MachineLearning入门-4
Posted yuzaihuan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MachineLearning入门-4相关的知识,希望对你有一定的参考价值。
查看数据本身也是一个很好理解数据的方法,通过查看数据可以直观的看到数据的特征,数据的类型以及大概的数据分布范围。
1 #查看数据的前10行 2 print(dataset.head(10))
separ-length separ-width petal-length petal-width class 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa 5 5.4 3.9 1.7 0.4 Iris-setosa 6 4.6 3.4 1.4 0.3 Iris-setosa 7 5.0 3.4 1.5 0.2 Iris-setosa 8 4.4 2.9 1.4 0.2 Iris-setosa 9 4.9 3.1 1.5 0.1 Iris-setosa
数据特征的统计信息包括数据的行数,中位值,最大值,最小值,均值,四分位值等统计数据信息。
1 #统计描述数据信息 2 print(dataset.describe())
separ-length separ-width petal-length petal-width count 150.000000 150.000000 150.000000 150.000000 mean 5.843333 3.054000 3.758667 1.198667 std 0.828066 0.433594 1.764420 0.763161 min 4.300000 2.000000 1.000000 0.100000 25% 5.100000 2.800000 1.600000 0.300000 50% 5.800000 3.000000 4.350000 1.300000 75% 6.400000 3.300000 5.100000 1.800000 max 7.900000 4.400000 6.900000 2.500000
查看数据分布是否均衡:
1 #分类分布情况 2 print(dataset.groupby(‘class‘).size())
class Iris-setosa 50 Iris-versicolor 50 Iris-virginica 50 dtype: int64
上面我们看到鸢尾花三个亚属各50条,分布非常平衡。如果数据的分布不平衡时,可能会影响到模型的准确度。当数据分布不平衡时,需要对数据进行处理,调整数据到相对平衡的状态。调整数据平衡时有以下几种方式。
1、扩大数据样本
2.数据的重新抽样:过抽样(复制少数样本)和欠抽样(删除多数样本)。当数据量很大时可以考虑测试欠抽样(大于一万条记录),当数据量比较少时可以考虑过抽样。
3.尝试生成人工样本
4.异常检测和变化检测
通过对数据集的审查,对数据有了一个基本了解,接下来通过图表来进一步查看数据特征的分布情况和数据不同特征之间的相互关系。
a/ 使用单变量图表可以更好的理解每一个特征属性
b/ 多变量图表用于理解不同特征属性之间的关系
1 #箱线图 2 dataset.plot(kind=‘box‘,subplots=True,layout=(2,2),sharex=False,sharey=False) 3 pyplot.show()
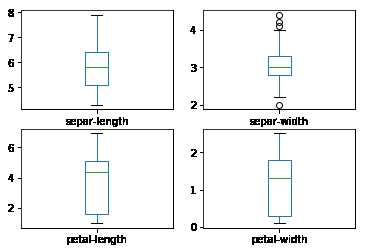
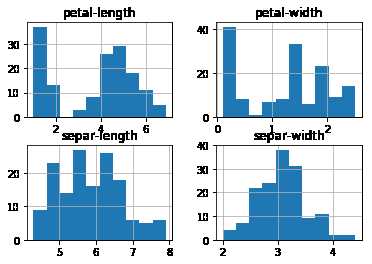
还可以通过直方图来显示每个特征属性的分布情况。
1 #直方图 2 dataset.hist() 3 pyplot.show()
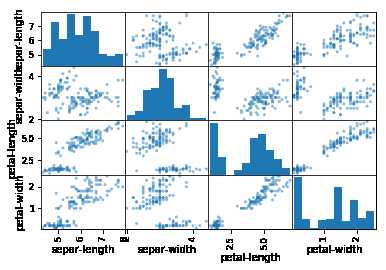
通过散点矩阵图可以查看每个属性之间的影响关系。
1 #散点矩阵图 2 scatter_matrix(dataset) 3 pyplot.show()
通过不同的算法来创建模型,并评估它们的准确度,以便找到合适的算法。将按照下面的步骤进行操作:
1、分离出评估数据集
2.、采用10折交叉验证来评估算法模型
3、生成6个不同的模型来预测新数据
4、选择最优模型
分离出评估数据集
模型被创建后需要知道创建的模型是否足够好。在选择算法的过程中采用统计学方法来评估算法模型。但是,我们更想知道算法模型对真实数据的准确度如何,这就是保留一部分数据来评估算法模型的主要原因。下面按照80%的训练数据集,20%的评估数据集来分离数据。
1 #分离数据集 2 array=dataset.values 3 x=array[:,0:4] 4 y=array[:,4] 5 validation_size=0.2 6 seed=7 7 x_train,x_validation,y_train,y_validation=train_test_split(x,y,test_size=validation_size,random_state=seed)
现在就分离出x_train和y_train用来训练算法创建模型,x_validation和y_validation在后面会用来验证评估模型。
上面出现了一个未见过的函数:train_test_split(),这可能是一个内置函数,方便用户直接分离Train和Test数据集。
评估模型
在这里将通过10折交叉验证来分离训练数据集,并评估算法模型的准确度。10折交叉验证是随机的将数据分成10份;9份用来训练模型,1份用来评估算法。后面将会使用相同的数据对每一种算法进行评估,并从中选择最好的模型。
创建模型
对任何问题来说,不能仅仅通过对数据审查,就能判断出哪个算法最有效。通过上卖弄的图表,发现有些数据特征符合线性分布,所有可以期待算法会得到比较好的结果。接下来评估六钟不同的算法:
- 线性回归(LR)
- 线性判别分析(LDA)
- K近邻(KNN)
- 分类与回归(CART)
- 贝叶斯分类器(NB)
- 支持向量机(SVM)
这个算法列表中包含了线性算法(LR和LDA)和非线性算法(KNN,CART,NB,SVM)。在每次对算法进行评估前都会重新设置随机数种子,以确保每次都是用相同的数据集,保证算法评估的准确性。接下来就创建并评估这六种算法模型。代码如下:
1 #算法审查 2 models={} 3 models[‘LR‘]=LogisticRegression() 4 models[‘LDR‘]=LinearDiscriminantAnalysis() 5 models[‘KNN‘]=KNeighborsClassifier() 6 models[‘CART‘]=DecisionTreeClassifier() 7 models[‘NB‘]=GaussianNB() 8 models[‘SVM‘]=SVC() 9 #评估算法 10 results=[] 11 for key in models: 12 kfold=KFold(n_splits=10,random_state=seed) 13 cv_results=cross_val_score(models[key],x_train,y_train,cv=kfold,scoring=‘accuracy‘) 14 results.append(cv_results) 15 print(‘%s: %f (%f)‘ % (key,cv_results.mean(),cv_results.std())) 16 print(‘--- ---‘)
LR: 0.966667 (0.040825) --- --- LDR: 0.975000 (0.038188) --- --- KNN: 0.983333 (0.033333) --- --- CART: 0.975000 (0.038188) --- --- NB: 0.975000 (0.053359) --- --- SVM: 0.991667 (0.025000) --- ---
选择最优模型
现在已经有六中模型,并且评估了它们的精确度。接下来就需要比较这六种模型,并选出准确度最高的算法。
上面算法中有一个分类与回归树算法CART,树算法生成的树模型可以通过图像的方式展示出来。
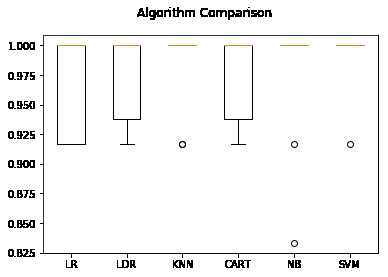
通过上面的结果,很容易看出SVM算法具有最高的准确度得分。接下来创建一个箱线图,通过图表来比较算法的评估结果。代码如下:
1 #箱线图比较算法 2 fig=pyplot.figure() 3 fig.suptitle(‘Algorithm Comparison‘) 4 ax=fig.add_subplot(111) 5 pyplot.boxplot(results) 6 ax.set_xticklabels(models.keys()) 7 pyplot.show()
实施预测
评估的结果显示,支持向量机SVM是准确度最高的的算法。现在使用预留的评估数据集来验证这个算法模型。这将会对生成的算法模型的准确度有一个更加直观的认识。
现在使用全部训练集的数据生成支持向量机SVM的算法模型,并用预留的评估数据集给出一个算法模型的报告。
1 #使用评估数据集评估算法 2 svm=SVC() 3 svm.fit(X=x_train,y=y_train) 4 predictions=svm.predict(x_validation) 5 print(accuracy_score(y_validation,predictions)) 6 print(confusion_matrix(y_validation,predictions)) 7 print(classification_report(y_validation,predictions))
0.9333333333333333
[[ 7 0 0]
[ 0 10 2]
[ 0 0 11]]
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 7
Iris-versicolor 1.00 0.83 0.91 12
Iris-virginica 0.85 1.00 0.92 11
micro avg 0.93 0.93 0.93 30
macro avg 0.95 0.94 0.94 30
weighted avg 0.94 0.93 0.93 30
执行程序后,看到算法模型的准确度是0.93.通过冲突矩阵看到只有两个数据预测错误。最后还提供了一个包含精确率(precision)。召回率(recall),F1值(F1-Score)等数据报告。
总结
到这里已经完成了第一个机器学习项目。包含从数据导入到生成模型,以及通过模型对数据进行分类的全部过程。
以上是关于MachineLearning入门-4的主要内容,如果未能解决你的问题,请参考以下文章