简单的网页爬虫,获取豆瓣的最新电影信息。
爬虫主要是获取页面,然后对页面进行解析,解析出自己所需要的信息进行进一步分析和挖掘。
首先需要学习python的正则表达式:http://www.cnblogs.com/fnng/archive/2013/05/20/3089816.html
解析的url:http://movie.douban.com/
查看网页源代码,分析要解析的地方:

得到资源信息:
1.电影图片
2.电影标题
3.电影评分
4.电影票信息
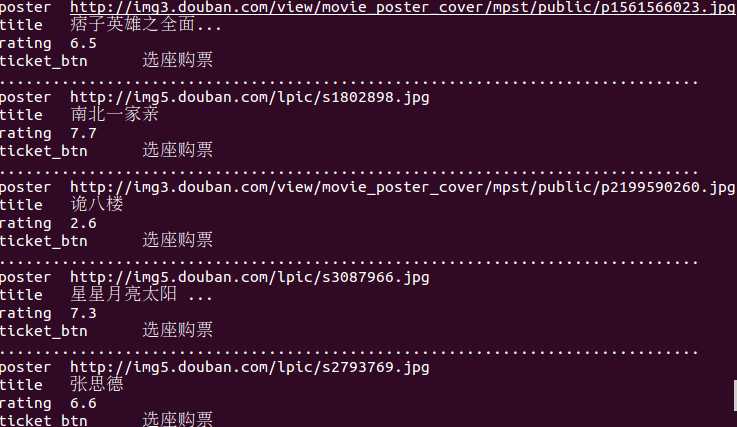
抓取结果为:
python实现代码为:

#!/usr/bin/env python
#coding=utf-8
import urllib
import urllib2
import re
import pymongo
def getHtml(url):
page=urllib2.urlopen(url)
html=page.read()
page.close()
return html
def getContent(html):
reg=r‘<li class="poster">.+?src="(.+?.jpg)".+?</li>.+?class="title".+?
class="">(.+?)</a>.+?class="rating".+?class="subject-rate">(.+?)</span>.+?<a onclick=".+?">(.+?)</a>‘
contentre=re.compile(reg,re.DOTALL)
contentlist=contentre.findall(html)
return contentlist
def getConnection(): #拿到数据库连接
conn=pymongo.Connection(‘localhost‘,27017)
return conn
def saveToDB(contentlist): #存储至mongodb数据库中
conn=getConnection()
db=conn.db
t_movie=db.t_movie
for content in contentlist:
value=dict(poster=content[0],title=content[1],rating=content[2],ticket_btn=content[3])
t_movie.save(value)
def display(contentlist):
for content in contentlist:
#values=dict(poster=content[0],title=content[1],rating=content[2],ticket_btn=content[3])
print ‘poster‘,‘ ‘,content[0]
print ‘title‘,‘ ‘,content[1]
print ‘rating‘,‘ ‘,content[2]
print ‘ticket_btn‘,‘ ‘,content[3]
print‘..............................................................................‘
if __name__=="__main__":
url="http://movie.douban.com/"
html=getHtml(url)
#print html
contentlist=getContent(html)
print len(contentlist)
#print contentlist
display(contentlist)
saveToDB(contentlist)
print "finished"
网页爬虫制作