MapReduce计算框架
Posted yinjia
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce计算框架相关的知识,希望对你有一定的参考价值。
原理流程分析
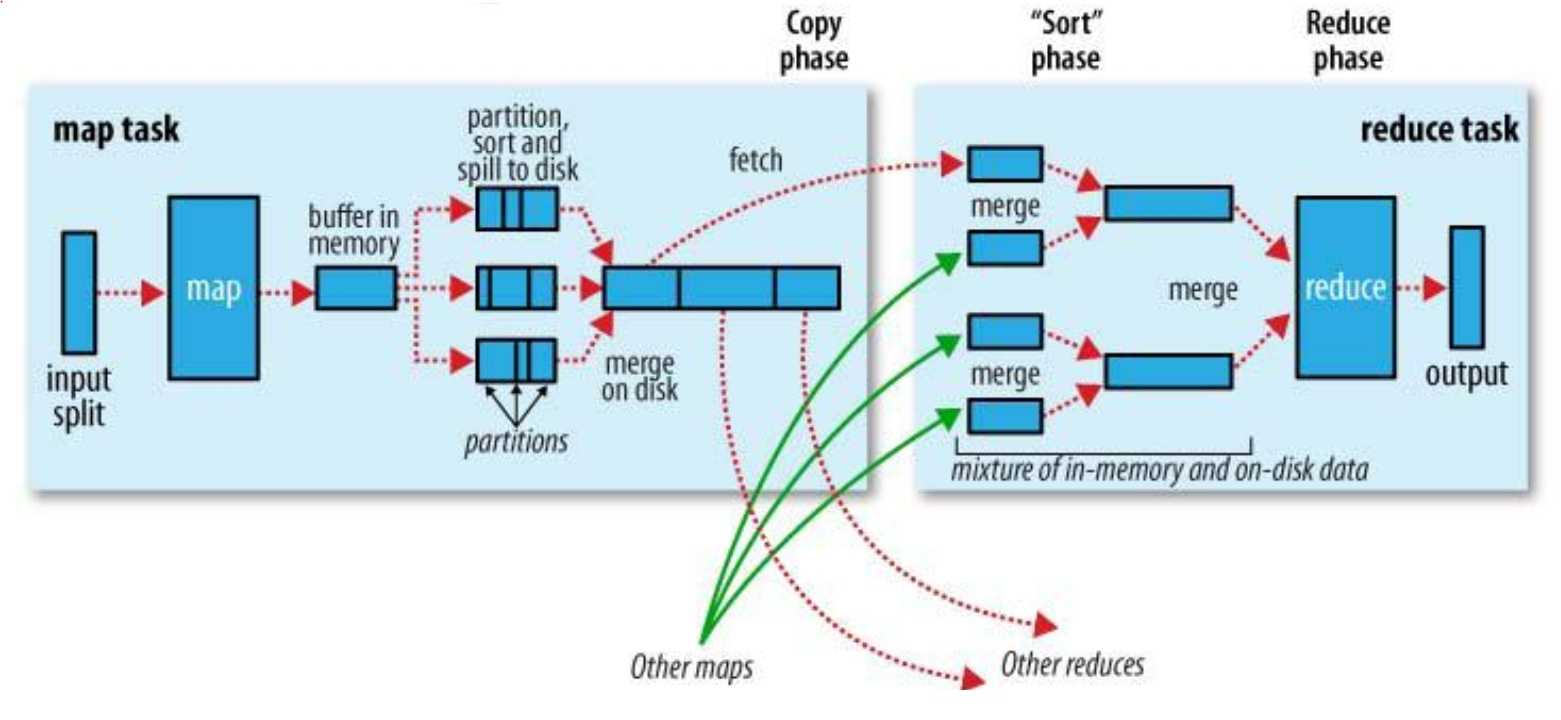
-
文件存储在HDFS中,每个文件切分成多个一定大小(默认128M)的Block(默认3个备份)存储在多个数据节点上,数据格定义以" "分割每条记录,以空格区分一个目标单词。
-
每读取一条记录,调用一次map函数,然后继续读取下一条记录直到split尾部。
-
map 输出的结果暂放在一个环形内存缓冲区,每个map的结果和partition处理的key value结果都会保存在缓存中(该缓冲区的大小默认为100M,由io.sort.mb属性控制)
-
当内存缓冲区达到阈值时,溢写splill线程锁住80M的缓冲区(默认为缓冲区大小 的80%,由io.sort.spill.percent属性控制),开始将数据写出到本地磁盘中,然后释放内存,会在本地文件系统中每次溢写都创建一个数据文件,将该缓冲区中的数据写入这个文件。在 写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据。这样做是为了避免有些 reduce任务分配到大量数据,而有些reduce任务却分到很少数据,甚至没有分到数据的尴尬局面。其实分区就是对数据进行hash的过程。溢出的数据到磁盘前会对数据进行key排序sort,以及合并combiner,这样做目的让尽可能少的数据写入磁盘。
-
发送相同的Reduce的key数量,会拼接到一起,减少 partiton的索引数量。当 map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并。合并的过程中会不断地进行排序和combia操作,目的有两个:1.尽 量减少每次写入磁盘的数据量;2.尽量减少下一复制阶段网络传输的数据量。最后合并成了一个已分区且已排序的文件。为了减少网络传输的数据量,这里可以将 数据压缩,只要将mapred.compress.map.out设置为true就可以了。
-
Reduce端
- Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。
- 数据合并,相同的key的数据,value值合并,减少输出传输量。
- 合并的过程中会产生许多的中间文件(写入磁盘了),但MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数,最终输出合并后的结果。
脚本举例
- 代码示例1
1 # -*- coding: utf-8 -*- 2 import jieba 3 4 a = ‘我今天要上Map Reduce,我今天上午已经上课。‘ 5 cut_lst = [x for x in jieba.cut(a,cut_all=False)] 6 print(cut_lst) 7 print([hash(x)%3 for x in cut_lst]) 8 9 a1 = ‘我‘ 10 a2 = ‘今天‘ 11 a3 = ‘要‘ 12 a4 = ‘我‘ 13 14 print(a1,hash(a1),hash(a1)%3) 15 print(a2,hash(a2),hash(a2)%3) 16 print(a3,hash(a3),hash(a3)%3) 17 print(a4,hash(a4),hash(a4)%3) 18 19 输出结果: 20 [‘我‘, ‘今天‘, ‘要‘, ‘上‘, ‘Map‘, ‘ ‘, ‘Reduce‘, ‘,‘, ‘我‘, ‘今天上午‘, ‘已经‘, ‘上课‘, ‘。‘] 21 Loading model cost 0.766 seconds. 22 [2, 1, 2, 1, 0, 2, 2, 1, 2, 2, 0, 2, 1] 23 Prefix dict has been built succesfully. 24 我 -7500002229624780265 2 25 今天 2186637811099135375 1 26 要 -3455194562404906111 2 27 我 -7500002229624780265 2
可见“我” hash值是一致性。
- map端代码示例2
如文本文件格式: Preface “The Forsyte Saga” was the title originally destined for that part of it which is called “The Man of Property”; and to adopt it for the collected chronicles of the Forsyte family has indulged the Forsytean tenacity that is in all of us. The word Saga might be objected to on the ground that it connotes the heroic and that there is little heroism in these pages. But it is used with a suitable irony; and, after all, this long tale, though it may deal with folk in frock coats, furbelows, and a gilt-edged period, is not devoid of the essential heat of conflict. Discounting for the gigantic stature and blood-thirstiness of old days, as they have come down to us in fairy-tale and legend, the folk of the old Sagas were Forsytes, assuredly, in their possessive instincts, and as little proof against the inroads of beauty and passion as Swithin, Soames, or even Young Jolyon. And if heroic figures, in days that never were, seem to startle out from their surroundings in fashion unbecoming to a Forsyte of the Victorian era, we may be sure that tribal instinct was even then the prime force, and that “family” and the sense of home and property counted as they do to this day, for all the recent efforts to “talk them out.”
map脚本:
1 # -*- coding: utf-8 -*- 2 import re 3 4 p = re.compile(r‘w+‘) 5 data_path = ‘E:\\PycharmProjects\\untitled\\hadoop-demo\\data\\The_man_of_property.txt‘ 6 with open(data_path,‘r‘,encoding=‘utf-8‘) as f: 7 for line in f.readlines(): 8 word_lst = line.strip().split(" ") 9 for word in word_lst: 10 re_word = p.findall(word) 11 if len(re_word) == 0: 12 continue 13 word = re_word[0].lower() 14 print("{0},{1}".format(word,1)) 15 16 17 输出结果: 18 19 preface,1 20 the,1 21 forsyte,1 22 saga,1 23 was,1 24 the,1 25 title,1 26 originally,1 27 28 ....
- reduce端代码示例3
如文本格式: which,1 which,1 which,1 which,1 which,1 whole,1 whose,1 whose,1 wild,1 will,1 will,1 will,1
reduce脚本:
1 # -*- coding: utf-8 -*- 2 3 data_path = ‘./data/reduce_test‘ 4 cur_word = None # null 5 sum = 0 6 with open(data_path,‘r‘, encoding=‘utf-8‘) as f: 7 for line in f.readlines(): 8 word,val = line.strip().split(‘,‘) 9 if cur_word == None: 10 cur_word = word 11 if cur_word != word: 12 print(‘%s,%s‘%(cur_word,sum)) 13 cur_word = word 14 sum = 0 15 sum += int(val) # sum = sum+val 16 print(‘%s,%s‘ % (cur_word, sum)) 17 18 输出结果: 19 20 which,5 21 whole,1 22 whose,2 23 wild,1 24 will,3
- master节点虚拟机运行代码,如本地单机调试模拟如下方法:
[root@master test]# head /data/The_man_of_property.txt | python map_t.py | sort -k1 | python red_t.py 输出结果: cat 1 run 3 see 2 spot 2 the 1
脚本执行流程:
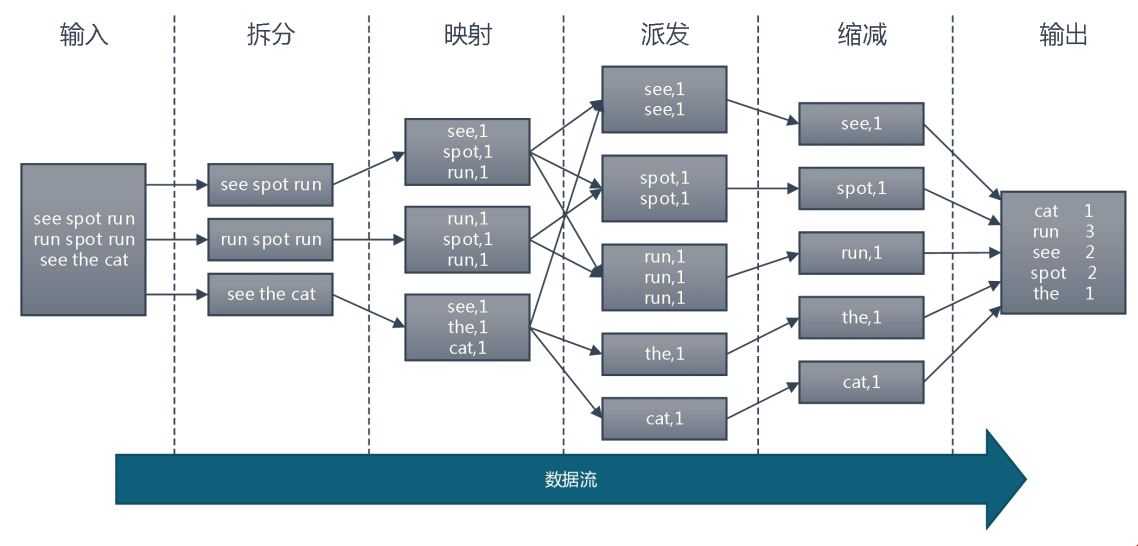
- 文件放在hdfs执行脚本方法:
map端脚本:
#!/usr/local/bin/ython import sys import re p = re.compile(r‘w+‘) for line in sys.stdin: ss = line.strip().split(‘ ‘) for s in ss: if len(p.findall(s))<1: continue s_low = p.findall(s)[0].lower() print s_low+‘,‘+‘1‘
reduce端脚本:
#!/usr/local/bin/python import sys cur_word = None sum = 0 for line in sys.stdin: word,val = line.strip().split(‘,‘) if cur_word==None: cur_word = word if cur_word!=word: print ‘%s %s‘%(cur_word,sum) cur_word = word sum = 0 sum+=int(val) print ‘%s %s‘%(cur_word,sum)
运行脚本:
HADOOP_CMD="/usr/local/src/hadoop-2.6.1/bin/hadoop" STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar" INPUT_FILE_PATH_1="/data/The_man_of_property.txt" OUTPUT_PATH="/output/wc" $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH # Step 1. $HADOOP_CMD jar $STREAM_JAR_PATH -input $INPUT_FILE_PATH_1 -output $OUTPUT_PATH -mapper "python map_t.py" -reducer "python red_t.py" -file ./map_t.py -file ./red_t.py
- hadoop常用命令
创建目录 使用方法:hadoop fs -mkdir <paths> 上传文件 使用方法:hadoop fs -put <localsrc> ... <dst> 查看目录 使用方法:hadoop fs -ls <args> 创建一个空文件 使用方法:hadoop fs -touchz URI [URI …] 删除一个文件 使用方法:hadoop fs -rm URI [URI …] 删除一个目录 使用方法:hadoop fs -rmr URI [URI …] 查看文件内容 使用方法:hadoop fs -cat URI [URI …] 将目录拷贝到本地 使用方法:hadoop fs -cp URI [URI …] <dest> ?移动文件 使用方法:hadoop fs -mv URI [URI …] <dest>
前提条件需要先启动hadoop集群:/usr/local/src/hadoop-2.6.1/sbin/start-all.sh
[root@master test]# hadoop fs -ls / Found 4 items drwxr-xr-x - root supergroup 0 2019-11-07 00:13 /data drwxr-xr-x - root supergroup 0 2019-10-26 00:20 /hbase drwxr-xr-x - root supergroup 0 2020-01-28 12:51 /output drwx-wx-wx - root supergroup 0 2019-11-06 23:51 /tmp [root@master test]# hadoop fs -ls /data Found 1 items -rw-r--r-- 3 root supergroup 632207 2019-11-07 00:13 /data/The_man_of_property.txt
执行sh run.sh
可见执行后输出的结果文件:
[root@master test]# hadoop fs -ls /output/wc Found 2 items -rw-r--r-- 3 root supergroup 0 2020-01-28 12:51 /output/wc/_SUCCESS -rw-r--r-- 3 root supergroup 92691 2020-01-28 12:51 /output/wc/part-00000
查看统计结果:hadoop fs -cat /output/wc/part-00000
以上是关于MapReduce计算框架的主要内容,如果未能解决你的问题,请参考以下文章