ST表算法入门详解
Posted soul-maker
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ST表算法入门详解相关的知识,希望对你有一定的参考价值。
ST表算法入门详解
关于ST表,有很多文章,这里本蒟蒻也来发一波~~ 希望能为您提供帮助~~
1.ST表的介绍
ST表算法全称Sparse-Table算法,是由Tarjan提出的一种解决RMQ问题(区间最值)的强力算法。离线预处理时间复杂度 θ(nlogn),在线查询时间 θ(1),可以说是一种非常高效的算法。不过ST表的应用场合也是有限的,它只能处理静态区间最值,不能维护动态的,也就是说不支持在预处理后对值进行修改。一旦修改,整张表便要重新计算,时间复杂度极高。动态最值可以用线段树、树状数组等来维护。
2.ST表的一般实现
ST表之所以广为使用,不仅因为它的时间复杂度优秀,还因为它的代码思路比较清晰,码量比较合适。核心的代码主要集中预处理和查询上。那么接下来我们就先来讲讲它的预处理(下面都以区间最小值来讲,最大值可以类推)。设st[i][j]表示从第 i 个数起向后连续2^j个数中的最小值。注意,是包括第 i 个数在内的2^j个数。那么,我们可以得到转移方程:
1.st[i][0]=第i个数(很明显,2^0==1,从第i个数起向后数1个数,当然只有它自己。)
2.st[i][j]=min{ st[i][j-1] , st[i+(1<<j-1)][j-1]}(j≠0)(其实也挺好理解的。请看下图:)
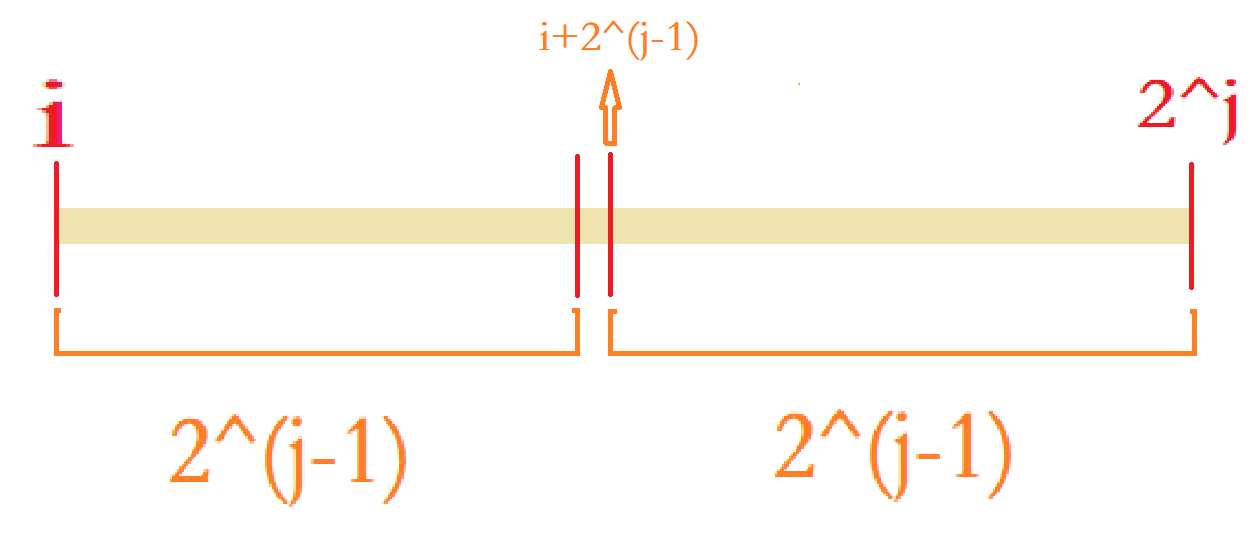
(把整个2的j次方区间分成两个2^(j-1)区间,那么整个大区间的最小值就是两个已计算过的区间最小值的最小值。第一个区间很明白,是st[i][j-1],就是从左端点 i 起向右数2^(j-1) 个数。第二个区间长度还是2^(j-1),但是左端点需要由 i 加上上一个区间的长度,毕竟它们是连在一起的。)
以上,就是ST表的初始化部分。
接下来,我们来讲讲查询。假设每次查询的左右端点分别为le和ri。思路:首先找到一个值k,k的含义是“最大的2^k不超过查询区间长度(ri-le+1)”。举个例子:le=1,ri=9,那么k最大为3,2^k==8,不超过区间长度。那么我们找两个长度为2^k的区间,一个以le为左端点,一个以ri为右端点。由于k最大,所以可以肯定,这两个小区间一定覆盖了整个大区间。那么,虽然两个小区间会有重叠部分,但是这里要求的是最小值,而非求和,所以这两个小区间最小值中的最小值,一定是整个区间的最小值!
再细一点的说,一个区间为st[le][k],还有一个为st[ri-(1<<k)+1][k],那么:
查询函数query(le,ri)=min{st[le][k],st[ri-(1<<k)+1][k]}。再次强调:重叠的小区间不影响整个区间的最小值!
再总结一下查询的过程:1.找到k 2.返回两个st之间的最值
到这里,ST表的一般实现已被剖析完毕。下面为大家提供多次查询区间最小值的代码。


1 #include<bits/stdc++.h> 2 #define MX 100005 3 using namespace std; 4 int n,ans[(MX<<1)+MX<<3],st[MX][17]; 5 void getrd(){ 6 for(int j=1;(1<<j)<=n;j++) 7 for(int i=1;i+(1<<j)-1<=n;i++) 8 st[i][j]=max(st[i][j-1],st[i+(1<<j-1)][j-1]); 9 } 10 int query(int le,int ri){ 11 int k=0;while(le+(1<<k+1)-1<=ri)k++; 12 return max(st[le][k],st[ri-(1<<k)+1][k]); 13 } 14 int main(){ 15 int m;cin>>n>>m; 16 for(int i=1;i<=n;i++)cin>>st[i][0]; 17 getrd(); 18 for(int i=1;i<=m;i++){int le,ri;cin>>le>>ri;ans[i]=query(le,ri);} 19 for(int i=1;i<=m;i++)cout<<ans[i]<<endl; 20 return 0; 21 }
3.浅谈ST表应用之LCA
ST表算法其实真的很好理解的。下面我们来讲讲它的拓展应用:求LCA。如果你连LCA是啥都不知道,请务必缓一缓再读哈~~。LCA作为树状结构的高频考点,有多种算法和思路。主要是应用倍增算法。其实这题还可以用ST表来做,这样单次查询的时间就是θ(1)。此算法对于多次查询比较实用。
怎么实现呢?首先,我们将给定的树的欧拉序列表示出来。什么叫欧拉序列呢?就是对这棵树进行DFS,每到一个点都把它的序号加入这个序列,比如以下这棵树:
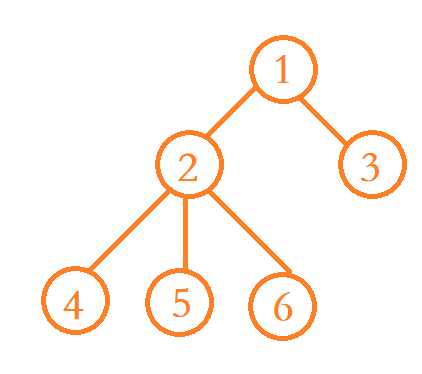
它的DFS序为1-2-4-5-6-3,这是每个点的访问顺序,但不是它的欧拉序列,因为欧拉序列每回溯一步都要记录。它的欧拉序列应该是:1-2-4-2-5-2-6-2-1-3。那么明白了欧拉序列有什么用呢?接下来,我们将欧拉序列中点的深度也一并表示出来:
序号:1-2-4-2-5-2-6-2-1-3
深度:0-1-2-1-2-1-2-1-0-1
你会发现,两个点的LCA,就是以这两个点为左右端点的深度序列中深度最小的点的序号!比如,我们要查询点3和点4,首先在序号序列中找到它们,分别是第三个和最后一个序号,再到深度序列中以第三个点为左端点,最后一个点为右端点的子序列中寻找深度最小的点,发现是倒数第二个点,它的深度为0。那么,这个点就一定是它们的LCA。挺好理解的吧~~。
那么接下来肯定有人要问了,如果要查询的点在序列中多次出现,怎么办呢?这种情况也不怕,随便选一次出现就好了!!!!比如上一例中的2号点,多次出现,可以随便选一个出现的位置来做。
那么,这个算法的原理,以及可以随便选出现位置,的原理是什么呢?其实很简单,仔细想想就知道,就是在找两点间DFS访问的“岔路口”,而欧拉序列,相当于把整条路摊开,深度最小的,就是岔路口。算法实现也很简单了,先找出欧拉序列,再完善ST表,最后查询出结果~~
4.朴实地结束
谢谢!这篇博客就到此结束了!希望对你有帮助!喜欢的话记得点赞哦~~
以上是关于ST表算法入门详解的主要内容,如果未能解决你的问题,请参考以下文章