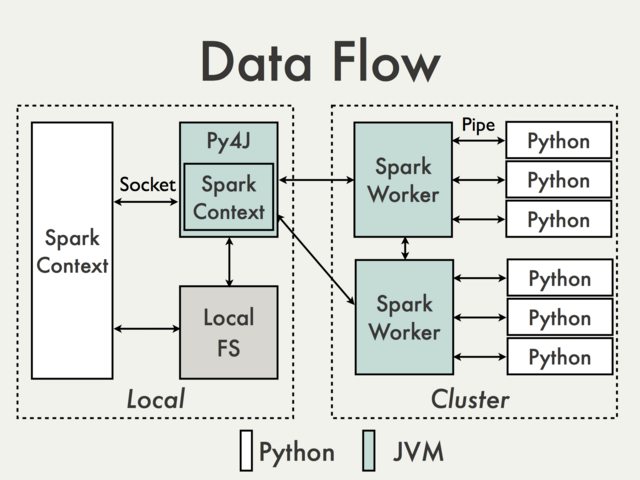
Spark Application会在Driver中创建pyspark.SparkContext对象,后续通过pyspark.SparkContext对象来构建Job DAG并提交DAG运行。使用Python编写PySpark Application,在Python编写的Driver中也有一个pyspark.SparkContext对象,该pyspark.SparkContext对象会通过Py4J模块启动一个JVM实例,创建一个JavaSparkContext对象。PY4J只用在Driver上,后续在Python程序与JavaSparkContext对象之间的通信,都会通过PY4J模块来实现,而且都是本地通信。
————————————————
PySpark Application中也有RDD,对Python RDD的Transformation操作,都会被映射到Java中的PythonRDD对象上。对于远程节点上的Python RDD操作,Java PythonRDD对象会创建一个Python子进程,并基于Pipe的方式(pipe函数可用于创建一个管道,以实现进程间的通信)与该Python子进程通信,将用户编写Python处理代码和数据发送到Python子进程中进行处理。
我们基于Spark on YARN模式,并根据当前企业所具有的实际集群运行环境情况,来说明如何在Spark集群上运行PySpark Application,大致分为如下2种情况:
- YARN集群配置Python环境,这种情况,如果是初始安装YARN、Spark集群,并考虑到了当前应用场景需要支持Python程序运行在Spark集群之上,这时可以准备好对应Python软件包、依赖模块,在YARN集群中的每个节点上进行安装。这样,YARN集群的每个NodeManager上都具有Python环境,可以编写PySpark Application并在集群上运行。目前比较流行的是直接安装Python虚拟环境,使用Anaconda等软件,可以极大地简化Python环境的管理工作。缺点是,如果后续使用Python编写Spark Application,需要增加新的依赖模块,那么就需要在YARN集群的每个节点上都进行该新增模块的安装。而且,如果依赖Python的版本,可能还需要管理不同版本Python环境。因为提交PySpark Application运行,具体在哪些NodeManager上运行该Application,是由YARN的调度器决定的,必须保证每个NodeManager上都具有Python环境(基础环境+依赖模块),当然这些可以做成脚本化管理,使得python的依赖包完成各节点的自动安装。
spark-submit --master yarn --name "20220331093907run01.py" --driver-memory 6G --driver-cores 4 --executor-memory 32G --executor-cores 12 --num-executors 10 --archives /usr/local/anaconda3/envs/pyspark.zip --total-executor-cores 16 --conf spark.default.parallelism=150 --conf spark.executor.memoryOverhead=4g --conf spark.driver.memoryOverhead=2g --conf spark.yarn.maxAppAttempts=3 --conf spark.yarn.submit.waitAppCompletion=true --conf spark.pyspark.driver.python=/usr/local/anaconda3/envs/pyspark/bin/python3 --conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=/usr/local/anaconda3/envs/pyspark/bin/python3 --conf spark.pyspark.python=/usr/local/anaconda3/envs/pyspark/bin/python3 hdfs://master:8020/algo/tasks/20220331093907run01.py-
YARN集群不配置Python环境,这种情况,更适合企业已经安装了规模较大的YARN集群,并在开始使用时并未考虑到后续会使用基于Python来编写Spark Application,并且不想在YARN集群的NodeManager上安装Python基础环境及其依赖模块。我们参考了Benjamin Zaitlen的博文(详见后面参考链接),并基于Anaconda软件环境进行了实践和验证,具体实现思路如下所示:
在任意一个Linux OS的节点上,安装Anaconda软件
通过Anaconda创建虚拟Python环境
在创建好的Python环境中下载安装依赖的Python模块
将整个Python环境打成zip包
提交PySpark Application时,并通过--archives选项指定zip包路径
spark-submit --master yarn --name "20220331093907run01.py" --deploy-mode client --driver-memory 6G --driver-cores 4 --executor-memory 32G --executor-cores 12 --num-executors 10 --archives /usr/local/anaconda3/envs/pyspark.zip --total-executor-cores 16 --conf spark.default.parallelism=150 --conf spark.executor.memoryOverhead=4g --conf spark.driver.memoryOverhead=2g --conf spark.yarn.maxAppAttempts=3 --conf spark.yarn.submit.waitAppCompletion=true --conf spark.pyspark.driver.python=/usr/local/anaconda3/envs/pyspark/bin/python3 hdfs://master:8020/algo/tasks/20220331093907run01.py
以上是关于PySpark任务在YARN集群上运行python 算法的主要内容,如果未能解决你的问题,请参考以下文章