爬虫练手项目:获取豆瓣评分最高的电影并下载
Posted bigbears
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫练手项目:获取豆瓣评分最高的电影并下载相关的知识,希望对你有一定的参考价值。
前期回顾
上篇博文我们学习了Python爬虫的四大库urllib ,requests ,BeautifulSoup以及selenium
爬虫常用库介绍
- 学习了
urllib与request的常见用法 - 学习了使用
BeautifulSoup来解析网页以及使用selenium来驱动浏览器
# 我们导入了 web 驱动模块
from selenium import webdriver
# 接着我们创建了一个 Chrome 驱动
driver = webdriver.Chrome()
# 接着使用 get 方法打开百度
driver.get("https://www.baidu.com")
# 获取输入框并且往里面写入我们要搜索的内容
input = driver.find_element_by_css_selector('#kw')
input.send_keys("波多野结衣照片")
# 我们就获取到搜索这个按钮然后点击
button = driver.find_element_by_css_selector('#su')
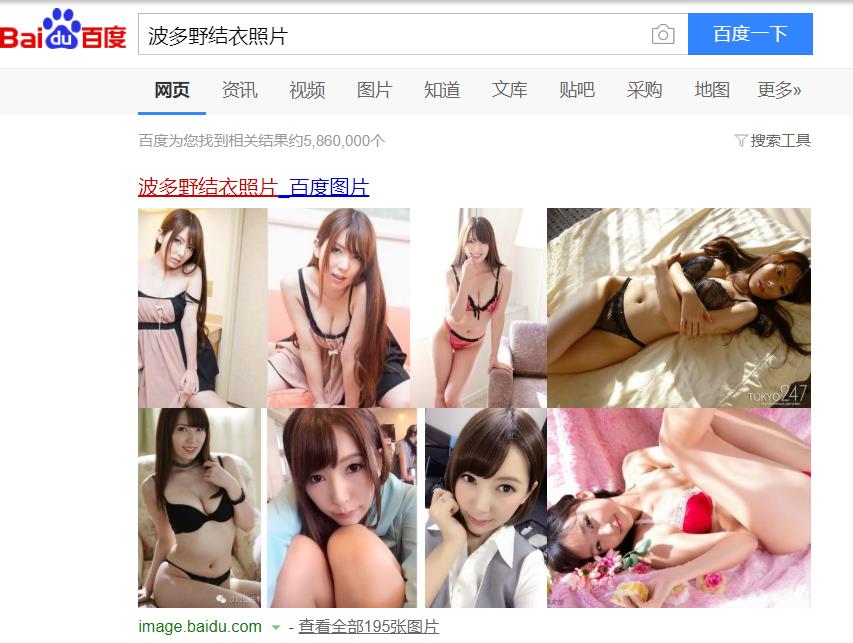
button.click()则是上次查看波多老师图片的代码,效果如下

抓取豆瓣电影并保存本地
我们来抓取一下豆瓣上排名前250的电影
import requests
from bs4 import BeautifulSoup
import xlwt
def request_douban(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
except requests.RequestException:
return None
book = xlwt.Workbook(encoding='utf-8', style_compression=0)
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True)
sheet.write(0, 0, '名称')
sheet.write(0, 1, '图片')
sheet.write(0, 2, '排名')
sheet.write(0, 3, '评分')
sheet.write(0, 4, '作者')
sheet.write(0, 5, '简介')
n = 1
def save_to_excel(soup):
list = soup.find(class_='grid_view').find_all('li')
for item in list:
item_name = item.find(class_='title').string
item_img = item.find('a').find('img').get('src')
item_index = item.find(class_='').string
item_score = item.find(class_='rating_num').string
item_author = item.find('p').text
if (item.find(class_='inq') != None):
item_intr = item.find(class_='inq').string
# print('爬取电影:' + item_index + ' | ' + item_name +' | ' + item_img +' | ' + item_score +' | ' + item_author +' | ' + item_intr )
print('爬取电影:' + item_index + ' | ' + item_name + ' | ' + item_score + ' | ' + item_intr)
global n
sheet.write(n, 0, item_name)
sheet.write(n, 1, item_img)
sheet.write(n, 2, item_index)
sheet.write(n, 3, item_score)
sheet.write(n, 4, item_author)
sheet.write(n, 5, item_intr)
n = n + 1
def main(page):
url = 'https://movie.douban.com/top250?start=' + str(page * 25) + '&filter='
html = request_douban(url)
soup = BeautifulSoup(html, 'lxml')
save_to_excel(soup)
if __name__ == '__main__':
for i in range(0, 10):
main(i)
book.save(u'豆瓣最受欢迎的250部电影.csv')代码分析
首先导入相关库
import requests
# 请求网页库
from bs4 import BeautifulSoup
# 解析网页库
import xlwt
# 与Excel文件交互定义一个请求网页的函数
def request_douban(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
except requests.RequestException:
return None创建一个存储数据的Excel
book = xlwt.Workbook(encoding='utf-8', style_compression=0)
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True)
sheet.write(0, 0, '名称')
sheet.write(0, 1, '图片')
sheet.write(0, 2, '排名')
sheet.write(0, 3, '评分')
sheet.write(0, 4, '作者')
sheet.write(0, 5, '简介')
n = 1定义一个将BeautifulSoup到的数据存入Excel的函数
def save_to_excel(soup):
list = soup.find(class_='grid_view').find_all('li')
for item in list:
item_name = item.find(class_='title').string
item_img = item.find('a').find('img').get('src')
item_index = item.find(class_='').string
item_score = item.find(class_='rating_num').string
item_author = item.find('p').text
if (item.find(class_='inq') != None):
item_intr = item.find(class_='inq').string
# print('爬取电影:' + item_index + ' | ' + item_name +' | ' + item_img +' | ' + item_score +' | ' + item_author +' | ' + item_intr )
print('爬取电影:' + item_index + ' | ' + item_name + ' | ' + item_score + ' | ' + item_intr)
global n
sheet.write(n, 0, item_name)
sheet.write(n, 1, item_img)
sheet.write(n, 2, item_index)
sheet.write(n, 3, item_score)
sheet.write(n, 4, item_author)
sheet.write(n, 5, item_intr)
n = n + 1定义主函数传入URL并且存储,调用主函数
def main(page):
url = 'https://movie.douban.com/top250?start=' + str(page * 25) + '&filter='
html = request_douban(url)
soup = BeautifulSoup(html, 'lxml')
save_to_excel(soup)
if __name__ == '__main__':
for i in range(0, 10):
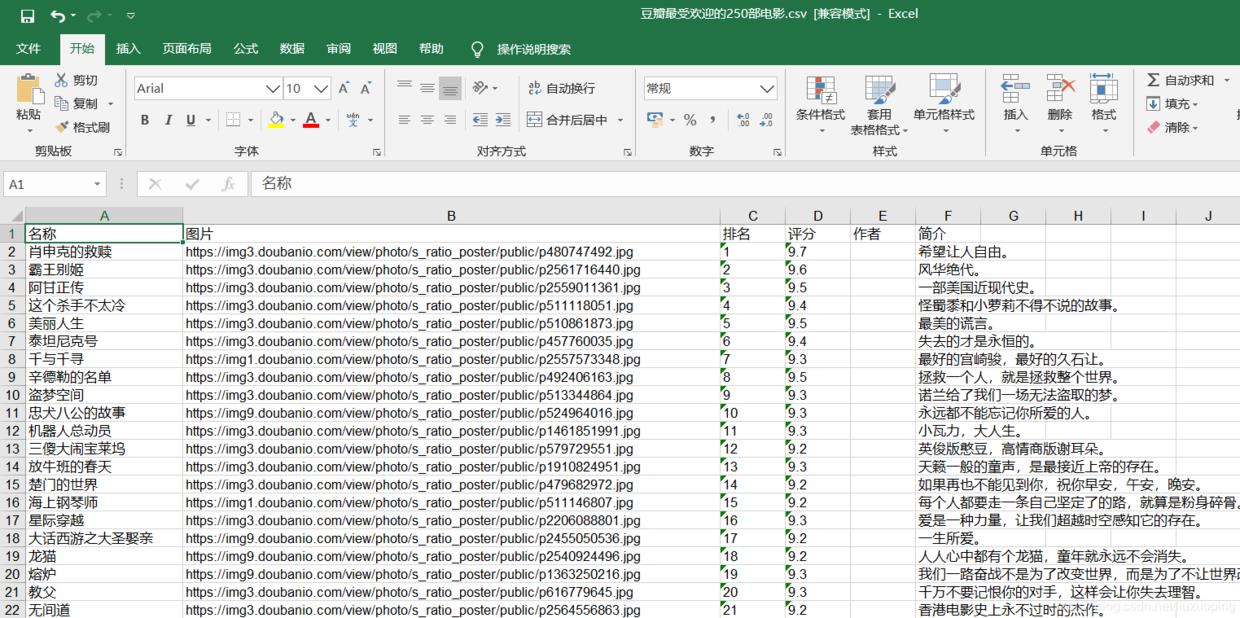
main(i)运行后发现文件夹中多了 “豆瓣最受欢迎的250部电影.csv”这个文件,打开看看
以上是关于爬虫练手项目:获取豆瓣评分最高的电影并下载的主要内容,如果未能解决你的问题,请参考以下文章
.利用python获得豆瓣电影前30部电影的中文片名,排名,导演,主演,上映时间