ConcurrentHashMap详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ConcurrentHashMap详解相关的知识,希望对你有一定的参考价值。
ConcurrentHashMap详解
注:该文章主要讲的是JDK1.6中ConcurrentHashMap的实现,JDK1.8中ConcurrentHashMap的实现由不同的机制,详解可看:ConcurrentHashMap总结
1 概述
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V> implements ConcurrentMap<K, V>, Serializable {
- ConcurrentHashMap内部使用了分段锁+哈希数组+链表的实现(JDK1.6)
- ConcurrentHashMap是遍历无序、线程安全
- ConcurrentHashMap的迭代器不是快速失败的,也就是说我们在遍历的时候可以对ConcurrentHashMap的结构进行修改,而不会抛出 ConcurrentModificationException异常
- HashMap中key不能有重复元素,并且key与value都不能为null
2 实现机制
2.1 锁分段技术(分拆锁技术)
《Java并发编程艺术》
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因是所有访问HashTable的线程都必须竞争同一把锁,那假如容器里有多把锁,每一把锁用于锁容器其中一>部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞>>争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段>技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
《Java并发编程实践》
分拆锁(lock spliting)就是若原先的程序中多处逻辑都采用同一个锁,但各个逻辑之间又相互独立,就可以拆(Spliting)为使用多个锁,每个锁守护不同的逻辑。 分拆锁有时候可以被扩展,分成可大可小加锁块的集合,并且它们归属于相互独立的对象,这样的情况就是分离锁(lock striping)。
2.2 ConcurrentHashMap结构
ConcurrentHashMap的结构与HashMap的结构类似,只是在中间加了一层锁(Segment)。其类图如下: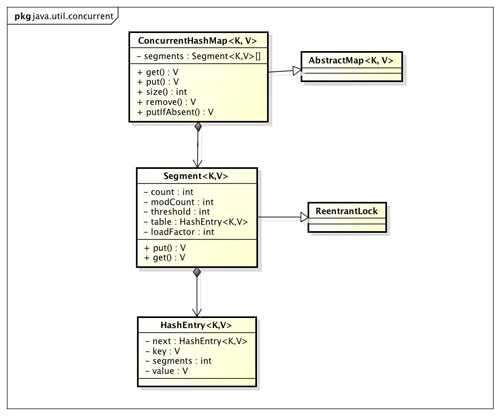
ConcurrentHashMap是有Segment数组组成,每个Segment由HashEntry数组组成,每个HashEntry数组中存放的是HashEntry链表。其中Segment是可重入锁ReentrantLock,它代表锁结构,每个Segment守护它自己包含的HashEntry数组中的元素,这样就体现出锁分段技术。我们在并发访问时,该Segment锁仅仅锁住它自己的一部分数据,从而不会影响其他部分的数据的读写。其结构图如下: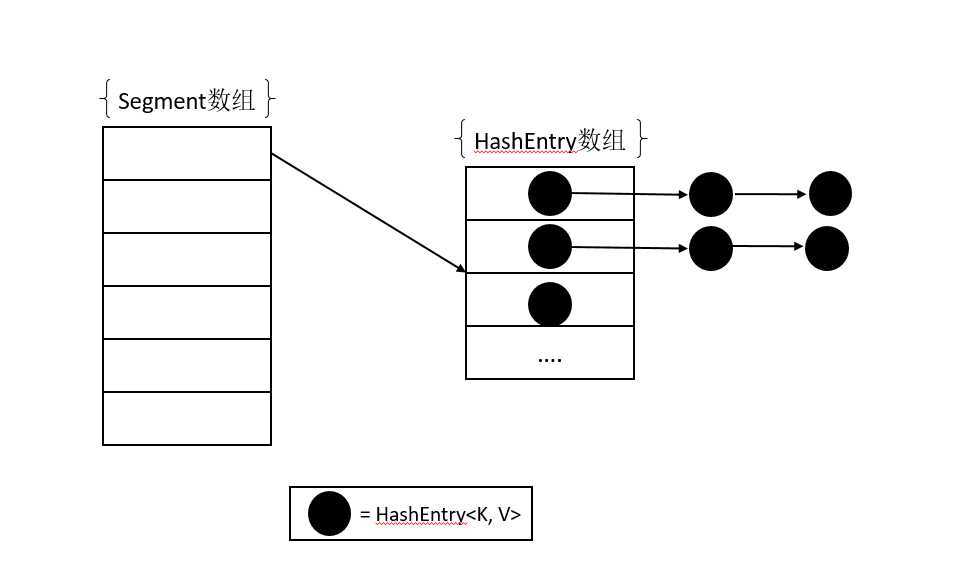
3 一些类的结构分析
注:自己在分析时,有许多的方法都没有分析,主要分析了几个方法的逻辑,其他方法类似。下面的类来自JDK1.6,自己删除了一些字段与方法。
3.1 HashEntry类
- HashEntry用来封装key、value
- key,hash 和 next 域都被声明为 final 型,至于为何为 final变量,后面会分析
- value 域被声明为 volatile 型,至于为何为 volatile 变量,后面会分析
注:next申明为final类型,说明HashEntry链表只能从头插入,而且不能删除。
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value; // value 声明为 volatile 类型
final HashEntry<K,V> next; // next 申明为 final 类型
HashEntry(K key, int hash, HashEntry<K,V> next, V value) {
this.key = key;
this.hash = hash;
this.next = next;
this.value = value;
}
}
3.2 Segment类
- Segment 类继承 ReentrantLock,用来守护其含有的数据
- count 代表该 Segment 中 HashEnty 的数量,是 volatile 类型。
- modCount 代表该 Segment 结构改变的次数
- loadFactor 代表负载因子;threshold 代表该 Segment 最大容量(这两个字段与HashMap中意义相似,用来扩容的)
static final class Segment<K,V> extends ReentrantLock implements Serializable {
/**
* 该 Segment 中包含的 HashEntry 元素的个数
* 该变量被声明为 volatile 型
*/
transient volatile int count;
/**
* 该 Segment 结构改变的次数
*/
transient int modCount;
/**
* 该 Segment 的最大容量
*/
transient int threshold;
/**
* table 是由 HashEntry 数组,用来存放HashEnty链表
*/
transient volatile HashEntry<K,V>[] table;
/**
* 加载因子
*/
final float loadFactor;
/**
* 根据 key 的散列值,找到该散列值对于的 HashEntry 链表
*/
HashEntry<K,V> getFirst(int hash) {
HashEntry<K,V>[] tab = table;
return tab[hash & (tab.length - 1)];
}
/**
* 初始化 HashEntry 数组,设置加载因子 loadFactor
* 计算最大容量 = HashEntry 数组长度 * 加载因子 loadFactor
*/
Segment(int initialCapacity, float lf) {
...
}
/**
* 下面以下方法主要是实现Map的操作的方法,如put、get等等,
* 方法没有写完,后面会详细分析几个方法
* ConcurrentHashMap 对数据的操作其实主要是在 Segment 中对数据
* 操作的体现。
*/
/* Specialized implementations of map methods */
V get(Object key, int hash) {
...
}
boolean containsKey(Object key, int hash) {
...
}
}
3.3 ConcurrentHashMap 类
注:还有许多的方法没有列出来
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
/**
* 由 Segment 对象组成的数组
*/
final Segment<K,V>[] segments;
/**
* 该方法会初始化默认初始容量 (16)、默认加载因子 (0.75) 和 默认并发级别 (16)
* 的空散列映射表。主要功能就是初始化 Segment 数组
*/
public ConcurrentHashMap() {
...
}
/**
* 散列算法
*/
private static int hash(int h) {
// Spread bits to regularize both segment and index locations,
// using variant of single-word Wang/Jenkins hash.
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
/**
* 通过散列值计算出在哪个 Segment 中
*/
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
/**
* ConcurrentHashMap 的方法,如put、get等等
* 方法没有展示完
*/
public V put(K key, V value) {
....
}
}
4 具体的操作
注:这里要写 ConcurrentHashMap 的线程安全是怎么实现的,需要对JMM(Java内存模型)、volatile 变量、happens-before 等等并发知识进行了解,具体可见:Java并发编程(一)
4.1 put 操作
首先通过 key 的哈希值找到其对应的 Segment,然后该 Segment 对于的 put 方法
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
// 通过散列算法计算 key 的散列值
int hash = hash(key.hashCode());
// 根据散列码找到对应的 Segment
return segmentFor(hash).put(key, hash, value, false);
}
Segment 中的 put 方法
V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 获取锁,这里只是把该 Segment 锁住了,体现了分段锁的思想
lock();
try {
// count代表该 Segment 中HashEntry数目,其是volatile变量
// 注意:这里不能直接 count++,因为单个volatile变量的写才有原子性
// 像 volatile++ 这种复合操作是没有原子性的
int c = count;
// 判断该 Segment 能否存放
if (c++ > threshold) // ensure capacity
// 扩容
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
// 如果该 key 已经存在,则替换原 value,返回原 value
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
// 该 key 没有存在,则向 HashMap 链表添加一个 HashMap
// 注意:只能在链表的头部添加,因为 HashEntry.next 是 final 类型。
else {
oldValue = null;
// 要添加新节点到链表中,链表的结构改变,所以 modCont 要加 1
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
// 改变 count 值,count 是 volatile 变量
// 注意:这里写 volatile 变量,会把变化的值向主内存中写,
// 并通知读 volatile 变量的线程从主内存中读取
// 这里与 get() 方法中对 count 的读取形成 happens-before 关系
count = c; // write-volatile
}
return oldValue;
} finally {
// 释放锁
unlock();
}
}
注意:这里仅仅对该 Segment 加锁了,没有对整个 ConcurrentHashMap 进行加锁。这里表现出分段锁思想,其它线程依然可以获取其他 Segment 的锁进行写操作。
扩容:这里是对单独的 Segment 的容量进行扩容,没有对这个容器进行扩容。
以上我们可以总结出:
- Segment 数组的长度代表并发级别(理想状态下,数组的长度为 ConcurrentHasMap 可以支持线程并发操作的数目)
- ConcurrentHashMap 的 size 是每个 Segment 的 count 之和
4.2 remove 操作
首先通过 key 的哈希值找到其对应的 Segment,然后该 Segment 对于的 remove 方法
public V remove(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).remove(key, hash, null);
}
Segment 中的 remocve 方法
V remove(Object key, int hash, Object value) {
// 获取锁,理由同上
lock();
try {
// 读取 count 值,理由同上
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if (e != null) {
V v = e.value;
// 找到要删除的节点
if (value == null || value.equals(v)) {
oldValue = v;
// 要删除一个节点,链表的结构改变,所以 modCont 要加 1
++modCount;
// 这里删除一个节点,写法特别,下面会分析
HashEntry<K,V> newFirst = e.next;
for (HashEntry<K,V> p = first; p != e; p = p.next)
newFirst = new HashEntry<K,V>(p.key, p.hash, newFirst, p.value);
tab[index] = newFirst;
// 写 count 的值,理由同上
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
}
注意:这里的删除并不是直接的删除该节点,因为 HashEntry.next 是 final 类型,不能直接删除。它首先找到要删除的那个节点,然后把删除那个节点之前的没有节点中的值复制到新节点中,最后构成一个新链条。具体如下:
执行删除之前的原链表:
执行删除之后的新链表: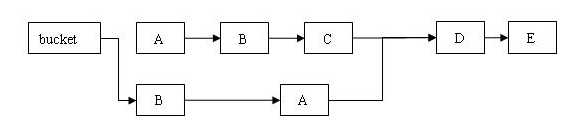
从上图可以看出,删除节点 C 之后的所有节点原样保留到新链表中;删除节点 C 之前的每个节点被克隆到新链表中,注意:它们在新链表中的链接顺序被反转了。
在执行 remove 操作时,原始链表的结构并没有被修改,综合上面的分析我们可以看出,写线程对某个链表的结构性修改不会影响其他的并发读线程对这个链表的遍历访问。
4.3 get 操作
首先通过 key 的哈希值找到其对应的 Segment,然后该 Segment 对于的 remove 方法
public V get(Object key) {
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash);
}
Segment 中的 get方法
V get(Object key, int hash) {
// 读 count 值,count 是 volatile 变量
// 注意:这里是读 volatile 变量,它会从主内存中读取
// 它始终会读取到 volatile 更新后的内存中变化
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
// 如果为 null,加锁后读
return readValueUnderLock(e); // recheck
}
e = e.next;
}
return null;
}
/**
* 加锁读的方法
*/
V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
}
我们可以看到其他的写操作(如 put、remove等)都加锁了的,所以体现出并发性。而这里读(get、contains等)没有进行加锁,这里使用了 volatile 类型的内存可见性:写线程修改了 volatile 变量,读线程一定能够读到修改后的值。
所以这里可以回答 HashEntry 中 value 为什么是 volatile 变量,以及 count 为什么是 volatile 变量:因为每次写线程修改后的值,读线程一定能够读到。
至于为什么 HashEntry.next 为何是 final 类型的:因为在修改链表结构时(remove、put等),写线程不会对原链表结构进行修改,所以读线程在不加锁的情况下仍然可以对该链表进行遍历访问。
4.3 size 操作
统计整个 ConcurrentHashMap 的 size 大小,就是必须统计每个 Segment 的 count 大小后求和。其中 Segment 中的 count 变量是 volatile 变量,每个 count 变量都是最。但是如果我们累加后,就不一定会得到 ConcurrentHashMap 的大小,因为如果在累加时使用过的 count 发生改变,那么结果就不准确了。如果统计大小时,锁住会导致效率低下。因为在累加 count 的操作过程中,之前累加 count 的值发生变化的几率不大。所以,在 JDK 1.6 中通过连续统计两次,比较两次统计结果,如果发生变化则会加锁方式。
public int size() {
final Segment<K,V>[] segments = this.segments;
long sum = 0;
long check = 0;
int[] mc = new int[segments.length];
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
for (int k = 0; k < RETRIES_BEFORE_LOCK; ++k) {
check = 0;
sum = 0;
int mcsum = 0;
for (int i = 0; i < segments.length; ++i) {
sum += segments[i].count;
mcsum += mc[i] = segments[i].modCount;
}
if (mcsum != 0) {
for (int i = 0; i < segments.length; ++i) {
check += segments[i].count;
if (mc[i] != segments[i].modCount) {
check = -1; // force retry
break;
}
}
}
if (check == sum)
break;
}
if (check != sum) { // Resort to locking all segments
sum = 0;
for (int i = 0; i < segments.length; ++i)
segments[i].lock();
for (int i = 0; i < segments.length; ++i)
sum += segments[i].count;
for (int i = 0; i < segments.length; ++i)
segments[i].unlock();
}
if (sum > Integer.MAX_VALUE)
return Integer.MAX_VALUE;
else
return (int)sum;
}
5 总结
- ConcurrentHashMap 不同于使用同步包装器包装的 HashMap(Collections.synchronizedMap(new HashMap()) 或者 HashTable 等使用全局锁来进行并发访问的控制,其使用了分段锁机制实现了多个线程同时写不会等待。
- ConcurrentHashMap 利用了 volatile 变量的内存可见性,以及 HashEntery 链表的不变性让读操作可以不进行加锁。
6 应用
自己模仿 JDK1.6 中 ConcurrentHashMap 写的 put()、get()、remove() 方法,其它方法,如 entrySet() 方法由于自己不太懂具体实现,直接使用了 JDK 1.6 的代码


1 /** 2 * Created by kanyuxia on 2017/5/21. 3 */ 4 public class StudyConcurrentHashMap { 5 public static void main(String[] args) throws Exception { 6 7 } 8 } 9 10 11 class ConcurrentHashMap<K, V> extends AbstractMap<K, V> { 12 13 // ------------------------------Construct method 14 @SuppressWarnings("unchecked") 15 public ConcurrentHashMap() { 16 this.segments = new Segment[DEFAULT_CONCURRENCY_LEVEL]; 17 for (int i = 0; i < segments.length; i++) { 18 segments[i] = new Segment<>(DEFAULT_INITIAL_CAPACITY); 19 } 20 } 21 22 // -----------------------------Field 23 /** 24 * 散列映射表的默认初始容量为 16,即初始默认为16个桶 25 * 在构造函数中没有指定这个参数时,使用本参数 26 */ 27 static final int DEFAULT_INITIAL_CAPACITY = 16; 28 29 /** 30 * 散列表的默认并发级别为 16。该值表示当前更新线程的估计数 31 * 在构造函数中没有指定这个参数时,使用本参数 32 */ 33 static final int DEFAULT_CONCURRENCY_LEVEL = 16; 34 35 static final int SEGMENT_SHIFT = 28; 36 37 static final int SEGMENT_MASK = 15; 38 39 40 41 /** 42 * 由Segment对象组成的数组 43 */ 44 final Segment<K, V>[] segments; 45 46 transient Set<Map.Entry<K,V>> entrySet; 47 48 // --------------------------Some util methods 49 /** 50 * 哈希再散列,减少哈希冲突:JDK1.6算法 51 * @param h key的哈希值 52 * @return 再散列后的哈希值 53 */ 54 private int hash(int h) { 55 h += (h << 15) ^ 0xffffcd7d; 56 h ^= (h >>> 10); 57 h += (h << 3); 58 h ^= (h >>> 6); 59 h += (h << 2) + (h << 14); 60 return h ^ (h >>> 16); 61 } 62 63 /** 64 * 通过key散列后的哈希值来得到segments数组中对应的 Segment 65 * @param hash key再散列后的哈希值 66 * @return Segment segment 67 */ 68 private Segment<K,V> segmentFor(int hash) { 69 return segments[(hash >>> SEGMENT_SHIFT) & SEGMENT_MASK]; 70 } 71 72 // -------------------------------Some public methods 73 @Override 74 public V get(Object key) { 75 if (key == null) { 76 throw new NullPointerException(); 77 } 78 int hash = hash(key.hashCode()); 79 return segmentFor(hash).get(key, hash); 80 } 81 82 @Override 83 public V put(K key, V value) { 84 if (key == null || value == null) { 85 throw new NullPointerException(); 86 } 87 int hash = hash(key.hashCode()); 88 return segmentFor(hash).put(key, value, hash); 89 } 90 91 @Override 92 public boolean remove(Object key, Object value) { 93 if (key == null || value == null) { 94 throw new NullPointerException(); 95 } 96 int hash = hash(key.hashCode()); 97 return segmentFor(hash).remove(key, value, hash) != null; 98 } 99 100 @Override 101 public V remove(Object key) { 102 if (key == null) { 103 throw new NullPointerException(); 104 } 105 int hash = hash(key.hashCode()); 106 V value = segmentFor(hash).get(key, hash); 107 return segmentFor(hash).remove(key, value, hash); 108 } 109 110 @Override 111 public int size() { 112 final Segment<K,V>[] segments = this.segments; 113 long sum = 0; 114 long check = 0; 115 int[] mc = new int[segments.length]; 116 // Try a few times to get accurate count. On failure due to 117 // continuous async changes in table, resort to locking. 118 for (int k = 0; k < 2; ++k) { 119 check = 0; 120 sum = 0; 121 int mcsum = 0; 122 for (int i = 0; i < segments.length; ++i) { 123 sum += segments[i].count; 124 mcsum += mc[i] = segments[i].modCount; 125 } 126 if (mcsum != 0) { 127 for (int i = 0; i < segments.length; ++i) { 128 check += segments[i].count; 129 if (mc[i] != segments[i].modCount) { 130 check = -1; // force retry 131 break; 132 } 133 } 134 } 135 if (check == sum) 136 break; 137 } 138 if (check != sum) { // Resort to locking all segments 139 sum = 0; 140 for (int i = 0; i < segments.length; ++i) 141 segments[i].lock(); 142 for (int i = 0; i < segments.length; ++i) 143 sum += segments[i].count; 144 for (int i = 0; i < segments.length; ++i) 145 segments[i].unlock(); 146 } 147 if (sum > Integer.MAX_VALUE) 148 return Integer.MAX_VALUE; 149 else 150 return (int)sum; 151 } 152 153 @Override 154 public void clear() { 155 for (int i = 0; i < segments.length; i++) 156 segments[i].clear(); 157 } 158 159 @Override 160 public Set<Entry<K, V>> entrySet() { 161 Set<Map.Entry<K,V>> es = entrySet; 162 return (es != null) ? es : (entrySet = new EntrySet()); 163 } 164 165 166 // ----------------------------Inner class 167 static class Segment<K, V> extends ReentrantLock implements Serializable { 168 // --------------------Construct method 169 @SuppressWarnings("unchecked") 170 Segment(int initialCapacity) { 171 table = new Node[initialCapacity]; 172 } 173 // ---------------------Field 174 private static final long serialVersionUID = 7249069246763182397L; 175 // 该Segment中Node的数目 176 volatile int count; 177 // 该Segment中Node[]结构的变化次数 178 int modCount; 179 // 存放Node的数组 180 volatile Node<K, V>[] table; 181 182 183 // ----------------------Some methods 184 /** 185 * 根据key再散列后的哈希值,返回segment中第一个链表节点 186 * @param hash key再散列后的哈希值 187 * @return 返回segment中第一个链表节点 188 */ 189 Node<K, V> getFirst(int hash) { 190 return table[hash & (table.length - 1)]; 191 } 192 193 V get(Object key, int hash) { 194 // 读volatile变量,获取主内存中共享变量 195 if (count != 0) { 196 Node<K, V> node = getFirst(hash); 197 while (node != null) { 198 if (key.equals(node.key) && node.hash == hash) { 199 V value = node.getValue(); 200 if (value != null) { 201 return value; 202 } 203 // 如果value为null,说明发生了重排序,加锁后重读 204 return readValueUnderLock(node); // recheck 205 } 206 node = node.next; 207 } 208 return null; 209 } 210 return null; 211 } 212 213 V readValueUnderLock(Node<K,V> e) { 214 lock(); // 获取锁 215 try { 216 return e.value; 217 } finally { 218 unlock(); // 释放锁 219 } 220 } 221 222 V put(K key, V value, int hash) { 223 lock(); // 获取锁 224 try { 225 // 这里c是用来验证是否超过容量的,我没有写扩容机制。 226 // 虽然看起来这里如果没有扩容机制的话,就可以不使用本地变量c, 227 // 但是这里必须使用本地变量把count的值加一,不能直接count++, 228 // 因为只有单个volatile变量的写才有原子性,如果是volatile++,则不具有原子性。 229 // 而且我们要先读volatile变量才能获取主内存中的共享变量。 230 int c = count; 231 c++; 232 Node<K, V> node = getFirst(hash); 233 Node<K, V> e = null; 234 while (node != null) { 235 if (key.equals(node.key) && value.equals(node.value) && hash == node.hash) { 236 e = node; 237 } 238 node = node.next; 239 } 240 // 如果该key、value存在,则修改后返回原值,且结果没有变化。 241 if (e != null) { 242 V oldValue = e.value; 243 e.value = value; 244 return oldValue; 245 } 246 // 该key、value不存在,则添加一个新节点添加到链表头: 247 // 这样的话原链表结构不会发生变化,使得其他读线程正常遍历这个链表。 248 Node<K, V> first = getFirst(hash); 249 e = new Node<>(hash, first, key, value); 250 table[hash & (table.length - 1)] = e; 251 // 因为添加新节点了,所以modCount要加1 252 modCount++; 253 // count数量加1:写volatile变量使得该修改对所有读都有效。 254 count = c; 255 return value; 256 } finally { 257 unlock(); // 释放锁 258 } 259 } 260 261 V remove(Object key, Object value, int hash) { 262 lock(); // 获取锁 263 try { 264 // 与put方法中意义相似,就解释了 265 int c = count; 266 c--; 267 Node<K, V> node = getFirst(hash); 268 Node<K, V> e = null; 269 while (node != null) { 270 if (node.hash == hash && node.key.equals(key) && node.value.equals(value)) { 271 e = node; 272 } 273 node = node.next; 274 } 275 // 该key、value不存在,返回null 276 if (e == null) { 277 return null; 278 } 279 // 该key、value存在,需要删除一个节点 280 // 这里的删除没有真正意义上的删除,它新建了一个链表 281 // 使得原链表结果没有发生变化,其他读线程正常遍历这个链表 282 V oldValue = e.value; 283 Node<K, V> newFirst = e.next; 284 Node<K, V> first = getFirst(hash); 285 while (first != e) { 286 newFirst = new Node<>(first.hash, newFirst, first.key, first.value); 287 first = first.next; 288 } 289 table[hash & (table.length - 1)] = newFirst; 290 // 因为删除了一个节点,所以modCount要加1 291 modCount++; 292 // 写volatile变量使得该修改对所有读都有效。 293 count = c; 294 return oldValue; 295 } finally { 296 unlock(); // 释放锁 297 } 298 } 299 300 void clear() { 301 if (count != 0) { 302 lock(); // 获取锁 303 try { 304 Node<K,V>[] tab = table; 305 for (int i = 0; i < tab.length ; i++) 306 tab[i] = null; 307 // 因为删除了一个节点,所以modCount要加1 308 ++modCount; 309 // 写volatile变量使得该修改对所有读都有效。 310 count = 0; 311 } finally { 312 unlock(); // 释放锁 313 } 314 } 315 } 316 } 317 318 static class Node<K, V> implements Map.Entry<K, V> { 319 final int hash; 320 final Node<K, V> next; 321 final K key; 322 volatile V value; 323 324 public Node(int hash, Node<K, V> next, K key, V value) { 325 this.hash = hash; 326 this.next = next; 327 this.key = key; 328 this.value = value; 329 } 330 331 @Override 332 public K getKey() { 333 return key; 334 } 335 336 @Override 337 public V getValue() { 338 return value; 339 } 340 341 @Override 342 public V setValue(V value) { 343 V oldValue = this.value; 344 this.value = value; 345 return oldValue; 346 } 347 } 348 349 350 351 final class EntrySet extends AbstractSet<Map.Entry<K,V>> { 352 public Iterator<Map.Entry<K,V>> iterator() { 353 return new EntryIterator(); 354 } 355 public boolean contains(Object o) { 356 if (!(o instanceof Map.Entry)) 357 return false; 358 Map.Entry<?,?> e = (Map.Entry<?,?>)o; 359 V v = ConcurrentHashMap.this.get(e.getKey()); 360 return v != null && v.equals(e.getValue()); 361 } 362 public boolean remove(Object o) { 363 if (!(o instanceof Map.Entry)) 364 return false; 365 Map.Entry<?,?> e = (Map.Entry<?,?>)o; 366 return ConcurrentHashMap.this.remove(e.getKey(), e.getValue()); 367 } 368 public int size() { 369 return ConcurrentHashMap.this.size(); 370 } 371 public void clear() { 372 ConcurrentHashMap.this.clear(); 373 } 374 } 375 376 final class EntryIterator extends HashIterator implements Iterator<Entry<K,V>> { 377 public Map.Entry<K,V> next() { 378 Node<K,V> e = super.nextEntry(); 379 return new WriteThroughEntry(e.key, e.value); 380 } 381 } 382 383 final class WriteThroughEntry 384 extends AbstractMap.SimpleEntry<K,V> 385 { 386 WriteThroughEntry(K k, V v) { 387 super(k,v); 388 } 389 390 /** 391 * Set our entry‘s value and write through to the map. The 392 * value to return is somewhat arbitrary here. Since a 393 * WriteThroughEntry does not necessarily track asynchronous 394 * changes, the most recent "previous" value could be 395 * different from what we return (or could even have been 396 * removed in which case the put will re-establish). We do not 397 * and cannot guarantee more. 398 */ 399 public V setValue(V value) { 400 if (value == null) throw new NullPointerException(); 401 V v = super.setValue(value); 402 ConcurrentHashMap.this.put(getKey(), value); 403 return v; 404 } 405 } 406 407 /* ---------------- Iterator Support -------------- */ 408 409 abstract class HashIterator { 410 int nextSegmentIndex; 411 int nextTableIndex; 412 Node<K,V>[] currentTable; 413 Node<K, V> nextEntry; 414 Node<K, V> lastReturned; 415 416 HashIterator() { 417 nextSegmentIndex = segments.length - 1; 418 nextTableIndex = -1; 419 advance(); 420 } 421 422 public boolean hasMoreElements() { return hasNext(); } 423 424 final void advance() { 425 if (nextEntry != null && (nextEntry = nextEntry.next) != null) 426 return; 427 428 while (nextTableIndex >= 0) { 429 if ( (nextEntry = currentTable[nextTableIndex--]) != null) 430 return; 431 } 432 433 while (nextSegmentIndex >= 0) { 434 Segment<K,V> seg = segments[nextSegmentIndex--]; 435 if (seg.count != 0) { 436 currentTable = seg.table; 437 for (int j = currentTable.length - 1; j >= 0; --j) { 438 if ( (nextEntry = currentTable[j]) != null) { 439 nextTableIndex = j - 1; 440 return; 441 } 442 } 443 } 444 } 445 } 446 447 public boolean hasNext() { return nextEntry != null; } 448 449 Node<K,V> nextEntry() { 450 if (nextEntry == null) 451 throw new NoSuchElementException(); 452 lastReturned = nextEntry; 453 advance(); 454 return lastReturned; 455 } 456 457 public void remove() { 458 if (lastReturned == null) 459 throw new IllegalStateException(); 460 ConcurrentHashMap.this.remove(lastReturned.key); 461 lastReturned = null; 462 } 463 } 464 }
6 Reference
探索 ConcurrentHashMap 高并发性的实现机制
《Java并发编程的艺术》
以上是关于ConcurrentHashMap详解的主要内容,如果未能解决你的问题,请参考以下文章