数据分析-Numpy-Pandas
Posted gaimo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析-Numpy-Pandas相关的知识,希望对你有一定的参考价值。
补充上一篇未完待续的Numpy知识点
索引和切片
数组和标量(数字)之间运算
li1 = [ [1,2,3], [4,5,6] ] a = np.array(li1) a * 2 运行结果: array([[ 2, 4, 6], [ 8, 10, 12]])
索引
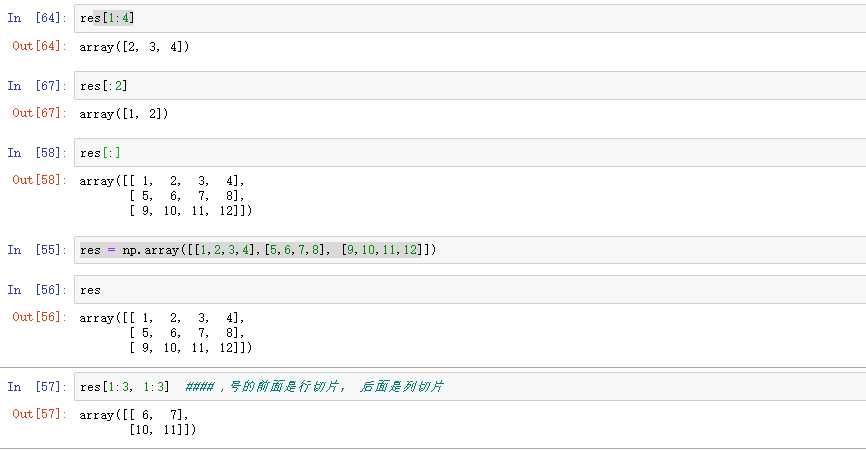
# 将一维数组变成二维数组 arr = np.arange(30).reshape(5,6) # 后面的参数6可以改为-1,相当于占位符,系统可以自动帮忙算几列 arr # 将二维变一维 arr.reshape(30) # 索引使用方法 array([[ 0, 1, 2, 3, 4, 5], [ 6, 7, 8, 9, 10, 11], [12, 13, 14, 15, 16, 17], [18, 19, 20, 21, 22, 23], [24, 25, 26, 27, 28, 29]]) 现在有这样一组数据,需求:找到20 列表写法:arr[3][2] 数组写法:arr[3,2] # 中间通过逗号隔开就可以了

切片
# 多维数组的切片 arr数组 array([[ 0, 1, 2, 3, 4, 5], [ 6, 7, 8, 9, 10, 11], [12, 13, 14, 15, 16, 17], [18, 19, 20, 21, 22, 23], [24, 25, 26, 27, 28, 29]]) arr[1:4,1:4] # 切片方式 行和列 执行结果: array([[ 7, 8, 9], [13, 14, 15], [19, 20, 21]])
布尔型索引
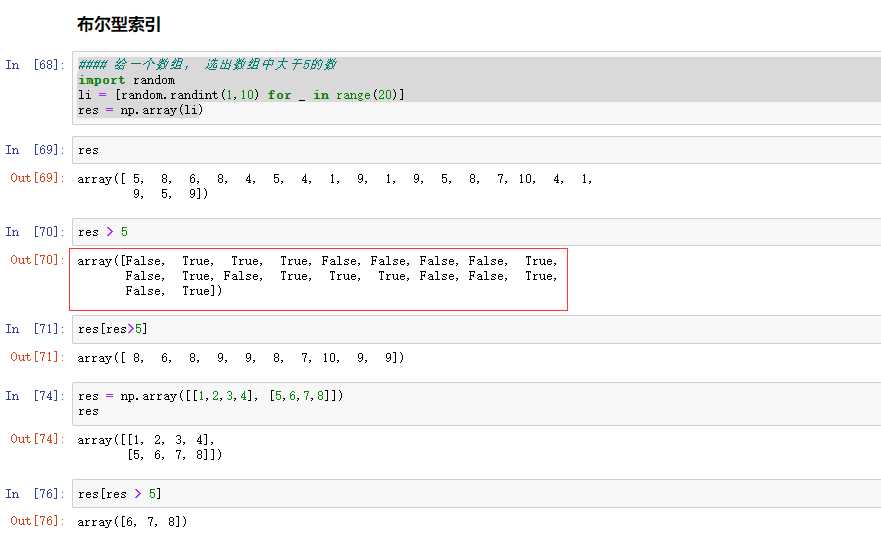
# 现在有这样一个需求:给一个数组,选出数组种所有大于5的数。 li = [random.randint(1,10) for _ in range(30)] a = np.array(li) a[a>5] 执行结果: array([10, 7, 7, 9, 7, 9, 10, 9, 6, 8, 7, 6]) ---------------------------------------------- 原理: a>5会对a中的每一个元素进行判断,返回一个布尔数组 a > 5的运行结果: array([False, True, False, True, True, False, True, False, False, False, False, False, False, False, False, True, False, True, False, False, True, True, True, True, True, False, False, False, False, True]) ---------------------------------------------- 布尔型索引:将同样大小的布尔数组传进索引,会返回一个有True对应位置的元素的数组
花式索引

通用函数
能对数组中所有元素同时进行运算的函数就是通用函数。类似python里的math模块
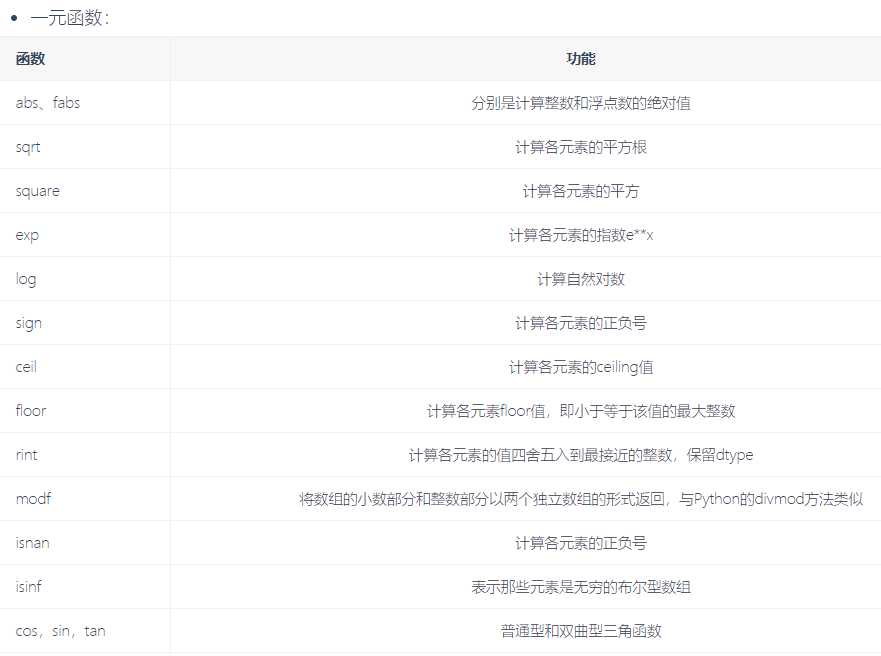
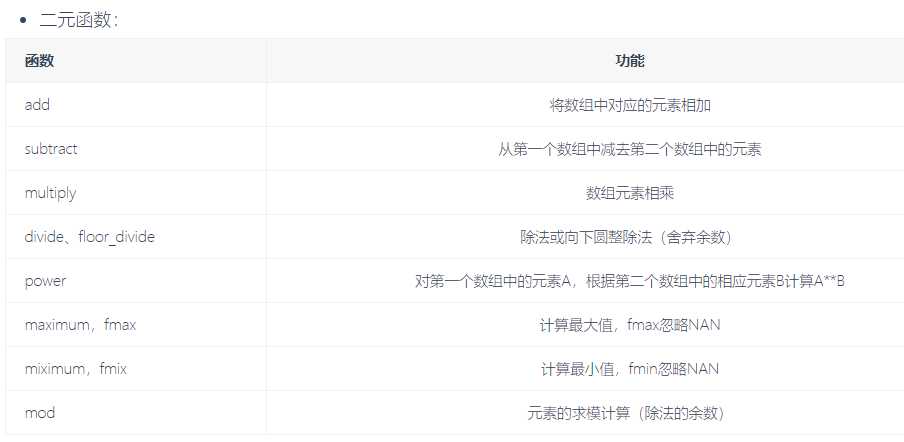
常见通用函数:
能够接受一个数组的叫做一元函数,接受两个数组的叫二元函数,结果返回的也是一个数组
常用的方式示例:
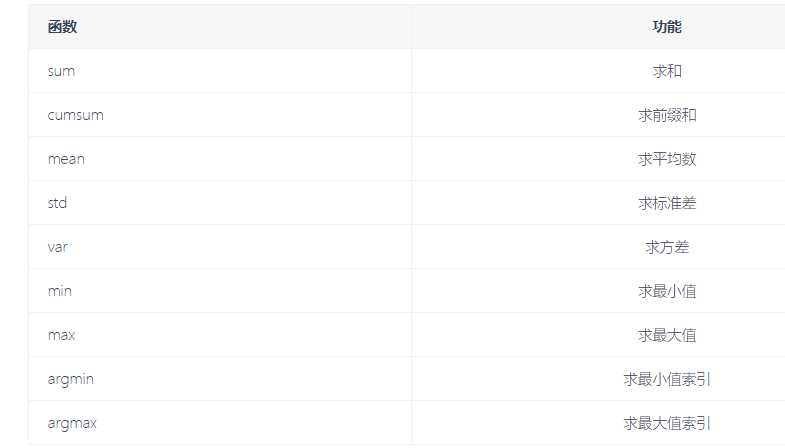
# 求绝对值 np.abs(-2) 2 np.abs([-2,-4,-5,-10]) array([ 2, 4, 5, 10]) # 浮点型的绝对值 np.fabs([-1.3,-2.5,-3.4]) array([1.3, 2.5, 3.4]) #平方根 np.sqrt(4) 2.0 np.sqrt(2) # 求平方根 1.4142135623730951 np.square(2) # 求平方 4 np.exp(2) # e**2 7.38905609893065 np.log(2) 0.6931471805599453 np.ceil(5.4) #### 向上取整 6.0 # 向下取整 np.floor(4.6) 4.0 np.rint(3.5) 4.0 np.rint(3.2) 3.0 # 小数部分和整数部分别返回 np.modf([1.2,3.5]) (array([0.2, 0.5]), array([1., 3.])) ##nan === not a number np.nan nan np.nan == np.nan False np.isnan(56) False np.isnan(np.nan) True #求和 np.sum([1,2,3,4,5]) 15 np.cumsum? li = [1,2,3,4,5] ### 方差: ((1-平均数)**2 + (2-平均数)**2 + ....) / 5 ### 标准差: 方差开根号 res = np.array(li) np.max(res) 5 np.argmax(res) 4
数学统计方法
随机数
随机数生成函数在np.random的子包当中。

Pandas
简介
Series
DataFrame
时间对象处理
数据分组和聚合
其他常用方法
1、简介
pandas是一个强大的Python数据分析的工具包,它是基于Numpy构建的,正因pandas的出现,让Python语言也成为使用最广泛而且强大的数据分析环境之一。
Pandas的主要功能:
1、具备对其功能的数据结构DataFrame,Series
2、集成时间序列功能
3、提供丰富的数学运算和操作
4、灵活处理缺失数据
安装方法:
# pip3 install pandas
引用方法
# import pandas as pd
导包问题:pyc文件,简单的理解是第一次导入模块或包时,先加载生成pyc文件,后续导入加载读取的速度快些。

Series
Series是一种类似于一维数组的对象,由一组数据和一组与之相关的数据标签(索引)组成。
1、创建方法
(1)第一种
pd.Series([4,5,6,7,8]) 执行结果: 0 4 1 5 2 6 3 7 4 8 dtype: int64
(2)第二种
pd.Series([4,5,6,7,8],index=[‘a‘,‘b‘,‘c‘,‘d‘,‘e‘]) 执行结果: a 4 b 5 c 6 d 7 e 8 dtype: int64
# 自定义索引,index是一个索引列表,里面包含的是字符串,依然可以通过默认索引取值。
(3)第三种
pd.Series({"a":1,"b":2})
执行结果:
a 1
b 2
dtype: int64
# 指定索引
(4)第四种
pd.Series(0,index=[‘a‘,‘b‘,‘c‘]) 执行结果: a 0 b 0 c 0 dtype: int64 # 创建一个值都是0的数组
以上是关于数据分析-Numpy-Pandas的主要内容,如果未能解决你的问题,请参考以下文章