正则表达式(re.compile/re.match/re.split用法)
Posted douzujun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式(re.compile/re.match/re.split用法)相关的知识,希望对你有一定的参考价值。
1. 正则表达式
https://www.cnblogs.com/douzujun/p/7446448.html
2. re.compile
如果一个正则表达式要重复使用几千次,出于效率的考虑,我们可以预编译该正则表达式,接下来重复使用时就不需要编译这个步骤了,直接匹配:
>>> import re
# 编译:
>>> re_telephone = re.compile(r‘^(d{3})-(d{3,8})$‘)
# 使用:
>>> re_telephone.match(‘010-12345‘).groups()
(‘010‘, ‘12345‘)
>>> re_telephone.match(‘010-8086‘).groups()
(‘010‘, ‘8086‘)
(1)用法1

(2)用法2
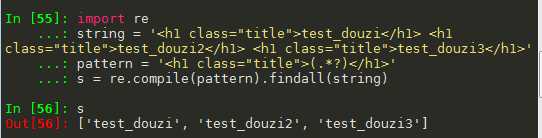
import re string = ‘<h1 class="title">test_douzi</h1> <h1 class="title">test_douzi2</h1> <h1 class="title">test_douzi3</h1>‘ pattern = ‘<h1 class="title">(.*?)</h1>‘ s = re.compile(pattern).findall(string)
3. re.split()
>>> ‘a b c‘.split(‘ ‘) [‘a‘, ‘b‘, ‘‘, ‘‘, ‘c‘] 嗯,无法识别连续的空格,用正则表达式试试: >>> re.split(r‘s+‘, ‘a b c‘) [‘a‘, ‘b‘, ‘c‘] 无论多少个空格都可以正常分割。加入 , 试试: >>> re.split(r‘[s,]+‘, ‘a,b, c d‘) [‘a‘, ‘b‘, ‘c‘, ‘d‘] 再加入;试试: >>> re.split(r‘[s,;]+‘, ‘a,b;; c d‘) [‘a‘, ‘b‘, ‘c‘, ‘d‘]
4. re.match()
>>> m = re.match(r‘^(d{3})-(d{3,8})$‘, ‘010-12345‘) >>> m <_sre.SRE_Match object; span=(0, 9), match=‘010-12345‘> >>> m.group(0) ‘010-12345‘ >>> m.group(1) ‘010‘ >>> m.group(2) ‘12345‘
以上是关于正则表达式(re.compile/re.match/re.split用法)的主要内容,如果未能解决你的问题,请参考以下文章