爬取免费小说
Posted a-runner
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取免费小说相关的知识,希望对你有一定的参考价值。
今天小编学些了用xpath爬取小说网,权当练习。
xpath是路径语言。
小说(免费)网址:http://book.zongheng.com/showchapter/896071.html
首先,小编随便点开了一个小说。
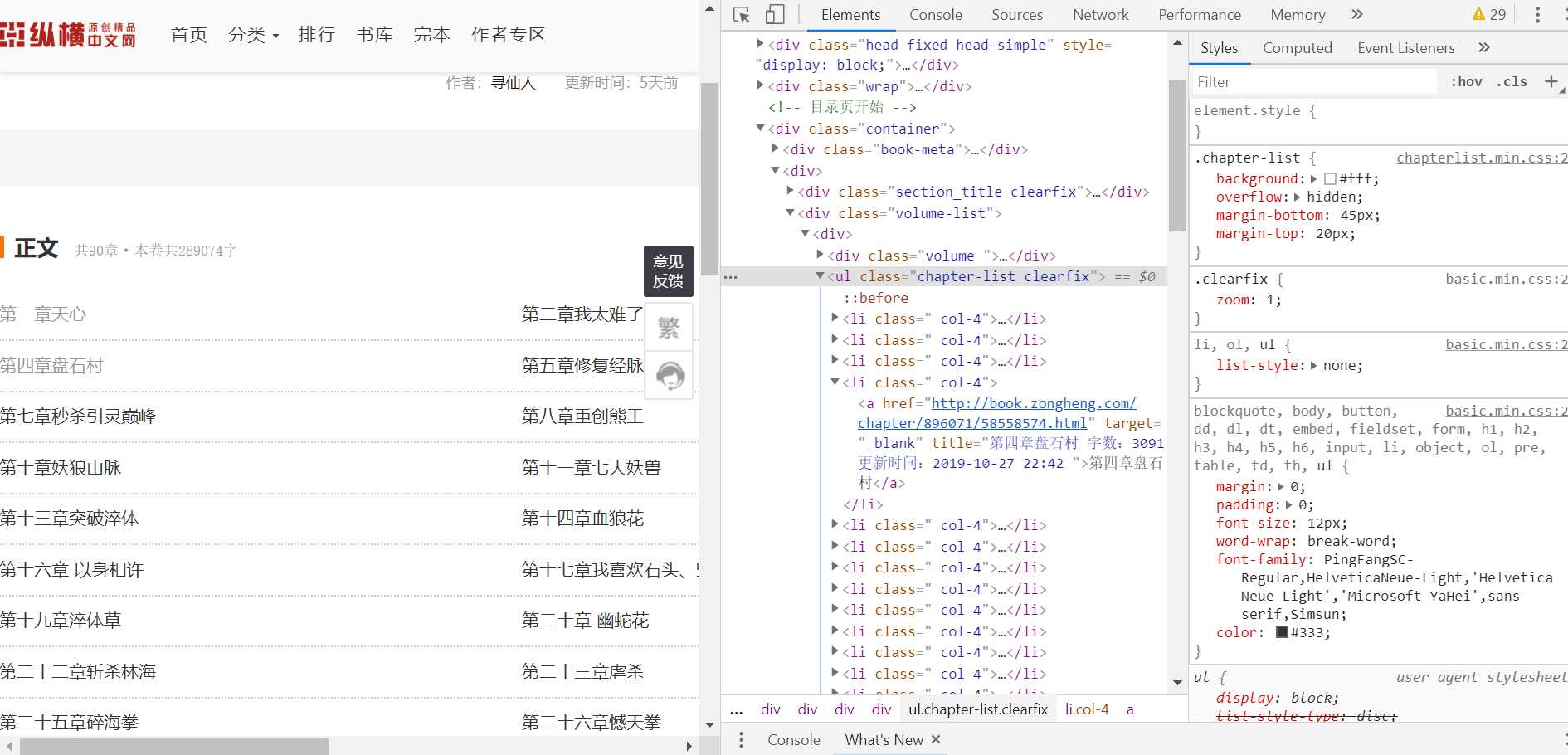
可以看到,小说每个章节的title,url都在ul这个无序标签里面,只需用xpath遍历即可。
首先先打开对应的一个网址,查看对应的小说的内容位置。

可以看到,第一章节的内容都在div标签中,且class属性为content。
import requests from lxml import etree def get_chapter_name(url): html = requests.get(url).text page_source = etree.HTML(html) chapters_url = page_source.xpath(‘//ul[@class="chapter-list clearfix"]/li/a/@href‘) chapters_name = page_source.xpath(‘//ul[@class="chapter-list clearfix"]/li/a/text()‘) for chapter_url, chapter_name in zip(chapters_url, chapters_name): get_text(chapter_url, chapter_name) print(‘完毕!!!‘) def get_text(chapter_url, chapter_name): # 获取网页内容 html = requests.get(chapter_url).text page = etree.HTML(html) text_tag = page.xpath(‘//div[@class="content"]//p//text()‘) text = ‘ ‘.join(text_tag) path = ‘破天传人/{}.txt‘.format(chapter_name) with open(path, ‘w‘, encoding=‘utf-8‘) as f: f.write(text) print(path + ‘ 写入完毕!!!‘) if __name__ == ‘__main__‘: url = ‘http://book.zongheng.com/showchapter/896071.html‘ get_chapter_name(url)
以上是关于爬取免费小说的主要内容,如果未能解决你的问题,请参考以下文章