分布式流处理是对无边界数据集进行连续不断的处理、聚合和分析的过程,与MapReduce一样是一种通用计算框架,期望延迟在毫秒或者秒级别。这类系统一般采用有向无环图(DAG)。DAG是任务链的图形化表示,用它来描述流处理作业的拓扑。在选择不同的流处理系统时,通常会关注以下几点:
- 运行时和编程模型:平台框架提供的编程模型决定了许多特色功能,编程模型要足够处理各种应用场景。
- 函数式原语:流处理平台应该能提供丰富的功能函数,比如,map或者filter这类易扩展、处理单条信息的函数;处理多条信息的函数aggregation;跨数据流、不易扩展的操作join等。
- 状态管理:大部分应用都需要保持状态处理的逻辑。流处理平台应该提供存储、访问和更新状态信息。
- 消息传输保障:消息传输保障一般有三种:at most once,at least once和exactly once。
- At most once:消息传输机制是每条消息传输零次或者一次,即消息可能会丢失;
- A t least once:意味着每条消息会进行多次传输尝试,至少一次成功,即消息传输可能重复但不会丢失;
- Exactly once:消息传输机制是每条消息有且只有一次,即消息传输既不会丢失也不会重复。
- 容错:流处理框架中的失败会发生在各个层次,比如,网络部分,磁盘崩溃或者节点宕机等。流处理框架应该具备从所有这种失败中恢复,并从上一个成功的状态(无脏数据)重新消费。
- 性能:延迟时间(Latency),吞吐量(Throughput)和扩展性(Scalability)是流处理应用中极其重要的指标。
- 平台的成熟度和接受度:成熟的流处理框架可以提供潜在的支持,可用的库,甚至开发问答帮助。选择正确的平台会在这方面提供很大的帮助。
运行时和编程模型
运行时和编程模型是一个系统最重要的特质,因为它们定义了表达方式、可能的操作和将来的局限性。因此,运行时和编程模型决定了系统的能力和适用场景。实现流处理系统有两种完全不同的方式:
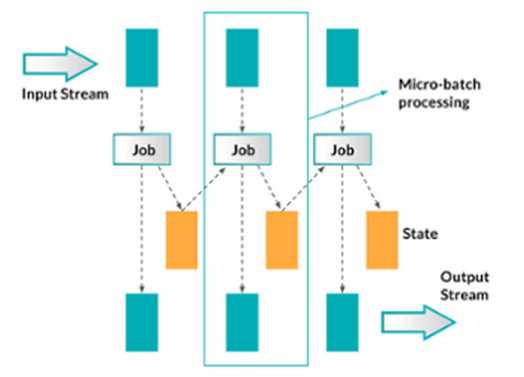
- 原生流处理:指所有输入的记录一旦到达即会一个接着一个进行处理。示例如下:
- 微批处理:把输入的数据按照某种预先定义的时间间隔(典型的是几秒钟)分成短小的批量数据,流经流处理系统。示例如下:
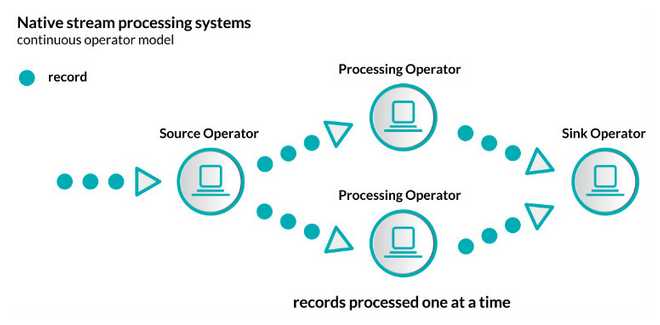
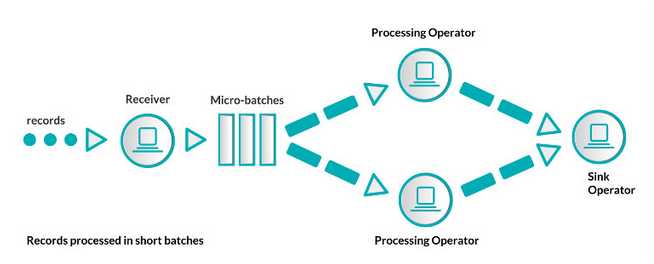
两种方法都有其先天的优势和不足,原生流处理的优势在于它的表达方式。数据一旦到达立即处理,这些系统的延迟性远比其它微批处理要好。除了延迟性外,原生流处理的状态操作也容易实现。一般原生流处理系统为了达到低延迟和容错性会花费比较大的成本,因为它需要考虑每条记录。原生流处理的负载均衡也是个问题。比如,我们处理的数据按key分区,如果分区的某个key是资源密集型,那这个分区很容易成为作业的瓶颈。
微批处理。将流式计算分解成一系列短小的批处理作业,也不可避免的减弱系统的表达力。像状态管理或者join等操作的实现会变的困难,因为微批处理系统必须操作整个批量数据。并且,batch interval会连接两个不易连接的事情:基础属性和业务逻辑。相反地,微批处理系统的容错性和负载均衡实现起来非常简单,因为微批处理系统仅发送每批数据到一个worker节点上,如果一些数据出错那就使用其它副本。微批处理系统很容易建立在原生流处理系统之上。
编程模型一般分为组合式和声明式。组合式编程提供基本的构建模块,它们必须紧密结合来创建拓扑。新的组件经常以接口的方式完成。相对应地,声明式API操作是定义的高阶函数。它允许我们用抽象类型和方法来写函数代码,并且系统创建拓扑和优化拓扑。声明式API经常也提供更多高级的操作(比如,窗口函数或者状态管理)。
主流开源流处理系统
主源开源的流处理系统如下图,暂时不介绍商业的系统,比如Google MillWheel或者Amazon Kinesis,也不会涉及很少使用的Intel GearPump或者Apache Apex
Apache Storm最开始是由Nathan Marz和他的团队于2010年在数据分析公司BackType开发的,后来BackType公司被Twitter收购,接着Twitter开源Storm并在2014年成为Apache顶级项目。毋庸置疑,Storm成为大规模流数据处理的先锋,并逐渐成为工业标准。Storm是原生的流处理系统,提供low-level的API。Storm使用Thrift来定义topology和支持多语言协议,使得我们可以使用大部分编程语言开发,Scala自然包括在内
Trident是对Storm的一个更高层次的抽象,Trident最大的特点以batch的形式进行流处理。Trident简化topology构建过程,增加了窗口操作、聚合操作或者状态管理等高级操作,这些在Storm中并不支持。相对应于Storm的At most once流传输机制,Trident提供了Exactly once传输机制。Trident支持Java,Clojure和Scala
当前Spark是非常受欢迎的批处理框架,包含Spark SQL,MLlib和Spark Streaming。Spark的运行时是建立在批处理之上,因此后续加入的Spark Streaming也依赖于批处理,实现了微批处理。接收器把输入数据流分成短小批处理,并以类似Spark作业的方式处理微批处理。Spark Streaming提供高级声明式API(支持Scala,Java和Python)
Samza最开始是专为LinkedIn公司开发的流处理解决方案,并和LinkedIn的Kafka一起贡献给社区,现已成为基础设施的关键部分。Samza的构建严重依赖于基于log的Kafka,两者紧密耦合。Samza提供组合式API,当然也支持Scala
Flink是个相当早的项目,开始于2008年,但只在最近才得到注意。Flink是原生的流处理系统,提供high level的API。Flink也提供API来像Spark一样进行批处理,但两者处理的基础是完全不同的。Flink把批处理当作流处理中的一种特殊情况。在Flink中,所有的数据都看作流,是一种很好的抽象,因为这更接近于现实世界
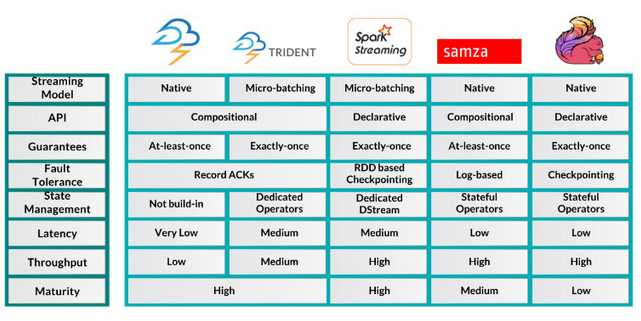
快速的介绍流处理系统之后,让我们以下面的表格来更好清晰的展示它们之间的不同:
容错性
流处理系统的容错性与生俱来的比批处理系统难实现。当批处理系统中出现错误时,我们只需要把失败的部分简单重启即可;但对于流处理系统,出现错误就很难恢复。因为线上许多作业都是7 x 24小时运行,不断有输入的数据。流处理系统面临的另外一个挑战是状态一致性,因为重启后会出现重复数据,并且不是所有的状态操作是幂等的。
以是流处理框架容错性处理方案:
Apache Storm:Storm使用上游数据备份和消息确认的机制来保障消息在失败之后会重新处理。消息确认原理:每个操作都会把前一次的操作处理消息的确认信息返回。Topology的数据源备份它生成的所有数据记录。当所有数据记录的处理确认信息收到,备份即会被安全拆除。失败后,如果不是所有的消息处理确认信息收到,那数据记录会被数据源数据替换。这保障了没有数据丢失,但数据结果会有重复,这就是at-least once传输机制。
Storm采用取巧的办法完成了容错性,对每个源数据记录仅仅要求几个字节存储空间来跟踪确认消息。纯数据记录消息确认架构,尽管性能不错,但不能保证exactly once消息传输机制,所有应用开发者需要处理重复数据。Storm存在低吞吐量和流控问题,因为消息确认机制在反压下经常误认为失败。
Spark Streaming:Spark Streaming实现微批处理,容错机制的实现跟Storm不一样的方法。微批处理的想法相当简单。Spark在集群各worker节点上处理micro-batches。每个micro-batches一旦失败,重新计算就行。因为micro-batches本身的不可变性,并且每个micro-batches也会持久化,所以exactly once传输机制很容易实现。
Samza:Samza的实现方法跟前面两种流处理框架完全不一样。Samza利用消息系统Kafka的持久化和偏移量。Samza监控任务的偏移量,当任务处理完消息,相应的偏移量被移除。消息的偏移量会被checkpoint到持久化存储中,并在失败时恢复。但是问题在于:从上次checkpoint中修复偏移量时并不知道上游消息已经被处理过,这就会造成重复。这就是at least once传输机制。
Apache Flink:Flink的容错机制是基于分布式快照实现的,这些快照会保存流处理作业的状态(本文对Flink的检查点和快照不进行区分,因为两者实际是同一个事物的两种不同叫法。Flink构建这些快照的机制可以被描述成分布式数据流的轻量级异步快照,它采用Chandy-Lamport算法实现。)。如果发生失败的情况,系统可以从这些检查点进行恢复。Flink发送checkpoint的栅栏(barrier)到数据流中(栅栏是Flink的分布式快照机制中一个核心的元素),当checkpoint的栅栏到达其中一个operator,operator会接所有收输入流中对应的栅栏(比如,图中checkpoint n对应栅栏n到n-1的所有输入流,其仅仅是整个输入流的一部分)。所以相对于Storm,Flink的容错机制更高效,因为Flink的操作是对小批量数据而不是每条数据记录。但也不要让自己糊涂了,Flink仍然是原生流处理框架,它与Spark Streaming在概念上就完全不同。Flink也提供exactly once消息传输机制。
状态管理
状态管理大部分大型流处理应用都涉及到状态。相对于无状态的操作(其只有一个输入数据,处理过程和输出结果),有状态的应用会有一个输入数据和一个状态信息,然后处理过程,接着输出结果和修改状态信息。因此,我们不得不管理状态信息,并持久化。我们期望一旦因某种原因失败,状态能够修复。状态修复有可能会出现小问题,它并不总是保证exactly once,有时也会出现消费多次,但这并不是我们想要的。
据我们所知,Storm提供at-least once的消息传输保障。那我们又该如何使用Trident做到exactly once的语义。概念上貌似挺简单,你只需要提交每条数据记录,但这显然不是那么高效。所以你会想到小批量的数据记录一起提交会优化。Trident定义了几个抽象来达到exactly once的语义,见下图,其中也会有些局限。
Spark Streaming是微批处理系统,它把状态信息也看做是一种微批量数据流。在处理每个微批量数据时,Spark加载当前的状态信息,接着通过函数操作获得处理后的微批量数据结果并修改加载过的状态信息。
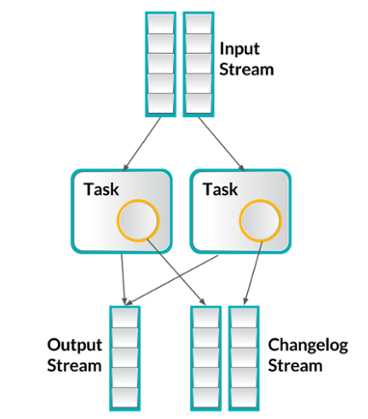
Samza实现状态管理是通过Kafka来处理的。Samza有真实的状态操作,所以其任务会持有一个状态信息,并把状态改变的日志推送到Kafka。如果需要状态重建,可以很容易的从Kafka的topic重建。为了达到更快的状态管理,Samza也支持把状态信息放入本地key-value存储中,所以状态信息不必一直在Kafka中管理,见下图。不幸的是,Samza只提供at-least once语义,exactly once的支持也在计划中
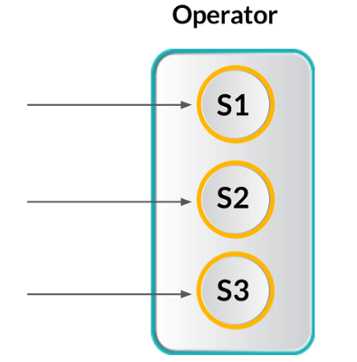
Flink提供状态操作,和Samza类似。Flink提供两种类型的状态:一种是用户自定义状态;另外一种是窗口状态。如图,第一个状态是自定义状态,它和其它的的状态不相互作用。这些状态可以分区或者使用嵌入式Key-Value存储状态[文档一和二]。当然Flink提供exactly-once语义。下图展示Flink长期运行的三个状态。
小结
对于延迟性来说,微批处理一般在秒级别,大部分原生流处理在百毫秒以下,调优的情况下Storm可以很轻松的达到十毫秒。同时也要记住,消息传输机制保障,容错性和状态恢复都会占用机器资源。例如,打开容错恢复可能会降低10%到15%的性能,Storm可能降低70%的吞吐量。
总之,天下没有免费的午餐。对于有状态管理,Flink会降低25%的性能,Spark Streaming降低50%的性能。也要记住,各大流处理框架的所有操作都是分布式的,通过网络发送数据是相当耗时的,所以尽量利用数据本地性,也尽量优化你的应用的序列化。
项目成熟度:Storm是第一个主流的流处理框架,后期已经成为长期的工业级的标准,并在像Twitter,Yahoo,Spotify等大公司使用。Spark Streaming是最近最流行的Scala代码实现的流处理框架。现在Spark Streaming被公司(Netflix, Cisco, DataStax, Intel, IBM等)日渐接受。Samza主要在LinkedIn公司使用。Flink是一个新兴的项目,很有前景。你可能对项目的贡献者数量也感兴趣。Storm和Trident大概有180个代码贡献者;整个Spark有720多个;根据github显示,Samza有40个;Flink有超过130个代码贡献者。
High level API:具有high level API的流处理框架会更简洁和高效;
Storm:Storm非常适合任务量小但速度要求高的应用。如果你主要在意流处理框架的延迟性,Storm将可能是你的首先。但同时也要记住,Storm的容错恢复或者Trident的状态管理都会降低整体的性能水平。也有一个潜在的Storm更新项目-Twitter的Heron,Heron设计的初衷是为了替代Storm,并在每个单任务上做了优化但同时保留了API。
Spark Streaming:如果你得基础架构中已经设计到Spark,那Spark Streaming无疑是值得你尝试的。因为你可以很好的利用Spark各种library。如果你需要使用Lambda架构,Spark Streaming也是一个不错的选择。但你要时刻记住微批处理的局限性,以及它的延迟性问题。
Samza:如果你想使用Samza,那Kafka应该是你基础架构中的基石,好在现在Kafka已经成为家喻户晓的组件。像前面提到的,Samza一般会搭配强大的本地存储一起,这对管理大数据量的状态非常有益。它可以轻松处理上万千兆字节的状态信息,但要记住Samza只支持at least once语义。
Flink:Flink流处理系统的概念非常不错,并且满足绝大多数流处理场景,也经常提供前沿的功能函数,比如,高级窗口函数或者时间处理功能,这些在其它流处理框架中是没有的。同时Flink也有API提供给通用的批处理场景。但你需要足够的勇气去上线一个新兴的项目,并且你也不能忘了看下Flink的roadmap。