从网页中通过正则表达式获取标题等信息实现过程分析
Posted siweihz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从网页中通过正则表达式获取标题等信息实现过程分析相关的知识,希望对你有一定的参考价值。
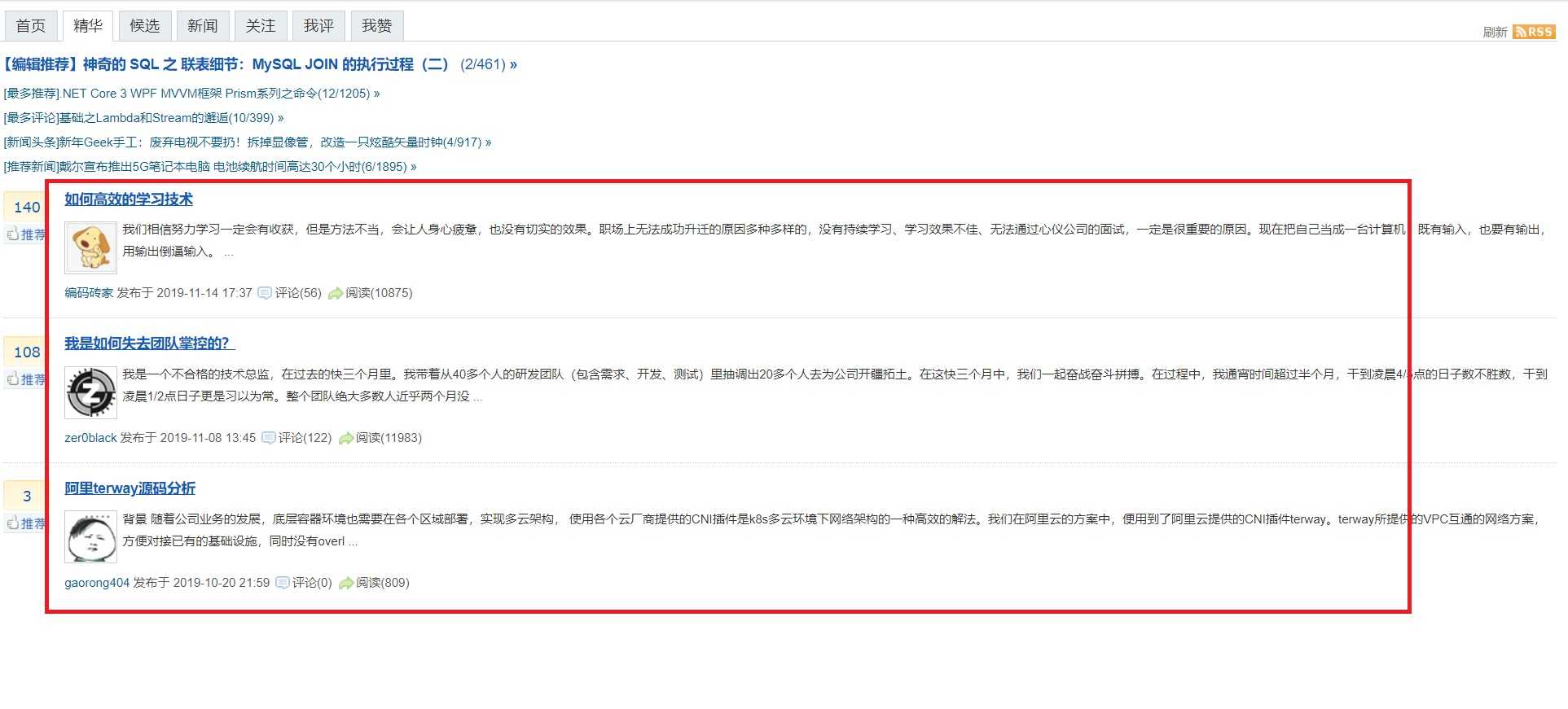
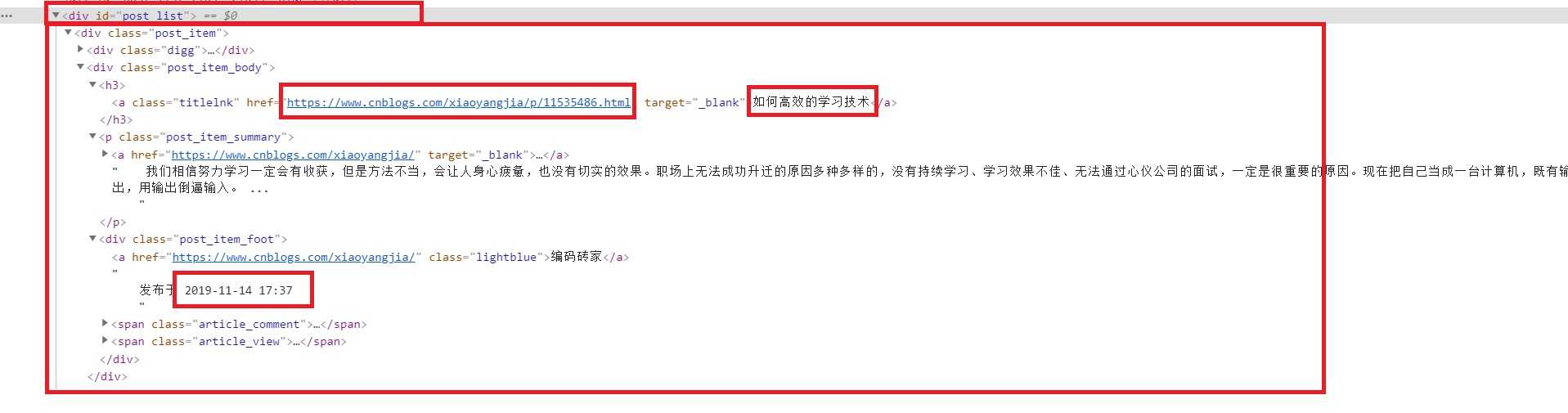
然后“查看元素”,整个列表页面是通过div支撑起来的,每一条也是一个div;
其中标题和链接是在<div class="post_item">下的<a class="titlelnk"中;
发表时间,是在<a href=和<span class="article_comment">之间。
(2)内容提取
知道了结构,下一步就是如何提取内容了。
- 提取整个列表部分
该部分相对比较简单,找到列表部分的起始、结束部分就可以了。
如博客园精华部分的起始是:<div id="post_list">,结束是:</div>。
一般情况下,开始位置比较容易确定,但结束位置这么些用正则表达式在结束标签是div的时候是无法获取内容的。这种情况下要找到结束标签的下一个标签,
比如:
<script>editorPickStat(); aggSite.user.getUserInfo();</script>
1 // 获得网址所在的匹配区域部分 2 3 private static String getContentArea(String urlContent, String strAreaBegin,String strAreaEnd) { 4 5 ? int pos1 = 0, pos2 = 0; 6 ? pos1 = urlContent.indexOf(strAreaBegin) + strAreaBegin.length(); 7 ? pos2 = urlContent.indexOf(strAreaEnd, pos1); 8 ? return urlContent.substring(pos1, pos2); 9 }
然后通过正则表达式获取一个列表:
1 Pattern pt = Pattern.compile(rb.getRegex()); 2 ?Matcher mt = pt.matcher(contentArea); 3 4 while (mt.find()) {
-
提取单条记录
方法同提取内容部分差不多,如单条记录的起始标签为<div class="post_item">,结束标签相对来说也比较难确定。
获取单条记录,并去除空格之类的无用字符:
1 String rowContent = mt.group(); 2 3 rowContent = rowContent.replaceAll(rb.getRemoveRegex(), "");
-
提取出标题
取出标题用的是 >.?</a>或者title=.?>,并且要去除空格和多余的字符,需要用到类似:<li>|</li>|(<img)([sS]?)(>)|(<div)([sS]?)(>)|</div>或者(<table)([sS]?)(>)|<tr>|(<td)([sS]?)(>)|</td>|</tr>|(<table)([sS]*?)(>)之类的。
1 // 获取标题 2 3 Matcher title = Pattern.compile(rb.getTitleRegex()).matcher(rowContent); 6 7 while (title.find()) { 8 9 String s = title.group().replaceAll("||>|</a>|[.*?]|</l>",""); 10 11 if(s ==null || s.trim().length()<=0){ 13 s = "error"; 15 } 17 tuBean.setTitle(s); 18 19 }
-
提取出超链接
提取出超链接,需要用到 href=.?target=或者href=.?.> 或者 href=.*?title。要根据实际情况配置。
 View Code
View Code1 // 获取网址 2 3 Matcher myurl = Pattern.compile(rb.getUrlRegex()).matcher( 4 5 rowContent); 6 7 while (myurl.find()) { 8 9 String u = myurl.group().replaceAll( 10 11 "href=|"|>|target=|_blank|title", ""); 12 13 u = u.replaceAll("‘|\\", ""); 14 15 if(u!=null && (u.indexOf("http://")==-1)){ 16 17 tuBean.setUrl(rb.getPrefix() + u); 18 19 }else{ 20 21 tuBean.setUrl(u); 22 23 } 24 25 } 26 27 if(tuBean.getUrl() ==null){ 28 29 tuBean.setUrl("error"); 30 31 }
-
提取出发表时间

不同的时间格式,获取方法是不一样的。这个也是用正则表达式获取:比较常规的
[0-9]{4}-[0-9]{1,2}-[0-9]{1,2}
或者:
[0-9]{4}-[0-9]{2}-[0-9]{1,2}
1 // 获取时间 3 Matcher d = Pattern.compile(rb.getDateRegex()).matcher(rowContent); 5 while (d.find()) { 6 7 tuBean.setDeliveryDate(d.group()); 8 9 }