seq2seq
Posted jiayibing2333
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了seq2seq相关的知识,希望对你有一定的参考价值。
【符号简介】
————————————————————————
m——编码器的隐层神经元个数
n——输入序列词向量维度
p——解码器隐层神经元个数
q——输出序列词向量维度
v——词汇表大小
————————————————————————
【正文开始】
我们之前遇到的较为熟悉的序列问题,主要是利用一系列输入序列构建模型,预测某一种情况下的对应取值或者标签,在数学上的表述也就是通过一系列形如 的向量序列来预测
值,这类的问题的共同特点是,输入可以是一个定长或者不定长的序列,但输出一般要求是一个固定长度的序列(单个标签较为常见,即长度为1的序列)。例如利用RNN网络的文本情感分类,输入的文本长度不固定,但输出是某一个情感标签。这样的问题我们已经有相对成熟的方法解决,而在有的现实场景中,我们更希望输入与输出的序列长度都不固定,针对此类问题,我们来介绍序列到序列(seq2seq)模型。
一、Encoder-Decoder框架
Encoder-Decoder(编码-解码器)框架是Cho et al[1]和Sutskever[2]两位学者在2014年分别独立却又不约而同提出的,目的是针对输入-输出这一对不定长的序列对,利用编码器将输入序列“编码”为一个抽象的信息,再通过解码器对抽象信息进行逐步“解码”。所谓编码与解码其实就是一种函数的映射,类似于在两种序列对之间找到一个公共的桥梁,使得两种序列对尽可能的对应上。
下面我将以较为常见的序列到序列的任务场景——中英文机器翻译为例,来说明Encoder-Decoder这个框架具体工作流程。
- Encoder
以中文为源语言,拿“我很帅”为例,翻译为“I am handsome”的英文目标语言。当然开始对源语言编码之前,还是要将这些非结构化的文本转化为可计算的结构化数据,也就是众所周知的“词向量(其实更合理的名字叫word embedding~)”,不妨设源语言和目标语言的词w都被映射为n维的词向量E(w),如图1所示,首先将源语言的每个词输入到编码器中。
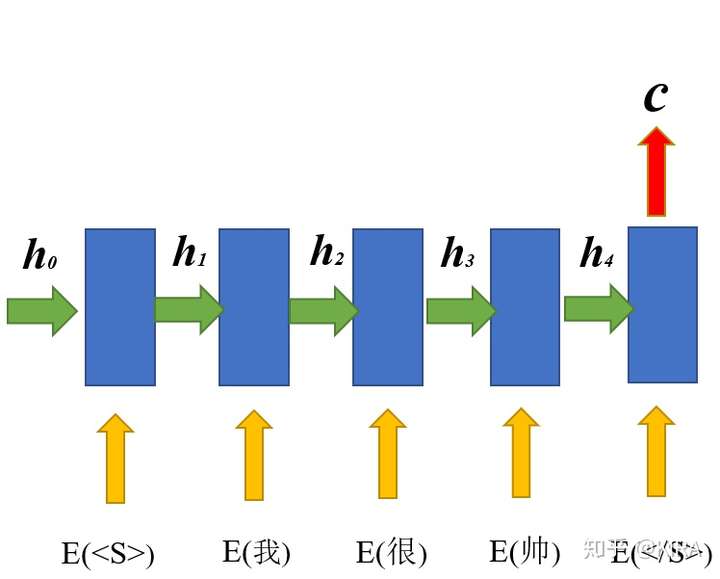 图1 编码器(Encoder)示例
图1 编码器(Encoder)示例
需要说明的是,在序列到序列处理不定长序列的过程中,采用了序列的起始标记<S>和终止标记</S>来“告诉”编码器的编码过程何时开始与结束,也就是间接反映了当前序列的长度信息,编码器一般采用处理序列比较有优势的循环神经网络(RNN),主要流程是将序列中每个n维词向量 与其前一时刻的m维隐状态向量
拼接为m+n维向量
,通过全连接网络及门控运算(GRU/LSTM中会涉及)【注1】,产生当前时刻对应的m维隐状态向量
。
例如 ,
等等以此类推,特别地,取初始隐状态
为m维零向量。
当终止符</s>输入至编码器的时候,编码器将输出整个输入序列的m维上下文向量c——以抽象输入序列的特征向量,类似于我们人类读一句话提炼出这句话的梗概一样,至此整个编码过程完成。
- Decoder
接下来将借助源语言的上下文向量c及目标语言的上下文关系来完成源语言向目标语言的解码过程。解码器一般也会选用RNN系列的神经网络,具体流程如图2所示。
 图2 解码器(Decoder示例)
图2 解码器(Decoder示例)
在图2所示的流程中,解码的每一步需要依赖三个变量,一个是从编码器得到的源语言上下文向量c,用于描述源语言的信息,第二个是前一时刻的解码隐状态向量 ,最后一个是前一时刻预测得到的目标词向量
,用于捕捉目标语言的上下文依赖关系。在数学的表达上也就是将m维源语言上下文向量c,p维隐状态向量
,q维预测所得词向量
拼接为m+p+q维向量
,通过全连接及门控运算得到当前时刻对应的p维隐状态向量
,输出层利用全连接及softmax函数归一化,得到v维度(v为词汇表大小)的输出向量,取最大概率那个分量对应的词向量作为当前时刻的目标词向量
。
例如 ,在输出层向量如果为
(该向量每个分量分别是解码为I、am、handsome、</s>对应的概率),这时候发现I对应的概率最大,因此此时输出的目标即为I对应的词向量
。特别地,初始解码状态
取p维零向量,初始词向量
取起始符<s>对应的词向量。
当预测目标输出为</s>的时候,整个解码过程结束,也就意味着一个不定长的序列被生成。
二、Attention机制
上述Encoder-Decoder框架在序列到序列模型中有很广泛的应用。但该框架有个潜在的问题就出在编码器产生的源语言上下文向量c上了,一般来说c向量具有两个局限性,第一个是当输入序列很长的时候,通过循环网络产生的c向量很难表达整句的信息,而是偏向于表达离序列结尾近的信息;另一方面,由于在机器翻译的过程中,需要明确目标语言词汇与源语言词汇的大致对应关系,这样如果所有的解码都用同一个上下文c向量,就很难表现出源语言词汇的具体贡献情况,因此引入了一个现在非常流行的方法——注意力(Attention)机制。
要解决c向量引发的问题,最自然的想法是让固定的c“动”起来,也就是在解码的过程中每个时刻待拼接的c向量是不同的,是随着解码过程中的需要不断变化的。此时c向量的生成过程如图3所示。
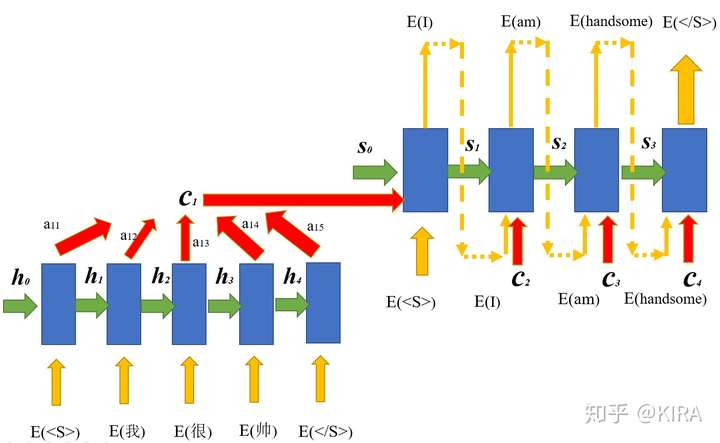 图3 Attention机制在Encoder-Decoder框架的应用
图3 Attention机制在Encoder-Decoder框架的应用
从图3不难看出,c向量从原来编码完一整个输入序列产生一个,变成了每个时刻都会产生的向量 。 而且
是由各个编码器隐状态向量
加权求和所得,图中以
为例,
,
其中, 权重 为实数,
为m维向量。
现在的问题就被转化为,如何确定第i个时刻的上下文向量 内的权重分配
。这个时候就需要我们刚提到的源语言和目标语言在翻译过程中的词汇对应关系,考虑解码过程的第i个时刻,此时应该给解码器输入隐状态
, 前一个词
,以及刚从固定的c替换过来的 。我们希望
告诉我们,在解码器完成上一个词的解码后,当前要解码的词汇与源语言的哪些词汇相对应,也就是比较源语言哪个时刻的信息与当前包含解码信息的隐状态
关联最紧密,于是构造一个”打分器“,将隐状态
与源语言的每个隐状态
逐一比较,计算其关联得分,这个得分即可作为每个源语言隐状态
前的权重
。以下打分函数是常见的一种:
,其中
为刻画距离的函数【注2】。
从上式也可反映出来,j变量是要遍历每个取值的,而对于确定的第i时刻来说,i则是不变的,也就是”隐状态 与源语言的每个隐状态
逐一比较“。
这个方法在直观上理解为,翻译不同的目标词汇时,我们对源语言的各个词汇应该有着不一样的关注度(权重),例如翻译出"handsome"这个词的时候,中文的”帅“在直观上应该被赋予更高的权重。这种类似于人脑的注意力机制(Attention)就很自然的被引入到Encoder-Decoder框架中来了。
注意力机制(Attention)其实本质上就是一种权重分配,而权重则来自于我们针对具体任务设计的关联度函数,基于这种模式的注意力机制目前被应用的比较广泛,可以在不同任务中不断改进和尝试。
三、seq2seq模型的优化目标
在监督学习的大部分模型中,我们都将考虑如何根据损失函数(或者叫目标函数)来更新模型参数,这也是模型训练的目标,在seq2seq模型中也不例外。
seq2seq模型的目标在于根据输入序列的信息最大化目标输出序列的概率,类似于语言模型的思路。对于所有的训练样本,有以下形式的损失函数:
其中N为训练样本数量, ,
为每个样本对应的输入和输出序列,
为待学习的参数向量。每一个
都由Encoder-Decoder框架生成,其中包含在神经网络中的大量参数,可通过梯度下降的方式逐步优化。
个人认为这种目标函数的设计类似于语言模型,对训练集也就是语料有一定的依赖性,后续我也将继续思考这个问题,并进行补充。
至此,seq2seq模型及注意力(Attention)机制的基本流程已经介绍完了,目前的前沿领域还有很多的深入探讨和改进,我也将不断整理总结。
感谢你的阅读。
【注1】
在Bahdanau[3]的论文原文中,隐状态 的计算形式与本文的表述有些差别,以如下形式表述:
这种表述与本文提到的将拼接向量 送入全连接网络及门控运算过程是等价的,论文原文的表述实际上是一种矩阵分块运算的展开。
【注2】
在Bahdanau[3]的论文原文中,刻画距离的函数 表述为
其中 ,
,
为相应变量的待训练权重矩阵。刻画距离的函数在不同的应用场景下有着不同的设计和选取,上述形式只是常见的一种。
链接:
https://zhuanlan.zhihu.com/p/46040939
以上是关于seq2seq的主要内容,如果未能解决你的问题,请参考以下文章