序列标注 总结
Posted shona
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了序列标注 总结相关的知识,希望对你有一定的参考价值。
序列标注一般可以分为两类:
1、原始标注(Raw labeling):每个元素都需要被标注为一个标签。
2、联合标注(Joint segmentation and labeling):所有的分段被标注为同样的标签。
命名实体识别(Named entity recognition, NER)是信息提取问题的一个子任务,需要将元素进行定位和分类,如人名、组织名、地点、时间、质量等。
举个NER和联合标注的例子。一个句子为:Yesterday , George Bush gave a speech. 其中包括一个命名实体:George Bush。我们希望将标签“人名”标注到整个短语“George Bush”中,而不是将两个词分别标注。这就是联合标注。
BIO标注
解决联合标注问题的最简单的方法,就是将其转化为原始标注问题。标准做法就是使用BIO标注。
BIO标注:将每个元素标注为“B-X”、“I-X”或者“O”。其中,“B-X”表示此元素所在的片段属于X类型并且此元素在此片段的开头,“I-X”表示此元素所在的片段属于X类型并且此元素在此片段的中间位置,“O”表示不属于任何类型。
比如,我们将 X 表示为名词短语(Noun Phrase, NP),则BIO的三个标记为:
(1)B-NP:名词短语的开头
(2)I-NP:名词短语的中间
(3)O:不是名词短语
因此可以将一段话划分为如下结果;
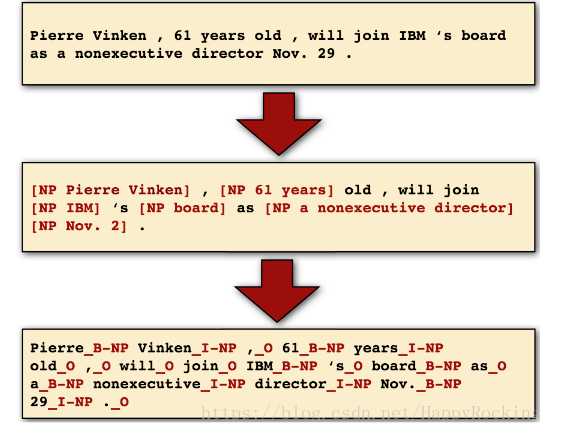
我们可以进一步将BIO应用到NER中,来定义所有的命名实体(人名、组织名、地点、时间等),那么我们会有许多 B 和 I 的类别,如 B-PERS、I-PERS、B-ORG、I-ORG等。然后可以得到以下结果:

以上是关于序列标注 总结的主要内容,如果未能解决你的问题,请参考以下文章