selenium爬虫之爬取疫情实时动态
Posted billie52707
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了selenium爬虫之爬取疫情实时动态相关的知识,希望对你有一定的参考价值。
import csv
import selenium.webdriver
from selenium.webdriver.chrome.options import Options
class spider():
def get_msg(self,url):
global timeNum, provinceDic
# 无窗口弹出操作
options = Options()
options.add_argument(‘--headless‘)
options.add_argument(‘--disable-gpu‘)
driver=selenium.webdriver.Chrome(options=options)
driver.get(url)
timeNum=driver.find_element_by_xpath(‘//*[@id="charts"]/div[2]/span[1]‘).text#实时
icbar_confirm=driver.find_element_by_xpath(‘//*[@id="charts"]/div[3]/div[1]/div[1]‘).text#全国确诊数
icbar_suspect=driver.find_element_by_xpath(‘//*[@id="charts"]/div[3]/div[2]/div[1]‘).text#疑似病例数
icbar_cure=driver.find_element_by_xpath(‘//*[@id="charts"]/div[3]/div[3]/div[1]‘).text#治愈人数
icbar_dead=driver.find_element_by_xpath(‘//*[@id="charts"]/div[3]/div[4]/div[1]‘).text#死亡人数
print("{} 全国确诊:{} 疑似病例:{} 治愈人数:{} 死亡人数:{} ".format(timeNum, icbar_confirm, icbar_cure, icbar_dead,icbar_suspect))
place_current=driver.find_elements_by_css_selector(‘div[class="place current"]‘)#湖北省的数据
place = driver.find_elements_by_css_selector(‘div[class="place"]‘)#其他省的数据
place_= driver.find_elements_by_css_selector(‘div[class="place "]‘)#其他省的数据
place_no_sharp = driver.find_elements_by_css_selector("div[class=‘place no-sharp ‘]")#自治区的数据
tplt = "{0:{4}<10} {1:{4}<15} {2:{4}<15} {3:{4}<15}"
print(tplt.format("地区","确诊人数","治愈人数","死亡人数",chr(12288)) + " ")
# 建立一个字典,键为省名,值为省的具体数据
provinceDic=dict()
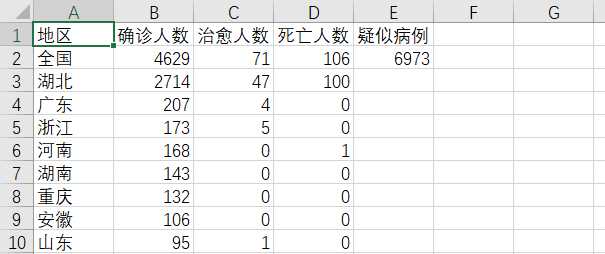
provinceDic["全国"]=["全国",icbar_confirm, icbar_cure, icbar_dead, icbar_suspect]
places = place_current + place + place_ + place_no_sharp # 所有的行省的数据列表合集
for place in places:
# print(place.text)
name=place.find_element_by_css_selector("span[class=‘infoName‘]").text
confirm=place.find_element_by_css_selector("span[class=‘confirm‘] span").text
try:
heal=place.find_element_by_css_selector("span[class=‘heal ‘] span").text
except:
heal = place.find_element_by_css_selector("span[class=‘heal hide‘] span").text
try:
dead=place.find_element_by_css_selector("span[class=‘dead ‘] span").text
except:
dead=place.find_element_by_css_selector("span[class=‘dead hide‘] span").text
print(tplt.format(name,confirm,heal,dead,chr(12288)))
provinceDic[name]=[name,confirm,heal,dead]
def save_data_as_csv(self,filename,dataList):
# filename="_".join(time.split(":"))
filename=filename.replace(":"," ")#调整时间
with open(filename+".csv","w",newline="") as f:
writer=csv.writer(f)
writer.writerow(["地区","确诊人数","治愈人数","死亡人数","疑似病例"])
for i in dataList:
writer.writerow(i)
f.close()
def main(self):
url = "https://news.qq.com/zt2020/page/feiyan.htm"
self.get_msg(url)
self.save_data_as_csv(timeNum,provinceDic.values())
billie=spider()
billie.main()
以上是关于selenium爬虫之爬取疫情实时动态的主要内容,如果未能解决你的问题,请参考以下文章