04 namenode和datanode
Posted zhaochengf
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了04 namenode和datanode相关的知识,希望对你有一定的参考价值。
namenode元数据管理
1、什么是元数据? hdfs的目录结构及每一个文件的块信息(块的id,块的副本数量,块的存放位置<datanode>) 2、元数据由谁负责管理? namenode 3、namenode把元数据记录在哪里? namenode的实时的完整的元数据存储在内存中; namenode还会在磁盘中(dfs.namenode.name.dir)存储内存元数据在某个时间点上的镜像文件; namenode会把引起元数据变化的客户端操作记录在edits日志文件中;
namenode主要功能模块
1.namespace管理,即fileName与block序列的一个关系映射
2.Block管理,即解决block与dataNode的关系映射问题 3.提供IPC(InterProcess Communication 跨进程通信)服务,解决nameNode与dataNode之间的数据通信,比如 dataNode的Block Report
fileName与block序列的映射关系是保存在fsimage文件中并写入到本地磁盘进行持久化的,block 与dataNode的映射关系是依靠dataNode通过Block Report主动上报方式来获取的,
nameNode大 部分时间都是在被动的接收dataNode/SecondaryNameNode/Client的RPC请求服务。 当editlog达到一定的大小(bytes,由fs.checkpoint.size参数定义)或从上次
保存过后一定时间段 过后(sec,由fs.checkpoint.period参数定义),会触发fsimage文件和editlog文件的合并操作,这个操作由secondaryNameNode负责。
Fsimage是一个二进制文件,其大致结构如下图:

1. 首先是一个image head,其中包含: a) imgVersion(int):当前image的版本信息 b) namespaceID(int):命名空间ID,唯一的 c) numFiles(long):整个文件系统中包含有多少文件和目录 d) genStamp(long):生成该image时的时间戳信息。 2. 接下来便是对每个文件或目录的源数据信息,如果是目录,则包含以下信息: a) path(String):该目录的路径,如”/user/build/buildindex” b) replications(short):副本数(目录虽然没有副本,但这里记录的目录副本数也为3) c) mtime(long):该目录的最后一次修改时间的时间戳信息 d) atime(long):该目录的最后一次访问时间的时间戳信息 e) blocksize(long):目录的blocksize都为0 f) numBlocks(int):实际有多少个block块,目录的该值都为1,表示该item为目录 g) nsQuota(long):namespace Quota值即namespace的配额,若没加Quota限制则为1 h) dsQuota(long):disk Quota值即硬盘配额,若没加限制则也为1 i) username(String):该目录的所属用户名 j) group(String):该目录的所属用户组 k) permission(short):该目录的permission信息即权限信息,如644,755等,有一个short来记录。 3. 若从fsimage中读到的item是一个文件,则还会额外包含如下信息: a) blockid(long):属于该文件的block的blockid, b) numBytes(long):该block的字节大小 c) genStamp(long):该block的时间戳
当该文件对应的numBlocks数不为1,而是大于1时,表示该文件对应有多个block信息,此时紧接在该fsimage之后的就会有多个blockid,numBytes和genStamp信息。根据以上信息我们可以
了解到,fsimage里没有持久化保存block与dataNode的映射关系,block与dataNode的映射关系是依赖dataNode主动上报给nameNode的。当dataNode启动时,dataNode会扫描其本地硬
盘,将保存在当前dataNode上的block信息通过RPC请求主动上报给nameNode,nameNode收到请求数据后会把block与dataNode的映射关系数据保存在内存中。dataNode向nameNode汇报
block信息的过程叫做blockReport。而block与dataNode的映射关系是由nameNode构建的一个blockMap数据结构中,blockMap数据结构如下图:
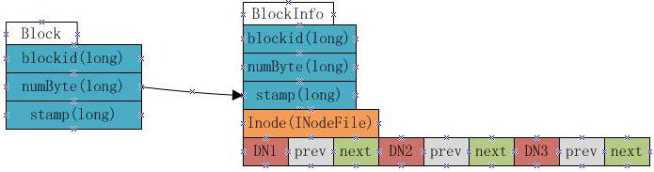
BlockMap其实就是Block与BlockInfo的一个映射表,key就是block对象,value就是BlockInfo,BlockInfo继承自Block。这里的InodeFile即表示这个block属于哪个文件的,
DN1,DN2,DN3即表示这个block在哪几个dataNode上有备份。(DN即dataNode的缩写)。fsimage加载完毕后,BlocksMap中仅缺少每个block对应到其所属的datanodes list的映射
关系信息,而这部分信息就是dataNod启动时主动上报给nameNode的,nameNode收到这部分信息后,就完成了对BlockMap的构建。

这里的prev,next表示的是当前这个block在当前nameNode上的前一个blockInfo和后一个blockInfo信息,即采用链表结构来存储一个dataNode的所有block信息的,而不是简单
的block[]数组,这样做的主要目的是为了节省内存。而且由于需要查询某个dataNode上有哪些block,这个需求一般不大。
block经常会因为各种原因(磁盘坏掉等)出现读写错误,所以nameNode为维护标记block的状态为Corrupt(即损坏的意思),当dataNode发送心跳包过来的时候,
nameCode会返回dataNode一个信号,告诉该dataNode把存在于其dataNode上的损坏的block删除掉。
每个block默认都会有3个副本(即3个备份,分别分部在多个dataNode上),但集群中随时都有可能会有硬盘损坏,datanode下线等问题,这时block的副本数会下降,为了提高
block的期望副本数(通常为3),dataNode会对该block进行拷贝,不一定是拷贝到当前dataNode上,也有可能会拷贝到其他dataNode上。
以上是关于04 namenode和datanode的主要内容,如果未能解决你的问题,请参考以下文章
hadoop源代码解读namenode高可靠:HA;web方式查看namenode下信息;dfs/data决定datanode存储位置