Sqoop 一点通
Posted wangzhiyong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Sqoop 一点通相关的知识,希望对你有一定的参考价值。
sqoop 是什么?
sqoop 主要用于异构数据:
1. 将数据从hadoop,hive 导入、导出到关系型数据库mysql 等;
2. 将关系型数据库 mysql 中数据导入、导出到 hadoop 、hve 。
sqoop 版本说明
sqoop 1 版本主要从1.4.0 到 1.4.7;sqoop 2 版本主要从1.99.1 到1.99.7。
sqoop1 和 sqoop2 的主要区别
sqoop2 对 sqoop 1 主要在性能、安全方面做了优化升级,并新增了服务端,sqoop2 可以通过编程 rest api 的方式进行数据同步,不过目前 sqoop 2 没有实现将 mysql 数据直接导入到 hive,可以用 sqoop 1 版本通过 shell 客户端脚本方式实现 mysql 同步 hive 功能。
sqoop 基本原理
sqoop 1 主要通过 hadoop 的分布式计算 mapreduce 任务进行数据的同步。
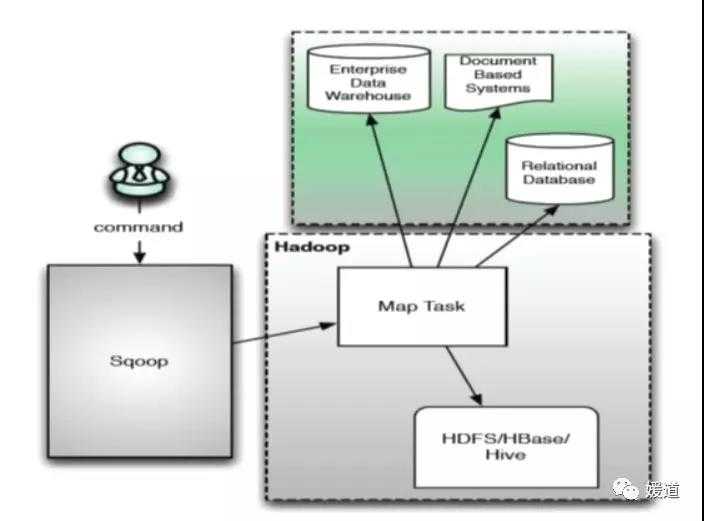
(sqoop1 架构)
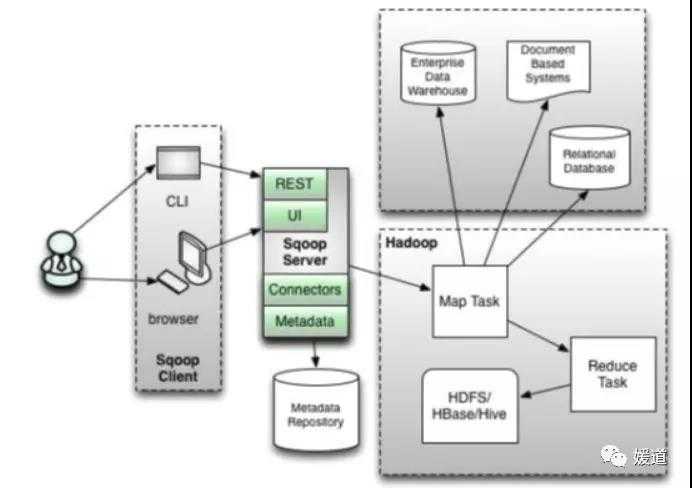
(sqoop 2 架构)
sqoop 命令
将 mysql 中数据导入到 hive 为例,包括全量、增量导入:
$ sqoop import
--connect jdbc:mysql://ip:3306/db 数据库连接串
--username root 用户名
--password root 密码
--split-by id 执行并行分批字段,一般主健,配合 -m 使用
-m 2 mapper 数
--fields-terminated-by " " 导出字段分隔符,此次为制表符为分隔符
--lines-terminated-by " " 换行符
--hive-import
--create-hive-table 创建 hive 表,如果目标表已经存在了,那么创建任务会失败
--hive-table pas_med_info hive 表名
--null-string ‘\\N‘ 将mysql 中的NULL数据转换为hive 的 NULL
--target-dir /apps/hive/warehouse/db/dt=‘日期‘ hive 在 hdfs 存储路径,dt=‘日期‘ 可以分区导入,当写成脚本时可以将日期做为变量,每天定时同步导入。
-- query where [可选] 增量导入方式一 ,推荐使用,直接可以用shell 脚本定时跑数据,方便简单
--incremental append或lastmodify [可选] 增量导入方式二,操作一
--append [可选] 如果选择lastmodify 则需要添加此命令,配合操作一使用
–check-column createtime [可选] 用于检查增量数据的列 ,必须是 timestamp 列,配合操作一使用
Sqoop2 代码示例
以 java 语言,将 mysql 中数据导入到 hdfs 为例:
1. 添加依赖
<dependency>
<groupId>org.apache.sqoop</groupId>
<artifactId>sqoop-client</artifactId>
<version>1.99.7</version>
</dependency>
2. 创建 sqoop 客户端
String url = "http://ip:12000/sqoop/";
SqoopClient client = new SqoopClient(url);
client.setServerUrl(url);
3. 创建 mysql link
4. 创建 hdfs link
5. 创建 job 并提交同步数据任务
限于篇幅,就不大量贴代码了,请关注公众号,私信我,我会将完整实例发你。
请关注公众号:媛道

以上是关于Sqoop 一点通的主要内容,如果未能解决你的问题,请参考以下文章