执行计划
Posted qin1993
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了执行计划相关的知识,希望对你有一定的参考价值。
使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道mysql是
如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈
执行计划的作用
表的读取顺序
数据读取操作的操作类型
哪些索引可以使用
哪些索引被实际使用
表之间的引用
每张表有多少行被优化器查询

ID列:
描述select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
根据ID的数值结果可以分成一下三种情况
id相同:执行顺序由上至下
id不同:如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
id相同不同:同时存在
Id相同

如上图所示,ID列的值全为1,代表执行的允许从t1开始加载,依次为t3与t2 EXPLAIN select t2.* from t1,t2,t3 where t1.id = t2.id and t1.id = t3.id and t1.other_column = ‘‘;
Id不同
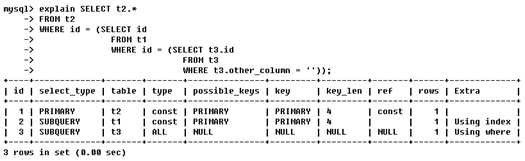
如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行 EXPLAIN select t2.* from t2 where id = ( select id from t1 where id = (select t3.id from t3 where t3.other_column=‘‘) );
Id相同又不同

id如果相同,可以认为是一组,从上往下顺序执行; 在所有组中,id值越大,优先级越高,越先执行 EXPLAIN select t2.* from ( select t3.id from t3 where t3.other_column = ‘‘ ) s1 ,t2 where s1.id = t2.id
Select_type:查询的类型,
要是用于区别:普通查询、联合查询、子查询等的复杂查询

SIMPLE EXPLAIN select * from t1
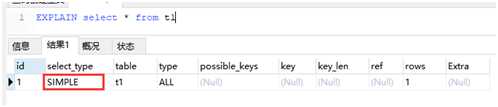
简单的 select 查询,查询中不包含子查询或者UNION
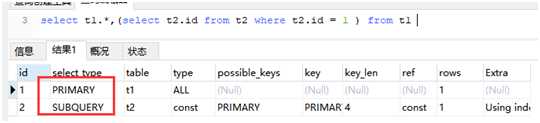
PRIMARY与SUBQUERY PRIMARY:查询中若包含任何复杂的子部分,最外层查询则被标记为 SUBQUERY:在SELECT或WHERE列表中包含了子查询 EXPLAIN select t1.*,(select t2.id from t2 where t2.id = 1 ) from t1
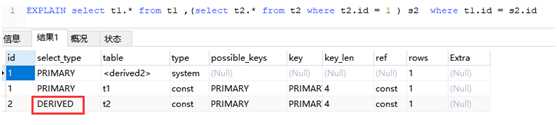
DERIVED 在FROM列表中包含的子查询被标记为DERIVED(衍生) MySQL会递归执行这些子查询, 把结果放在临时表里。 select t1.* from t1 ,(select t2.* from t2 where t2.id = 1 ) s2 where t1.id = s2.id
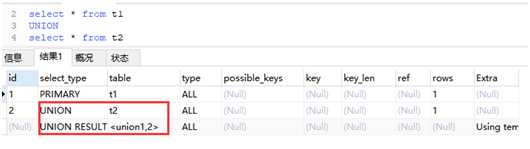
UNION RESULT 与UNION UNION:若第二个SELECT出现在UNION之后,则被标记为UNION; UNION RESULT:从UNION表获取结果的SELECT #UNION RESULT ,UNION EXPLAIN select * from t1 UNION select * from t2
table列
显示这一行的数据是关于哪张表的
Type列
type显示的是访问类型,是较为重要的一个指标,结果值从最好到最坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
需要记忆的
system>const>eq_ref>ref>range>index>ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。
1.2.4.4.1. System与const System:表只有一行记录(等于系统表),这是const类型的特列,平时不会出现,这个也可以忽略不计 Const:表示通过索引一次就找到了 const用于比较primary key或者unique索引。因为只匹配一行数据,所以很快 如将主键置于where列表中,MySQL就能将该查询转换为一个常量

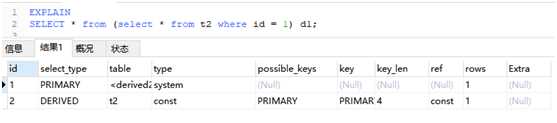
EXPLAIN SELECT * from (select * from t2 where id = 1) d1;
eq_ref
唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描


EXPLAIN SELECT * from t1,t2 where t1.id = t2.id
Ref
非唯一性索引扫描,返回匹配某个单独值的所有行.
本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而,它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体

EXPLAIN select count(DISTINCT col1) from t1 where col1 = ‘ac‘
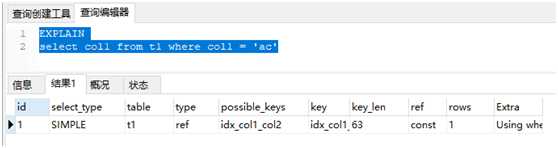
或者 EXPLAIN select col1 from t1 where col1 = ‘ac‘
Range 只检索给定范围的行,使用一个索引来选择行。key 列显示使用了哪个索引 一般就是在你的where语句中出现了between、<、>、in等的查询 这种范围扫描索引扫描比全表扫描要好,因为它只需要开始于索引的某一点,而结束语另一点,不用扫描全部索引。


EXPLAIN select * from t1 where id BETWEEN 30 and 60 EXPLAIN select * from t1 where id in(1,2)
Index 当查询的结果全为索引列的时候,虽然也是全部扫描,但是只查询的索引库,而没有去查询 数据。


EXPLAIN select c2 from testdemo
All Full Table Scan,将遍历全表以找到匹配的行

possible_keys 与Key
possible_keys:可能使用的key
Key:实际使用的索引。如果为NULL,则没有使用索引
查询中若使用了覆盖索引,则该索引和查询的select字段重叠
这里的覆盖索引非常重要,后面会单独的来讲


EXPLAIN select col1,col2 from t1
其中key和possible_keys都可以出现null的情况(结婚邀请朋友的例子)
Key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好
key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的
l key_len表示索引使用的字节数,
l 根据这个值,就可以判断索引使用情况,特别是在组合索引的时候,判断所有的索引字段是否都被查询用到。
l char和varchar跟字符编码也有密切的联系,
l latin1占用1个字节,gbk占用2个字节,utf8占用3个字节。(不同字符编码占用的存储空间不同)
字符类型
变长字段需要额外的2个字节(VARCHAR值保存时只保存需要的字符数,另加一个字节来记录长度(如果列声明的长度超过255,则使用两个字节),所以VARCAHR索引长度计算时候要加2),固定长度字段不需要额外的字节。
而NULL都需要1个字节的额外空间,所以索引字段最好不要为NULL,因为NULL让统计更加复杂并且需要额外的存储空间。
复合索引有最左前缀的特性,如果复合索引能全部使用上,则是复合索引字段的索引长度之和,这也可以用来判定复合索引是否部分使用,还是全部使用。
整数/浮点数/时间类型的索引长度
NOT NULL=字段本身的字段长度
NULL=字段本身的字段长度+1(因为需要有是否为空的标记,这个标记需要占用1个字节)
datetime类型在5.6中字段长度是5个字节,datetime类型在5.5中字段长度是8个字节
1.1.1.1. Ref
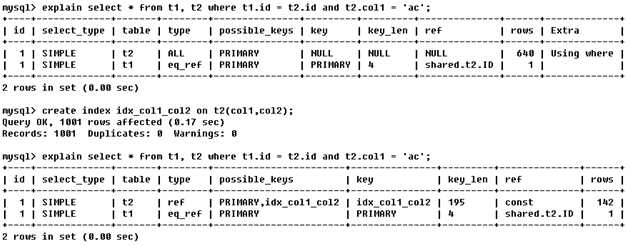
显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值

EXPLAIN
select * from s1 ,s2 where s1.id = s2.id and s1.name = ‘enjoy‘
由key_len可知t1表的idx_col1_col2被充分使用,col1匹配t2表的col1,col2匹配了一个常量,即 ‘ac‘
其中 【shared.t2.col1】 为 【数据库.表.列】
1.1.1.1. Rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数
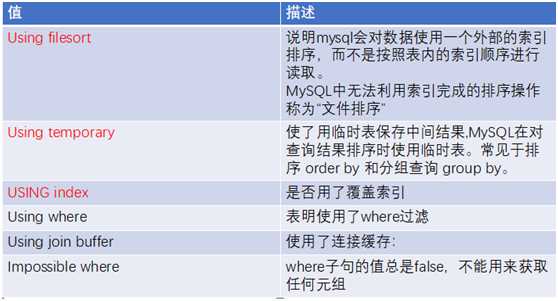
1.1.1.1. Extra
包含不适合在其他列中显示但十分重要的额外信息。
1.1.1.1.1. Id相同

如上图所示,ID列的值全为1,代表执行的允许从t1开始加载,依次为t3与t2
EXPLAIN
select t2.* from t1,t2,t3 where t1.id = t2.id and t1.id = t3.id
and t1.other_column = ‘‘;
以上是关于执行计划的主要内容,如果未能解决你的问题,请参考以下文章