Python八种数据导入方法,你掌握了吗?赶紧收藏
Posted 程序媛饺子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python八种数据导入方法,你掌握了吗?赶紧收藏相关的知识,希望对你有一定的参考价值。
数据分析过程中,需要对获取到的数据进行分析,往往第一步就是导入数据。导入数据有很多方式,不同的数据文件需要用到不同的导入方式,相同的文件也会有几种不同的导入方式。下面总结几种常用的文件导入方法。
大多数情况下,会使用NumPy或Pandas来导入数据,因此在开始之前,先执行:
import numpy as np
import pandas as pd
两种获取help的方法
很多时候对一些函数方法不是很了解,此时Python提供了一些帮助信息,以快速使用Python对象。
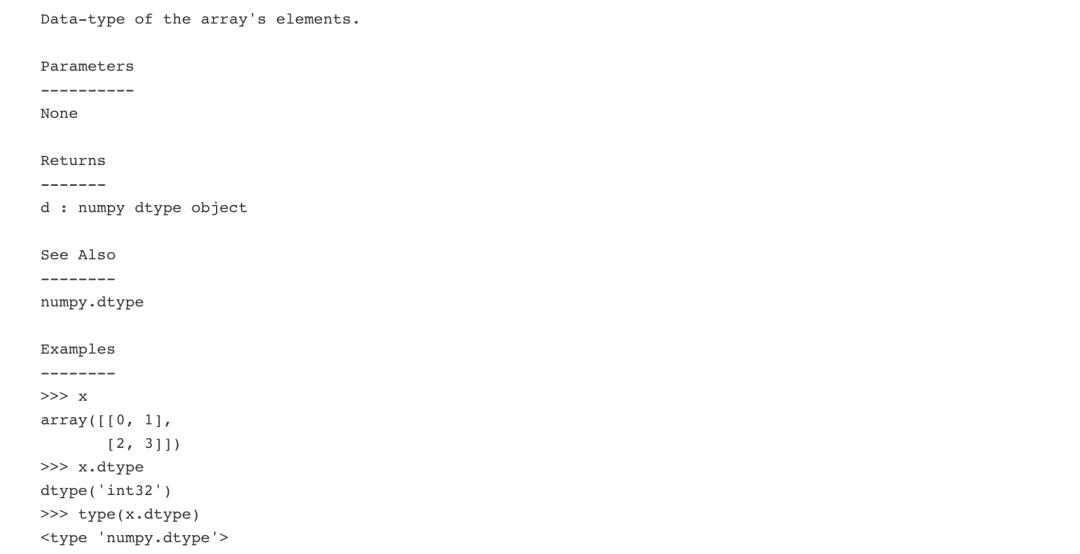
使用Numpy中的info方法。
np.info(np.ndarray.dtype)
Python内置函数
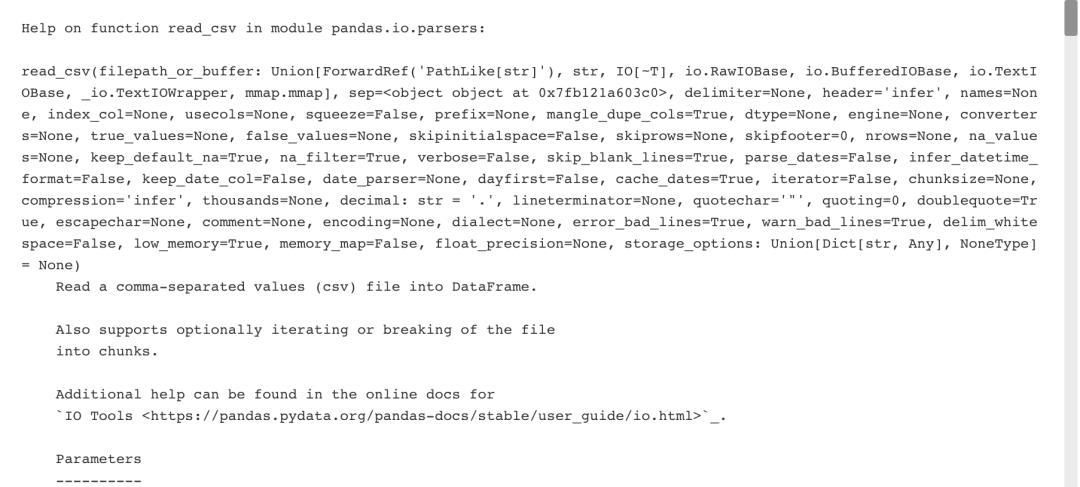
help(pd.read_csv)
一、文本文件
1、纯文本文件
filename = 'demo.txt'
file = open(filename, mode='r') # 打开文件进行读取
text = file.read() # 读取文件的内容
print(file.closed) # 检查文件是否关闭
file.close() # 关闭文件
print(text)
使用上下文管理器 – with
with open('demo.txt', 'r') as file:
print(file.readline()) # 一行一行读取
print(file.readline())
print(file.readline())
2、表格数据:Flat文件
使用 Numpy 读取 Flat 文件
Numpy 内置函数处理数据的速度是 C 语言级别的。
Flat 文件是一种包含没有相对关系结构的记录的文件。(支持Excel、CSV和Tab分割符文件 )
- 具有一种数据类型的文件
用于分隔值的字符串跳过前两行。在第一列和第三列读取结果数组的类型。
filename = 'mnist.txt'
data = np.loadtxt(filename,
delimiter=',',
skiprows=2,
usecols=[0,2],
dtype=str)
- 具有混合数据类型的文件
两个硬的要求:
跳过表头信息
区分横纵坐标
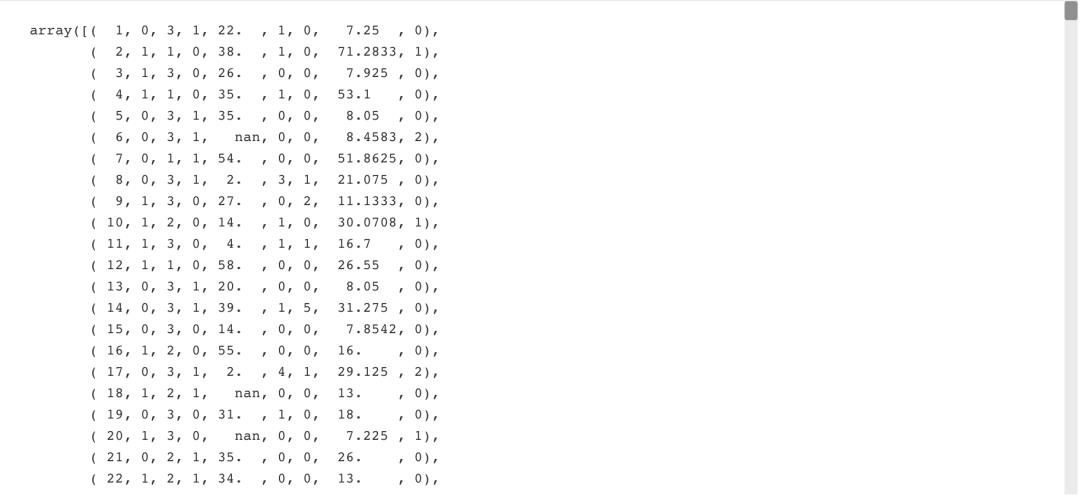
filename = 'titanic.csv'
data = np.genfromtxt(filename,
delimiter=',',
names=True,
dtype=None)
使用 Pandas 读取Flat文件
filename = 'demo.csv'
data = pd.read_csv(filename,
nrows=5, # 要读取的文件的行数
header=None, # 作为列名的行号
sep='\\t', # 分隔符使用
comment='#', # 分隔注释的字符
na_values=[""]) # 可以识别为NA/NaN的字符串
二、Excel 电子表格
Pandas中的ExcelFile()是pandas中对excel表格文件进行读取相关操作非常方便快捷的类,尤其是在对含有多个sheet的excel文件进行操控时非常方便。
file = 'demo.xlsx'
data = pd.ExcelFile(file)
df_sheet2 = data.parse(sheet_name='1960-1966',
skiprows=[0],
names=['Country',
'AAM: War(2002)'])
df_sheet1 = pd.read_excel(data,
sheet_name=0,
parse_cols=[0],
skiprows=[0],
names=['Country'])
使用sheet_names属性获取要读取工作表的名称。
data.sheet_names
三、SAS 文件
SAS (Statistical Analysis System)是一个模块化、集成化的大型应用软件系统。其保存的文件即sas是统计分析文件。
from sas7bdat import SAS7BDAT
with SAS7BDAT('demo.sas7bdat') as file:
df_sas = file.to_data_frame()
四、Stata 文件
Stata 是一套提供其使用者数据分析、数据管理以及绘制专业图表的完整及整合性统计软件。其保存的文件后缀名为.dta的Stata文件。
data = pd.read_stata('demo.dta')
五、Pickled 文件
python中几乎所有的数据类型(列表,字典,集合,类等)都可以用pickle来序列化。python的pickle模块实现了基本的数据序列和反序列化。通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储;通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
import pickle
with open('pickled_demo.pkl', 'rb') as file:
pickled_data = pickle.load(file) # 下载被打开被读取到的数据
与其相对应的操作是写入方法pickle.dump() 。
六、HDF5 文件
HDF5文件是一种常见的跨平台数据储存文件,可以存储不同类型的图像和数码数据,并且可以在不同类型的机器上传输,同时还有统一处理这种文件格式的函数库。
HDF5 文件一般以 .h5 或者 .hdf5 作为后缀名,需要专门的软件才能打开预览文件的内容。
import h5py
filename = 'H-H1_LOSC_4_v1-815411200-4096.hdf5'
data = h5py.File(filename, 'r')
七、Matlab 文件
其由matlab将其工作区间里的数据存储的后缀为.mat的文件。
import scipy.io
filename = 'workspace.mat'
mat = scipy.io.loadmat(filename)
八、关系型数据库
from sqlalchemy import create_engine
engine = create_engine('sqlite://Northwind.sqlite')
使用table_names()方法获取一个表名列表
table_names = engine.table_names()
1、直接查询关系型数据库
con = engine.connect()
rs = con.execute("SELECT * FROM Orders")
df = pd.DataFrame(rs.fetchall())
df.columns = rs.keys()
con.close()
使用上下文管理器 – with
with engine.connect() as con:
rs = con.execute("SELECT OrderID FROM Orders")
df = pd.DataFrame(rs.fetchmany(size=5))
df.columns = rs.keys()
2、使用Pandas查询关系型数据库
df = pd.read_sql_query("SELECT * FROM Orders", engine)
数据探索
数据导入后会对数据进行初步探索,如查看数据类型,数据大小、长度等一些基本信息。这里简单总结一些。
1、NumPy Arrays
data_array.dtype # 数组元素的数据类型
data_array.shape # 阵列尺寸
len(data_array) # 数组的长度
2、Pandas DataFrames
df.head() # 返回DataFrames前几行(默认5行)
df.tail() # 返回DataFrames最后几行(默认5行)
df.index # 返回DataFrames索引
df.columns # 返回DataFrames列名
df.info() # 返回DataFrames基本信息
data_array = data.values # 将DataFrames转换为NumPy数组
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
Python入门基础教程
第1章 快速上手:基础知识
1.1 交互式解释器
1.2 算法是什么
1.3 数和表达式
1.4 变量
1.5 语句
1.6 获取用户输入
1.7 函数
1.8 模块
1.9 保存并执行程序
1.10 字符串
第2章 列表和元组
2.1 序列概述
2.2 通用的序列操作
2.3 列表:Python的主力
2.4 元组:不可修改的序列
第3章 使用字符串
3.1 字符串基本操作
3.2 设置字符串的格式:精简版
3.3 设置字符串的格式:完整版
3.4 字符串方法
3.5 小结

第4章 当索引行不通时
4.1 字典的用途
4.2 创建和使用字典
第5章 条件、循环及其他语句
5.1 再谈print和import
5.2 赋值魔法
5.3 代码块:缩进的乐趣
5.4 条件和条件语句
5.5 循环
…
第6章 抽象
6.2 抽象和结构
6.3 自定义函数
6.4 参数魔法
6.5 作用域…
第7章 再谈抽象
7.1 对象魔法
7.2 类
7.3 关于面向对象设计的一些思考
第8章 异常
8.1 异常是什么
8.2 让事情沿你指定的轨道出错
8.3 捕获异常
8.4 异常和函数
…
第9章 魔法方法、特性和迭代器
9.1 如果你使用的不是Python 3
9.2 构造函数
9.3 元素访问
…
第10章 开箱即用
10.1 模块
10.2 探索模块
10.3 标准库:一些深受欢迎的模块
…
第11章 文件
11.1 打开文件
11.2 文件的基本方法
11.3 迭代文件内容
第12章 图形用户界面
12.1 创建GUI示例应用程序
12.2 使用其他GUI工具包
…
第13章 数据库支持
13.1 Python数据库API
13.2 SQLite和PySQLite
…

第14章 网络编程
14.2 SocketServer及相关的类
14.3 多个连接
…
第15章 Python和Web
15.1 屏幕抓取
15.2 使用CGI创建动态网页
15.3 使用Web框架
…
第16章 测试基础
16.1 先测试再编码
16.2 测试工具
16.3 超越单元测试
…
第17章 扩展Python
17.1 鱼和熊掌兼得
17.2 简单易行的方式:Jython和IronPython
…

第18章 程序打包
第19章 趣味编程
第20章 项目1:自动添加标签
第21章 项目2:绘制图表
第22章 项目3:万能的XML
第23章 项目4:新闻汇总
第24章 项目5:虚拟茶话会
第25章 项目6:使用CGI进行远程编辑
第26章 项目7:自建公告板
第27章 项目8:使用XML-RPC共享文件
第28章 项目9:使用GUI共享文件
第29章 项目10:自制街机游戏

朋友们如果需要这份完整版的Python学习资料,微信扫描下方CSDN官方认证二维码【免费获取】。

总结
坚持到了这儿,恭喜你,表示你有做开发的潜力,其实我想说的上面的内容还是刚刚开始,刚开始大家不需要多么精通了解这些内容,除了Python方面的知识,每个部分掌握一点儿能进行基本开发就好,主要是不断练习,让自己跳出「舒适区」,进入「学习区」,但是又不进入「恐慌区」,不断给自己「喂招」。
以上是关于Python八种数据导入方法,你掌握了吗?赶紧收藏的主要内容,如果未能解决你的问题,请参考以下文章