设计理念存储与检索
Posted ryan16231112
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了设计理念存储与检索相关的知识,希望对你有一定的参考价值。
存储与检索
数据库如何存储我们提供的数据,以及如何在我们需要时重新找到数据。
日志结构的存储引擎
可以实现一个简单的数据库,这个数据库只在结尾不断加入数据,在查询的时候返回从结尾找到的第一条数据,这样的数据库成为仅追加式的数据库,也即日志模式。
为了高效查找数据库中特定键的值,我们需要一个数据结构:索引(index)。索引背后的大致思想是,保存一些额外的元数据作为路标,帮助你找到想要的数据。。许多数据库允许添加与删除索引,这不会影响数据的内容,它只影响查询的性能。维护额外的结构会产生开销,特别是在写入时。写入性能很难超过简单地追加写入文件,因为追加写入是最简单的写入操作。任何类型的索引通常都会减慢写入速度,因为每次写入数据时都需要更新索引。
一种好的解决方案是,将日志分为特定大小的段,当日志增长到特定尺寸时关闭当前段文件,并开始写入一个新的段文件。然后,我们就可以对这些段进行压缩。压缩意味着在日志中丢弃重复的键,只保留每个键的最近更新。而且,由于压缩经常会使得段变得很小,我们也可以在执行压缩的同时将多个段合并在一起。
段被写入后永远不会被修改,所以合并的段被写入一个新的文件。冻结段的合并和压缩可以在后台线程中完成,在进行时,我们仍然可以继续使用旧的段文件来正常提供读写请求。合并过程完成后,我们将读取请求转换为使用新的合并段而不是旧段 —— 然后可以简单地删除旧的段文件。
索引
hash索引
最简单的索引策略就是:保留一个内存中的哈希映射,其中每个键都映射到一个数据文件中的字节偏移量,指明了可以找到对应值的位置。当你将新的键值对追加写入文件中时,还要更新散列映射,以反映刚刚写入的数据的偏移量(这同时适用于插入新键与更新现有键)。当你想查找一个值时,使用哈希映射来查找数据文件中的偏移量,寻找该位置并读取该值。
哈希表索引也有局限性:
- 散列表必须能放进内存
如果你有非常多的键,那真是倒霉。原则上可以在磁盘上保留一个哈希映射,不幸的是磁盘哈希映射很难表现优秀。它需要大量的随机访问I/O,当它变满时增长是很昂贵的,并且散列冲突需要很多的逻辑。 - 范围查询效率不高。例如,您无法轻松扫描kitty00000和kitty99999之间的所有键——必须在散列映射中单独查找每个键。
SSTables和LSM树
现在我们可以对段文件的格式做一个简单的改变:我们要求键值对的序列按键排序。我们把这个格式称为排序字符串表(Sorted String Table),简称SSTable。我们还要求每个键只在每个合并的段文件中出现一次(压缩过程已经保证)。
- 合并段是简单而高效的,即使文件大于可用内存。这种方法就像归并排序算法中使用的方法一样。查看每个文件中的第一个键,复制最低键(根据排序顺序)到输出文件,并重复。
- 为了在文件中找到一个特定的键,不再需要保存内存中所有键的索引。(因为键带序)
构建和维护SSTables
有许多可以使用的众所周知的树形数据结构,例如红黑树或AVL树。使用这些数据结构,可以按任何顺序插入键,并按排序顺序读取它们。完整的工作如下:
- 写入时,将其添加到内存中的平衡树数据结构(例如,红黑树)。这个内存树有时被称为内存表。
- 当内存表大于某个阈值(通常为几兆字节)时,将其作为SSTable文件写入磁盘。这可以高效地完成,因为树已经维护了按键排序的键值对。新的SSTable文件成为数据库的最新部分。当SSTable被写入磁盘时,写入可以继续到一个新的内存表实例。
- 为了提供读取请求,首先尝试在内存表中找到关键字,然后在最近的磁盘段中,然后在下一个较旧的段中找到该关键字。
- 有时会在后台运行合并和压缩过程以组合段文件并丢弃覆盖或删除的值。
制造LSM树
如上的工作被称为LSM树。
LSM树的基本思想 —— 保存一系列在后台合并的SSTables —— 简单而有效。即使数据集比可用内存大得多,它仍能继续正常工作。由于数据按排序顺序存储,因此可以高效地执行范围查询(扫描所有高于某些最小值和最高值的所有键),并且因为磁盘写入是连续的,所以LSM树可以支持非常高的写入吞吐量。
B树
B树将数据库分解成固定大小的块或页面,传统上大小为4KB(有时会更大),并且一次只能读取或写入一个页面。每个页面都可以使用地址或位置来标识,这允许一个页面引用另一个页面 —— 类似于指针,但在磁盘而不是在内存中。我们可以使用这些页面引用来构建一个页面树。
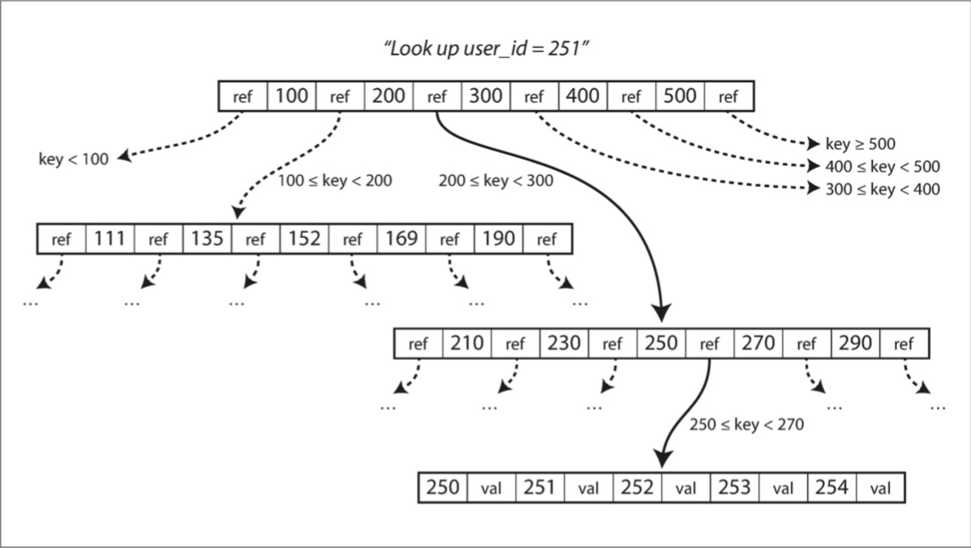
一个页面会被指定为B树的根;在索引中查找一个键时,就从这里开始。该页面包含几个键和对子页面的引用。每个子页面负责一段连续范围的键,引用之间的键,指明了引用子页面的键范围。
在图中的例子中,我们正在寻找关键字 251 ,所以我们知道我们需要遵循边界 200 和 300之间的页面引用。这将我们带到一个类似的页面,进一步打破了200 - 300到子范围。
在B树的一个页面中对子页面的引用的数量称为分支因子。例如,在图中,分支因子是 6。在实践中,分支因子取决于存储页面参考和范围边界所需的空间量,但通常是几百个。
如果你想添加一个新的键,你需要找到其范围包含新键的页面,并将其添加到该页面。如果页面中没有足够的可用空间容纳新键,则将其分成两个半满页面,并更新父页面以解释键范围的新分区。
该算法确保树保持平衡:具有 n 个键的B树总是具有 $O(log n)$ 的深度。大多数数据库可以放入一个三到四层的B树,所以你不需要遵追踪多页面引用来找到你正在查找的页面。
为了使数据库对崩溃具有韧性,B树实现通常会带有一个额外的磁盘数据结构:预写式日志(WAL, write-ahead-log)(也称为重做日志(redo log))。这是一个仅追加的文件,每个B树修改都可以应用到树本身的页面上。当数据库在崩溃后恢复时,这个日志被用来使B树恢复到一致的状态。
比较B树和LSM树
根据经验,通常LSM树的写入速度更快,而B树的读取速度更快。
在某些情况下,从索引到堆文件的额外跳跃对读取来说性能损失太大,因此可能希望将索引行直接存储在索引中。这被称为聚集索引。例如,在mysql的InnoDB存储引擎中,表的主键总是一个聚簇索引,二级索引用主键。
内存数据库
内存数据库的性能优势并不是因为它们不需要从磁盘读取。即使是基于磁盘的存储引擎也可能永远不需要从磁盘读取,因为操作系统缓存最近在内存中使用了磁盘块。相反,它们更快的原因在于省去了将内存数据结构编码为磁盘数据结构的开销。
除了性能,内存数据库的另一个有趣的领域是提供难以用基于磁盘的索引实现的数据模型。例如,Redis为各种数据结构(如优先级队列和集合)提供了类似数据库的接口。因为它将所有数据保存在内存中,所以它的实现相对简单。
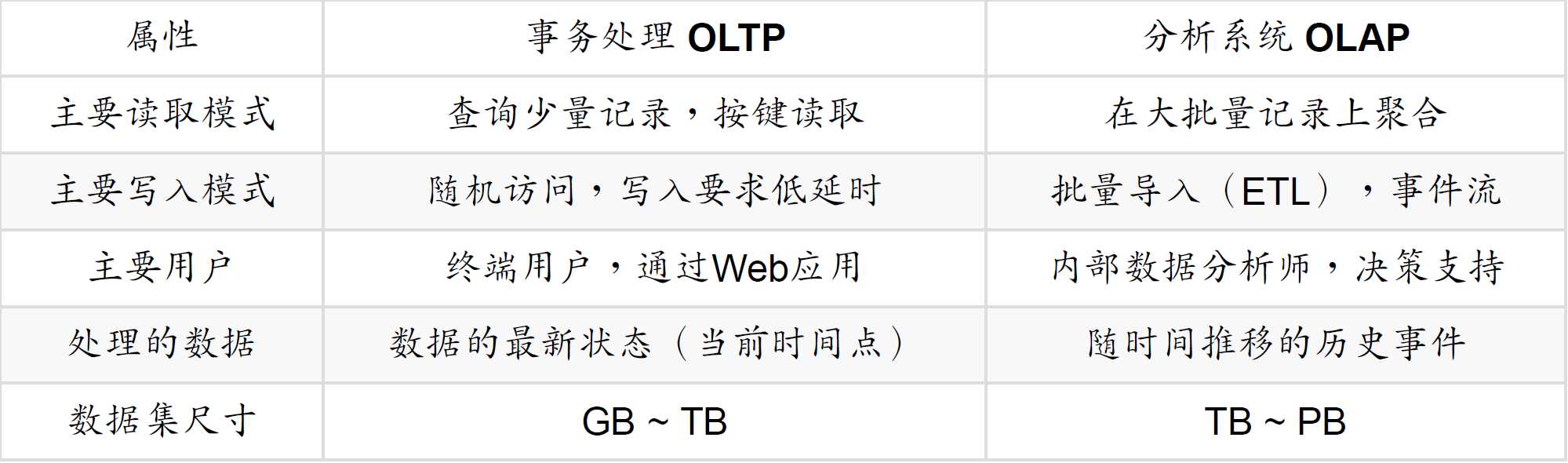
事务处理与事务分析
以上是关于设计理念存储与检索的主要内容,如果未能解决你的问题,请参考以下文章