spark学习三
Posted zhang12345
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark学习三相关的知识,希望对你有一定的参考价值。
partition是RDD的最小单元,是盛放文件的盒子,一个文件可能需要多个partition,但是一个partition只能
存放一个文件中的内容,partition是spark计算中,生成的数据在计算空间内最小单元,
2.fileWriter.flush()
flush() 是清空,而不是刷新啊。
一般主要用在IO中,即清空缓冲区数据,就是说你用读写流的时候,其实数据是先被读到了内存中,
然后用数据写到文件中,当你数据读完的时候不代表你的数据已经写完了,因为还有一部分有可能
会留在内存这个缓冲区中。这时候如果你调用了 close()方法关闭了读写流,那么这部分数据就会
丢失,所以应该在关闭读写流之前先flush(),先清空数据。
是换行符,功能和" "是一致的,但是此种写法屏蔽了 Windows和Linux的区别 ,更保险一些.
4.val totalAge = lines.map(line=>line.split(" ")(1)).map(t=>t.trim.toInt).collect().reduce((a,b)=>a+b)
收集每行中的成绩,变成整型,然后求和
1.在 spark-shell 中读取 Linux 系统本地文件“/home/hadoop/test.txt”,然后统计出文 件的行数;
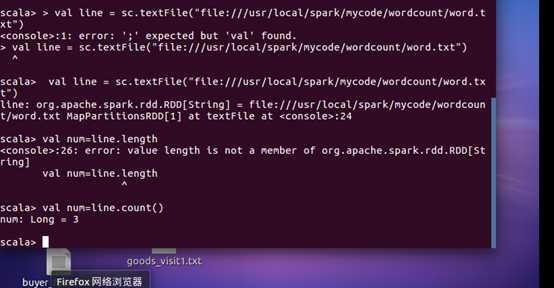
2.在 spark-shell 中读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在, 请先创建),然后,统计出文件的行数;
(1) 将文件上传到hdfs上
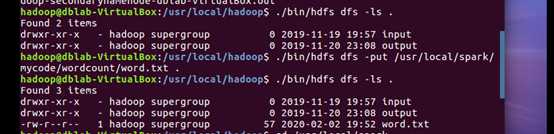
(2) 启动spark,并实现统计文件行数

3.编写独立应用程序,读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在, 请先创建),然后,统计出文件的行数;通过 sbt 工具将整个应用程序编译打包成 JAR 包, 并将生成的 JAR 包通过 spark-submit 提交到 Spark 中运行命令
(1) 创建文件夹以及scala文件

(2) 编写程序
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object WordCount {
def main(args: Array[String]) {
val inputFile = "hdfs://localhost:9000/user/hadoop/word.txt"
val conf = new SparkConf().setAppName("WordCount")
val sc = new SparkContext(conf)
val textFile = sc.textFile(inputFile)
val num=textFile.count()
println("文本的行数:%s".format(num))
}
}
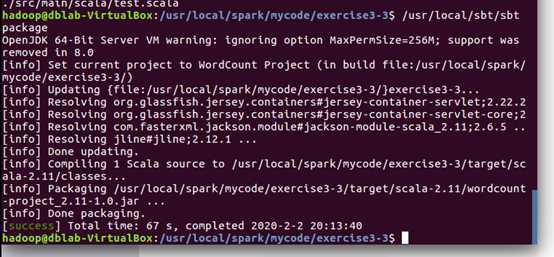
(3) 新建sbt文件

(4) 将程序打包成JAR
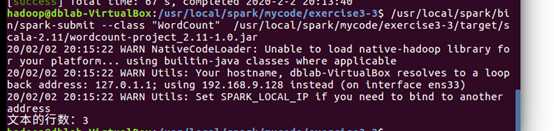
(5)通过 spark-submit 运行程序,将生成的 jar 包通过 spark-submit 提交到 Spark 中运行
以上是关于spark学习三的主要内容,如果未能解决你的问题,请参考以下文章