运维流程系统
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了运维流程系统相关的知识,希望对你有一定的参考价值。
一 图论概述
1 图的分类
1 无向图
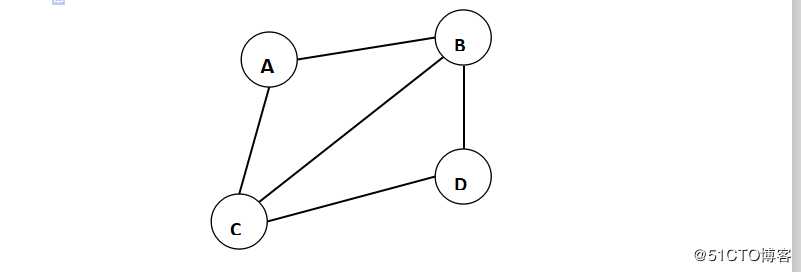
图 graph由顶点和边组成,顶点的又穷非空集合为V,边的集合为E,记做G(V,E)
顶点vertex,数据元素的集合,顶点的集合,又穷非空,
边edge,数据元素关系的集合,顶点关系的集合,可以为空,边分为有向和无向两种无向边记做(A,B),或者(B,A),使用小括号
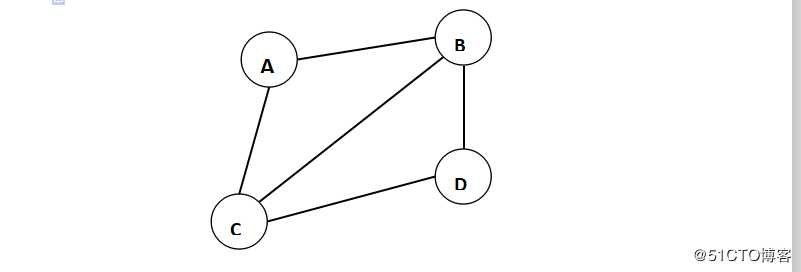
无向图,记做undirected Graph 无向边的边构成的图,G=(V,E),V={A,B,C,D},E={(A,B),(A,C),(B,C),(B,D),(C,D)}
2 有向图
有向边记做<A,B>,即从顶点A指向顶点B,<B,A>表示顶点B指向顶点A,使用尖括号,有向边也叫做弧,边表示为弧尾指向弧头。
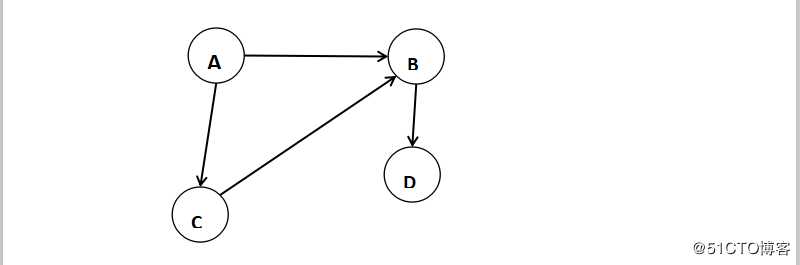
有向图directed graph
有方向的边组成的图
G=(V,E) V={A,B,C,D} E={<A,B>,<A,C>,<C,B>,<B,D>}
3 图的其他概念
1 稀疏图 sparse graph
图中边很少,最稀疏的情况是只有顶点没有边,这就是数据结构SET
2 稠密图 dense Graph
图中边很多,最稠密的情况,任意2个顶点之间都有关系
3 完全图 complete graph
包括了所有可能的边,达到了稠密图最稠密的情况,任意两个顶点之间都有边相连
有向的边的完全图,叫做有向完全图,边数为n*(n-1)
无向的边的完全图,叫做无向完全图,边数为n(n-1)/2
4 子图
如果图G(V,E)满足V` <=V,且E` <=E,则G`是G的子图
换句话说,就是一个图的部分顶点和部分边组成的图为子图,有向图需要注意边的方向
前面的图包含后面的图,后面的图可以称为前面的图的子图
一个图的部分顶点可能是所有顶点,其部分边也可能是所有边
有向图,边是由方向的,如果找不到对应的方向,则不是其子图,或者方向相反,则不是其子图
5 边的权weight和网
给边赋予的值称为权,权可以表示距离,所需的时间,耗费的时间等
网network 图中有边有权,图称为网
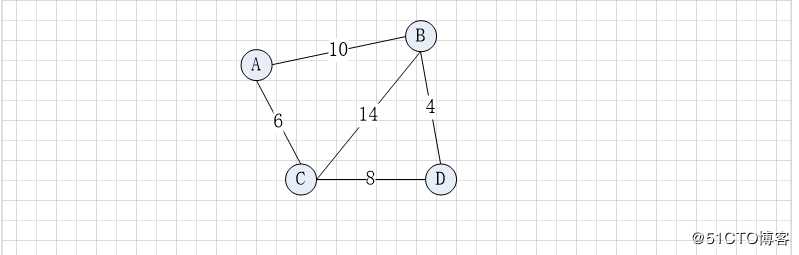
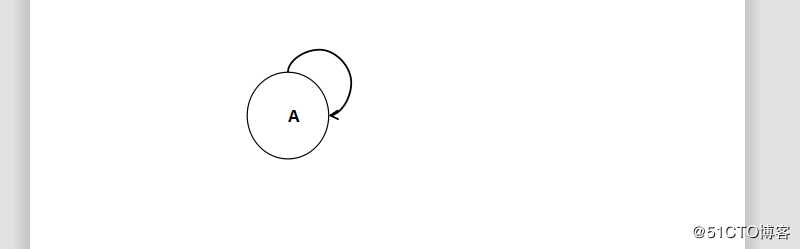
6 自环 loop
若一条边的两个顶点为同一个顶点,则此边称为自环
边中存在这样一个边(u,v) 或者<u,v> ,u=v
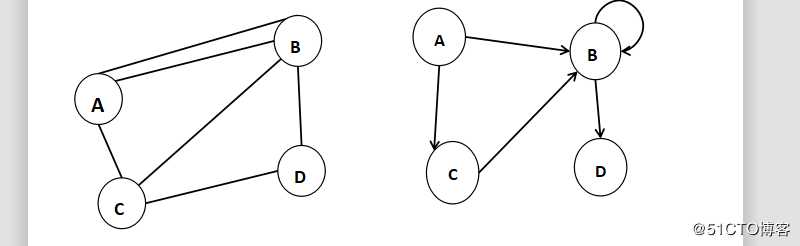
7 简单图
无重复的边或者顶点到自身的边(自环)的图
下面的两个图都不是简单图
4 邻接关联
1 邻接
图的边集合为E
无向图,若 (u,v) 属于 E,则称u和v相互邻接,互为邻接顶点
有向图,若<u,v>属于E,则边u邻接到v,或者v邻接于u
简单说,就是2点之间有条边,2点邻接
2 关联(依附)
若 (u,v)属于E或者 <u,v>属于E,则称边依附于顶点u,v或者顶点u,v 与边相关联。
5 路径path
1 基础路径
图G(V,E),其任意一个顶点序列,相邻2个顶点都能找到边或者弧依次链接,就说明有路径存在,有向图的弧注意方向,所有的顶点都属于V,所有的边都属于E。
顶点之间形成了路径,此处称为弧。
路径长度
等于顶点数减一,等于此路径上的边数
2 简单路径
路径上的顶点不重复出现,这两的路径就是简单路径
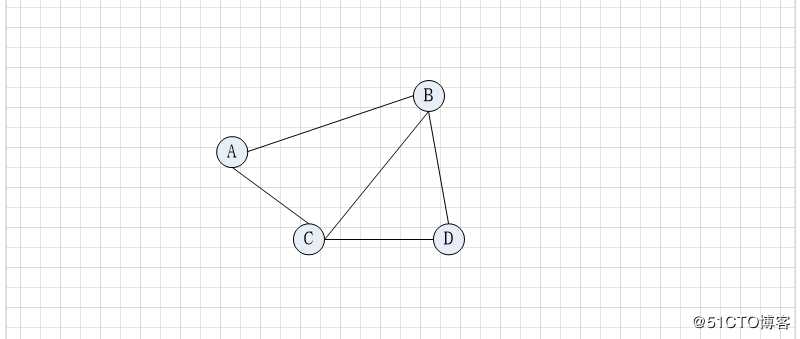
无向图中A到D的路径有A-B-D,A-C-D,A-C-B-D 等
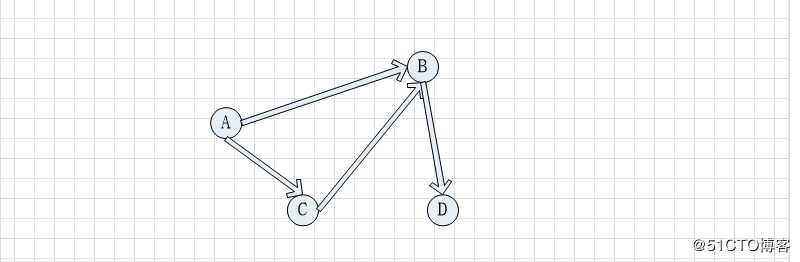
有向图中A到D的路径有A-B-D,A-C-B-D等
3 回路
路径的起点和终点相同,称为回路
A-B-C-A-B-A
4 简单回路
除了路径的起点和终点相同外,其他顶点都不相同
A-B-C-A
6 连通
1 连通
无向图中,顶点存在路径,则两个顶点是连通的
注意: 连通是指A-D之间有路径,而不是说这两个个顶点要邻接
2 连通图
无向图中,如果图中任意两个顶点之间都连通,就是连通图
3 连通分量
无向图中,指的是极大连通子图
无向图未必是连通图,但是它可以包含连通子图
4 强连通
有向图中,顶点键存在2条相关的路径,及从A到B有路径,也存在从B到A的路径,两个顶点是强连通的
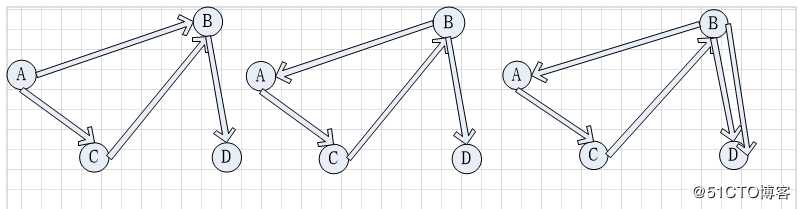
上述中第三个图中有强连接,如B-D和D-B,A-C-B和B-A
5 强联通图
有向图中,如果图中任意2个顶点都是强联通的图
6 强联通分量
有向图中,指的是"极大连通子图"
有向图未必是强联通图,但是可以包含强联通分量
7 度 degree
一个顶点的度指的是与该顶点相关联的边的条数,顶点v的度记做TD(v),无向图顶点的边数叫做度
有向图的顶点有入度和出度,顶点的度数为入度和出度之和 TD(v)=ID(v)+OD(v)
入度(In-degree): 一个顶点的入度是指与其关联的各个边中,以其为终点的边数
出度(Out-degree): 出度则是相对的概念,指以该顶点为起点的边数。
8 生成树
1 简单描述
它是一个极小连通子图,它要包含图的所有n个节点,但只只要有构成一颗数的n-1条边
如果一个图有n个顶点,且少于n-1条边,则一定是非连通图,因为至少要有n-1条边才行
如果一个图有n个顶点,且多于n-1条边,则一定有环存在,一定有2个顶点之间存在第二条路径,但不一定是连通图
如果一个图由n个顶点,且有n-1条边,但不一定是生成树,要整好等于n-1条边,且这些边足以构成一颗数
2 有向树
一个有向树恰好有一个入度为0的顶点,其他顶点的入度都为1,注意,这里不关心出度。
3 生成树森林
若干有向树构成有向树森林
有向无环树不一定能转化为数,但数一定是有向无环图。
二 邻接矩阵
1 概述
图是由vertex 和edge组成,所以可以分为2个数组表示
顶点使用一维数组表示,如v0,v1,v3
边使用二维数组表示,由顶点构成二维数组
2 无向邻接矩阵
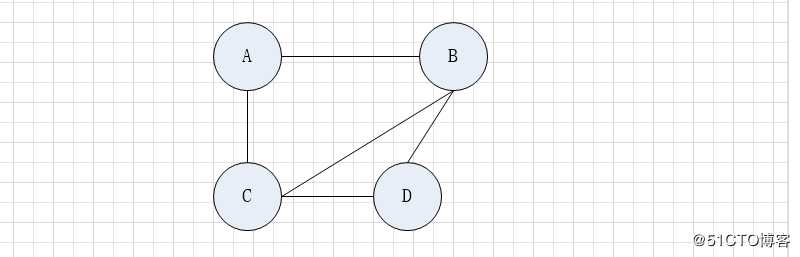
下图中,若存在边。则为1,否则为0
| A | B | C | D | ||
|---|---|---|---|---|---|
| A | 0 | 1 | 1 | 0 | 2 |
| B | 1 | 0 | 1 | 1 | 3 |
| C | 1 | 1 | 0 | 1 | 3 |
| D | 0 | 1 | 1 | 0 | 2 |
| 2 | 3 | 3 | 2 |
此处的相关的最后行和最后一列表示度数,如果上述的对角线上的数字为1,则表示有了自环
如果除了对角线全是1,说明没有自环,且是一个无向完全图
上面的矩阵,称为图的邻接矩阵
顶点的度数,等于对应行或者列求和
邻接点,矩阵中为1的值对应的行与列的顶点就是邻接点。
无向图的邻接矩阵是一个对称矩阵
3 有向邻接矩阵
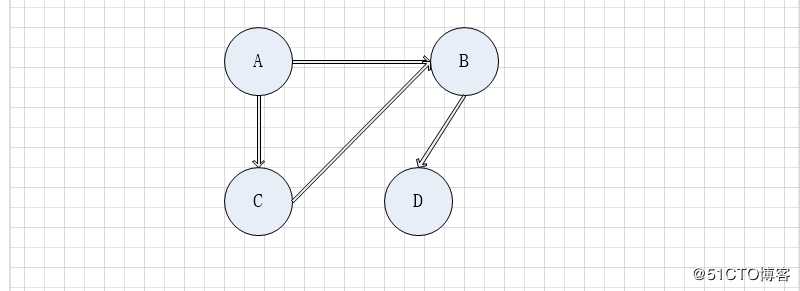
有向邻接矩阵因为是有向的,只有方向正确才是1,否则都是0
| A | B | C | D | ||
|---|---|---|---|---|---|
| A | 1 | 1 | 1 | 0 | 2 |
| B | 0 | 0 | 0 | 1 | 1 |
| C | 0 | 1 | 0 | 0 | |
| D | 0 | 0 | 0 | 0 | |
| 0 | 2 |
有向图的邻接矩阵不一定对称,对称的说明两个顶点之间存在环
三 运维流程系统设计
1 概述
某一个基点上有一批任务需要执行,如何执行
一个接一个排队开始执行,但是这样的执行可能很没有效率,而且没必要,如获取两个毫不相关的信息,谁先执行都可以,同时执行也没问题,这样的任务便可以并行处理,而不只是串行化进行处理。
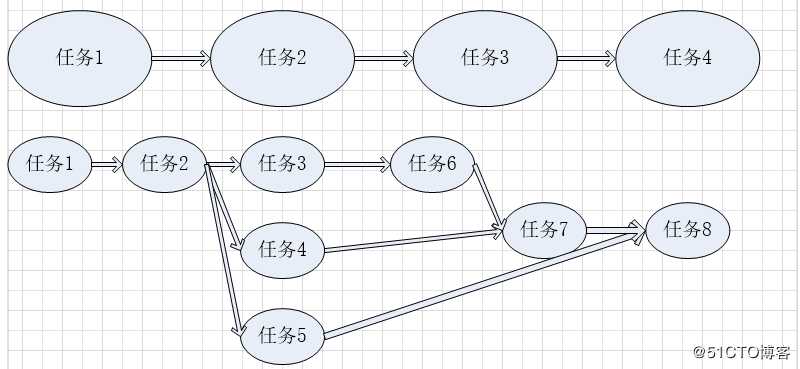
任务的执行过程中无非是串行和并行的问题,但串行的效率可能太低。
任务处理和任务流是没有关系的,任务的编排和任务分配不同
2 如何设计一个有向无环图(DAG)
1 有向无环图 directed acyclic graph (DAG)
无环路的有向图
假设有下面几种情况
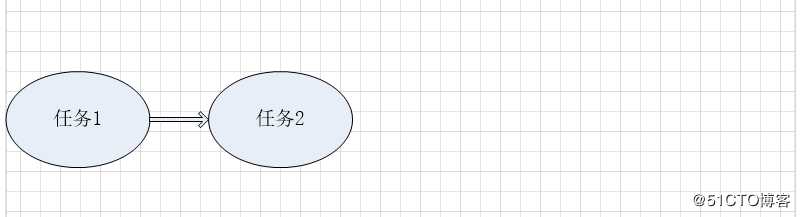
两个任务,任务本身就是顶点,任务先后执行
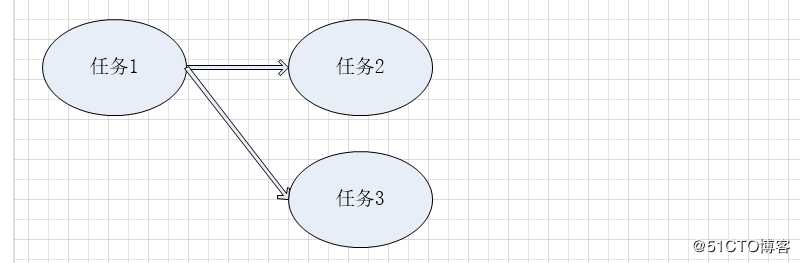
三个任务。任务1执行完成后,才能分别执行任务2和任务3
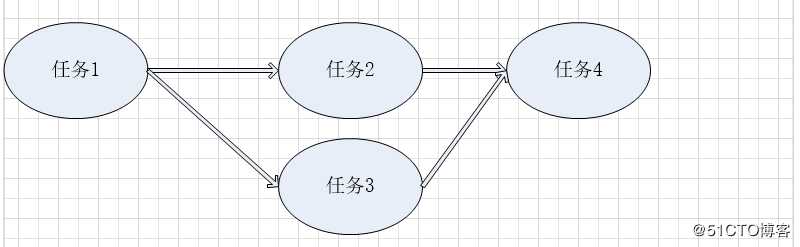
四个任务,执行任务1完成后,才能分别执行任务2和任务3,最后执行任务4.执行任务4 的时机应该是任务2 and 任务3
可以看到任务的执行过程就是流程的设定(pipeline),所以要设计一个流程系统来跑任务
2 起点和终点选择
1 入度为0的顶点就是起始的点
DAG 可以有多个起始点
我们的系统约定有且只有一个起始点终点的判断
出度为0的顶点,pipeline执行结束
pipeline可能有多个终点
3 环路预防
pipeline设计的过程中应当注意避免出现环路,因为出现环路就不是DAG了
自环检查,弧头指向顶点自身
多顶点构成环路的检测
环路检测必须实现,否则当定义好的流程执行起来,有可能进入环路后,永远执行不能终止。
3 schema 元数据表设计
使用数据库表的存储方式定义DAG
问题是如何使用数据库的表描述一个DAG
DAG也是图,是图就有顶点,边,所以可以设计2个表,顶点表,边表,边表用于描述一个图,为了存储多个图,定义一个图的表
1 图的定义(graph)
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 主键 |
| name | varchar | 非空,唯一,图的名称 |
| desc | varchar | 可为空,描述 |
2 顶点表定义 vertex
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 主键 |
| name | varchar | 非空,顶点的名称 |
| g_id | int | 外键,描述其属于哪个图 |
3 边表 edge
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 主键 |
| tail | int | 外键,弧尾顶点,顶点在vertex 表中必须存在 |
| head | int | 外键,弧头顶点,定在在vertex表中必须存在 |
| g_id | int | 外键,描述边属于哪一个图 |
通过弧尾,弧头顶点来描述有向边
4 具体关系如下
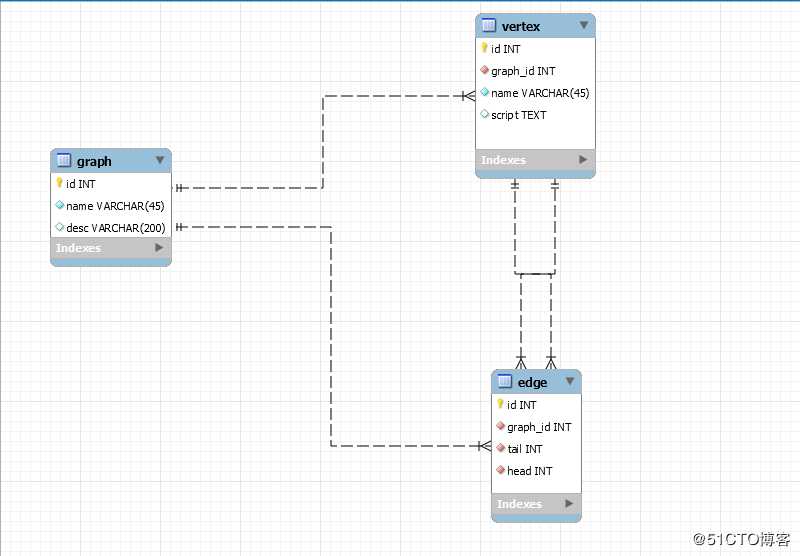
其中,graph表中主要是流水线的名称,id和描述,顶点表(vertex)中主要包含顶点名称,顶点id及顶点所属的流水线,因为顶点必须和流水线之间建立关系,script 表示顶点要执行的脚本,及流水线要执行的脚本。
edge表中主要包括弧尾和弧头以及此顶点属于哪个表,用于描述流水线的执行顺序
4 script 的设计
1 设计思路
流程定义表中,任务的处理和描述
在任务调度系统中,任务的实现我们使用script脚本实现
方法一
supprocess 执行bash 脚本script
优点:简单,易行
缺点:要启动外部进程,bash 脚本表达能力较弱,难调试
方法二
嵌入其他语言的脚本,如lua语言
优点:不启动子进程,功能强大。
缺点:技术要求高,需要学习其他脚本语言。
2 python 中执行lua脚本
安装
pip install lupa #!/usr/bin/poython3.6
#conding:utf-8
from lupa import LuaRuntime
lua=LuaRuntime() #对其进行实例化处理
print (lua.eval(‘1+10‘)) #调用方法,执行基本的函数运算操作
def pythonc(n): # 定义python方法
import socket
print(‘socket‘,n)
return socket.gethostname()
# 定义lua 脚本函数,并传递两个值,一个是f,及函数,另一个则是常数
luafunc=lua.eval(‘‘‘
function(f,n)
return f,n
end
‘‘‘)
print (luafunc(pythonc(1),10)) #调用函数并打印
add=lua.eval(‘‘‘
function (x,y)
return x+y
end
‘‘‘)
print (add(10,20))
结果如下

5 执行条件(input)
1 概述
脚本在执行之前,可能需要提供一些参数,才能开始执行脚本
此处需要在顶点表vertex中增加input字段,用于存储需要传递的参数。
2 表字段设计
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 主键 |
| name | varchar | 非空,顶点的名称 |
| g_id | int | 外键,描述顶点属于哪一个图 |
| script | text | 可以为空,存储任务脚本 |
| input | text | 可以为空,存储json格式的输入参数定义 |
3 input 格式
定义如下,json 格式
{
"name1" : {
"type":"",
"required" : True
},
"name2" :{
"type" :"",
"requried": True,
"default" :1
}
}name 就是参数的名称,后面定义该参数的类型,是否是必选参数等等属性及默认属性,其可以定义多个参数
4 作用
进入某个节点的时候,就必须满足条件,提供足够的参数
如果提供的参数满足要求,就进入节点,否则一直等待到参数满足
如果满足了,才能去执行script
input 就是一个约束的定义
交互:
input 可以不交互,缺省值为自动
6 任务执行
1 概述
当流程走到某一个顶点的时候,读取任务及脚本,执行这个脚本
2 手动执行和自动执行
1 手动执行
流程走到这个顶点等待用户操作,需要用户手动干预,
如由用户选择下一个执行顶点
如下一个顶点的任务需要一些配置参数,等待用户输入后才能进行下一步
2 自动执行
自动填写input,如使用缺省值,来满足用户为交互式填写的时候自动补全数据,脚本执行后,自动跳转到下一个节点,当然这个所谓的自动,程序不会智能的选择路径,需要提前指定好,执行完脚本,就可以跳转到下一个顶点了。
7 任务流转的设计
1 概述
当流程走到某一个顶点的时候,读取任务即脚本,或手动执行,或自动执行
2 流转分类
手动执行,需要人工选择下一个顶点,可以提供可视化界面供用户方便选择,
自动执行,就需要在信息中提供下一个节点的信息,供程序自动完成
那么,如何区分一个顶点是否自动执行
如果vertex表中的script字段修改为json.
如果next 不存在,则不能自动执行,需要手动操作
如果next存在,则程序自动跳转
3 消息格式
{
"script" :"echo test"
}
{
"script" :"echo test",
"next" : ‘B‘ # 填写下一跳为顶点名称
}
{
"script" : "echo test",
"next" : 2 # 填写下一跳为顶点id
}
为了方便用户,next可以提供2种类型的参数:
1 int 表示vertex的id
2 str 表示使用vertex的name,但是是同一个graph id, 同一个DAG的定义中名字不能冲突,所以可以用。
8 流程结束
如果一个顶点的出度为0,则此节点为终点。
如何判断出度为0.
在edge表中,使用当前节点的顶点id作为弧尾,找不到弧头h的任何记录。
9 执行引擎之pipeline 设计
1 概述
前面的设计仅仅是流程DAG定义,流程真正执行的时候需要记录执行这个流程的任务流的数据,
2 表pipeline
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 主键 |
| g_id | int | 外键,指明使用的是哪一个流程DAG定义 |
| current | int | 外键,顶点id,表示当前走到哪一个节点 |
这个表以后还要添加其他字段,存储一些附加信息。如谁加入的流程,执行时间等。
起点的选择,通过查询edge表来确定起点位置,当入度为0的点则是起点,通过顶点表和边表来进行处理
一个pipeline应该指向哪一个DAG,并选择DAG的起点,因为DAG 可能存在多个起点,即入度为0的顶点,需要指定,然后把这些信息记录在pipeline表中,current为起点顶点的id,提取current 顶点的input信息,用户输入满足了,才能执行script脚本
不管是手动执行还是自动执行,如果到了下一个节点,需要修改current字段的值,
任务流执行完毕,修改最后一个节点的状态为完成
3 举例
当前节点任务是打包,调用maven命令执行打包,先要提取inout,要求用户输入ip地址,输出目录等信息。然后才能执行打包脚本。
10 执行引擎历史轨迹设计
1 概述
pipeline表只能看到有哪些流正在运行,但是究竟走了DAG中的那些节点,不清楚,执行节点前输入了那些参数也是不清楚的
如何查询,回溯当前的pipeline的运行轨迹
2 track 表
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 主键 |
| p_id | int | 外键,哪一个流程的历史 |
| v_idint | 外键,顶点的ID,经历过的历史节点 | |
| input | text | 可以为空,输入的参数值 |
| output | text | 可以为空,任务的输出 |
3 状态设计
在pipeline表,track表中增加state字段,用于描述在某个节点上执行的状态,是等待中,还是正在运行,还是成功或者失败,还是执行完毕。
STATE_WAITING=0
STATE_RUNNING=1
STATE_SUCCEED=2
STATE_FAILED=3
STATE_FINISH=4
11 最终设计模型
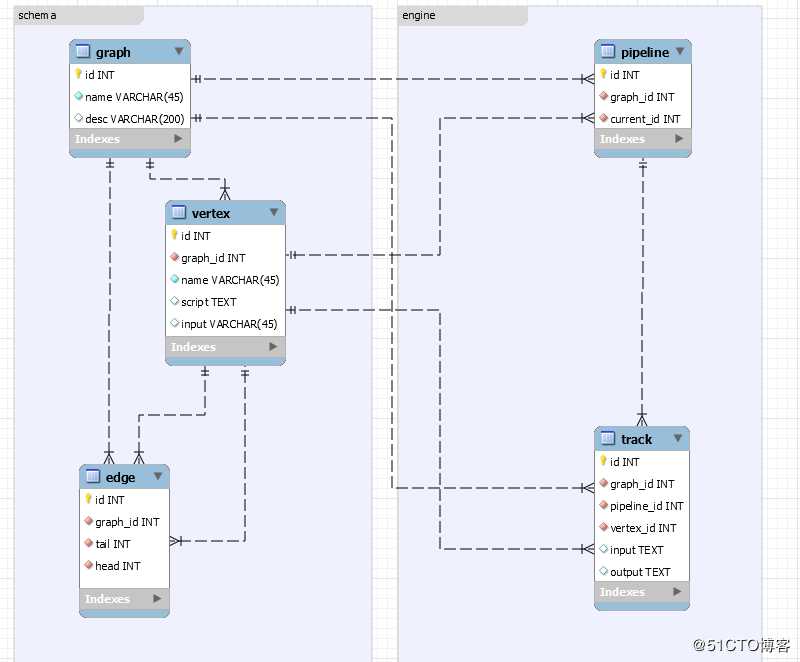
左边主要针对的是基础设计,右边主要针对的是引擎层面的设计,流程看似一样,但其实际是不同的
12 DAG 检测
1 DFS 算法
DFS ( depth first search)深度优先遍历,递归算法
需要改进算法适用于有向图
不能直接检测有向图是否有环
2 拓扑排序算法
拓扑排序就是把有向图中的顶点以线性方式排序,如果有弧<u,b>,则最后线性排序的结果,顶点u总是在顶点b的前面
一个有向图能被拓扑排序的充要条件是: 它必须是DAG
3 kahr算法
1 选择一个入度为0的顶点并输出它
2 删除以此顶点为弧尾的弧重复上面2步,直到输出全部顶点为止,或者图中不存在入度为0的顶点为止。
实例如下
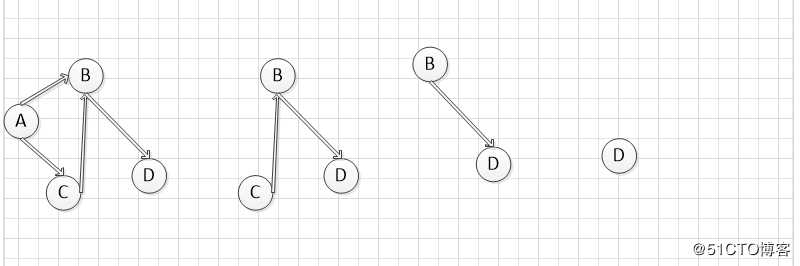
第一步,找到入度为0的点A,然后删除A和以A为弧尾的边,第二步,找到入度为0的C,删除顶点C和以C为弧尾的边,第三步,找到B,删除顶点B,并删除以B为弧尾的边,最后,删除入度为0的顶点D
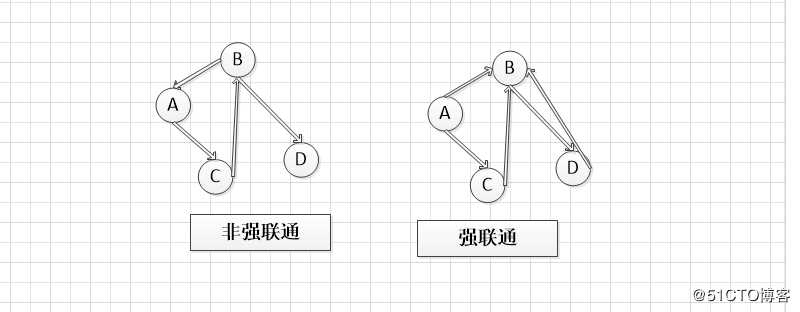
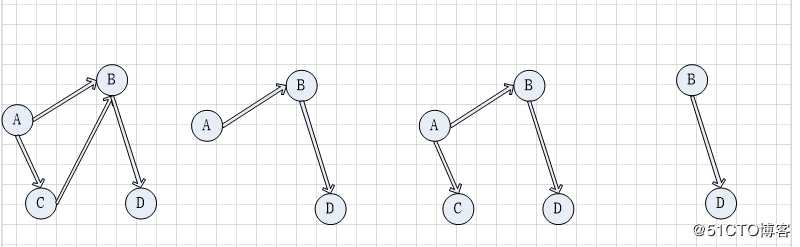
上面2个图都不是DAG,左图一个环,右图2个环
这2个图都找不到入度为0的起始点,都不是DAG
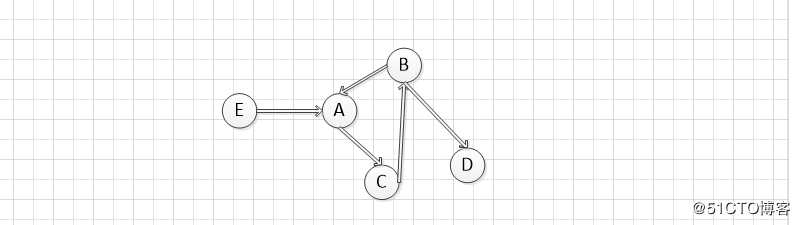
上图中虽然能找到入度为0的顶点,但是移除它和关联的边,剩下的顶点找不到入度为0的顶点,其不是DAG
四 项目配置流程系统
1 概述
本项目使用service层和module层进行配置和处理工作,其中,service层主要处理相关数据,而module层的作用则是创建和操作数据库配置
2 项目创建
1 虚拟目录创建
mkdir pipeline
cd pipeline/
pyenv virtualenv 3.5.3 pipe
pyenv local pipe2 数据库相关配置
create database pipeline charset utf8mb4;
grant all on pipeline.* to pipe@localhost identified by ‘pipe‘;
flush privileges;
2 model层创建
1 概述
数据持久化最终的结果是需要通过关系数据库的表达来实现的
2 配置文件创建
创建config文件,用于存储数据库配置信息
#!/usr/bin/poython3.6
#conding:utf-8
USERNAME="pipe"
PASSWORD="pipe"
DBIP="localhost"
DBPORT=3306
DBNAME="pipeline"
PARAMS="charset=utf8mb4"
URL="mysql+pymysql://{}:{}@{}:{}/{}?{}".format(USERNAME,PASSWORD,DBIP,DBPORT,DBNAME,PARAMS)
DATABASE_DEBUG=True3 创建模型模板
用于存储和封装数据类
添加插件sqlachemy 和 pymysql
pip install sqlalchemy pymysqlmodel.py 内容如下
#!/usr/local/bin/python3.6
#coding:utf-8
# @Time : 2019/11/27 11:18
# @Author : ZhangBing
# @Email : 18829272841@163.com
# @File : model.py
# @Software: PyCharm
from pipeline.config import URL,DATABASE_DEBUG
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String,ForeignKey,Text
from sqlalchemy.orm import relationship
from sqlalchemy.orm import sessionmaker
STATE_WAITING=0
STATE_RUNNING=1
STATE_SUCCEED=2
STATE_FAILED=3
STATE_FINISH=4
Base=declarative_base()
# 创建图,用于存储pipeline 流水
class Graph(Base):
__tablename__=‘graph‘
id=Column(Integer,primary_key=True,autoincrement=True)
name=Column(String(48),nullable=False)
desc=Column(String(128))
# 创建relationship关系图,用于配置,此处的含义是可以使用此关系来处理查看此pipe下的顶点和边的信息
vertexs=relationship("Vertex")
edges=relationship("Edge")
# 创建顶点表,用于存储顶点信息
class Vertex(Base):
__tablename__=‘vertex‘
id=Column(Integer,primary_key=True,autoincrement=True)
name=Column(String(48),nullable=False)
graph_id=Column(Integer,ForeignKey(‘graph.id‘)) # 配置外键,用于
input=Column(String(128),nullable=True)
script=Column(Text,nullable=True)
graph=relationship("Graph")
# 从顶点看边,一个顶点对应两个边,肯定会出现问题,因此此处使用此方式来指定到对应的边,此处必须使用引号,否则会导致报错
tails=relationship("Edge",foreign_keys="[Edge.tail]")
heads=relationship("Edge",foreign_keys="Edge.head")
# 创建边表,用户存储边的相关信息
class Edge(Base):
__tablename__=‘edge‘
id=Column(Integer,primary_key=True,autoincrement=True)
tail=Column(Integer,ForeignKey(‘vertex.id‘),nullable=False)
head=Column(Integer,ForeignKey(‘vertex.id‘),nullable=False)
graph_id=Column(Integer,ForeignKey(‘graph.id‘),nullable=False)
# 用于记录当前流水线执行到那块了,自然需要节点信息
# 此处用于查看流水线的执行情况,如再那个流水线的那个节点。执行的结果状态如何
class Pipeline(Base):
__tablename__=‘pipeline‘
id=Column(Integer,primary_key=True,autoincrement=True)
current=Column(Integer,ForeignKey(‘vertex.id‘))
graph_id = Column(Integer, ForeignKey(‘graph.id‘))
state=Column(Integer,nullable=False,default=STATE_WAITING)
vertex=relationship("Vertex")
# 此处用于创建记录表,此表必须和pipeline进行联系,并和顶点表俩西,获取对应的顶点的最终执行信息
class Track(Base):
__tablename__=‘track‘
id = Column(Integer, primary_key=True, autoincrement=True)
pipeline_id=Column(Integer,ForeignKey(‘pipeline.id‘))
vertex_id=Column(Integer,ForeignKey(‘vertex.id‘))
input=Column(Text,nullable=True)
output=Column(Text,nullable=True)
state=Column(Integer,nullable=False,default=STATE_WAITING) # 用于记录该节点是否执行任务成功
vertex=relationship("Vertex")
pipeline=relationship("Pipeline")
# 此处用于创建存储引擎
class DBcreate:
def __init__(self):
# 初始化时创建引擎
self.__engine=None
self.__session=None
self.flag=False
def db_init(self,DB_URL,DATABASE_DEBUG):
if not self.flag:
self.__engine = create_engine(DB_URL, echo=DATABASE_DEBUG)
# 创建会话
self.__session = sessionmaker(bind=self.__engine)()
self.flag = True
return self
@property
def session(self):
if not self.flag:
raise ArithmeticError("Not initialized")
return self.__session
@property
def engine(self):
if not self.flag:
raise ArithmeticError("Not initialized")
return self.__engine
def db_create(self): # 创建表
Base.metadata.create_all(self.__engine)
def db_delete(self): # 删除表
Base.metadata.drop_all(self.__engine)
db=DBcreate().db_init(URL,DATABASE_DEBUG) # 通过此处的实例化实现了向外创建的目的
db.db_create() # 创建表
if __name__ == "__main__":
pass运行结果如下

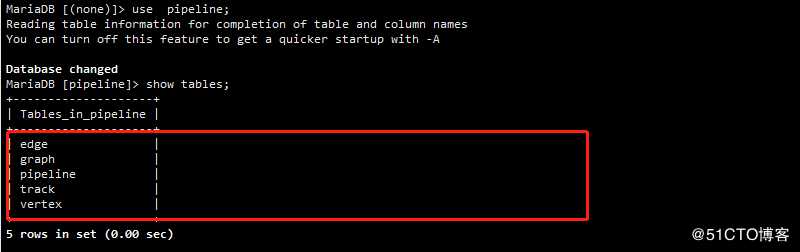
创建数据库如下
2 service 层处理
1 需求
1 定义DAG,及就是schema定义
2 执行某一个DAG流程
2 问题
DAG 是否允许修改
可以这样考虑。如果DAG 定义好还未使用,可以进行修改操作,一旦使用过,则不能修改,因此便需要在图graph表中增加一个字段用于区分是否是执行过的pipeline
3 DAG 定义
#!/usr/bin/poython3.6
#conding:utf-8
from .model import db
from .model import Graph,Vertex,Edge
from .model import Pipeline,Track
# 创建 DAG
def create_graph(name,desc=None): # 此处用于创建图表,主要需要传递的参数是name和desc 描述信息
g=Graph()
g.name=name
g.desc=desc
db.session.add(g)
try:
db.session.commit()
return g
except:
db.session.rollback()
# 创建顶点表
def add_vertex(graph:Graph,name,input=None,script=None):
v=Vertex()
v.graph_id=graph.id
v.name=name
v.script=script
v.input=input
db.session.add(v)
try:
db.session.commit()
return v
except:
db.session.rollback()
# 创建边表,用存储边的数据信息
def add_edge(graph:Graph,tail:Vertex,head:Vertex):
e=Edge()
e.graph_id=graph.id
e.tail=tail.id
e.head=head.id
db.session.add(e)
try:
db.session.commit()
return e
except:
db.session.rollback()
def del_vertex(id): # 通过顶点表的id来删除相关的信息,需要删除顶点和顶点对应的边的信息
query=db.session.query(Vertex).filter(Vertex.id==id)
v=query.first()
if v: # 找到顶点。删除相关的边,然后删除顶点
try:
db.session.query(Edge).filter((Edge.tail==v.id) | Edge.head==v.id).delete() # 删除对应的边
query.delete() # 删除顶点
db.session.commit() # 提交。若失败,则回滚
except:
db.session.rollback()
return v使用装饰器处理上述提交问题,避免繁琐,创建util 文件,用于处理数据库数据的提交和回撤问题
#!/usr/bin/poython3.6
#conding:utf-8
from pipeline.model import db
from functools import wraps
def transactional(fn):
@wraps(fn)
def __wapper(*args,**kwargs):
ret=fn(*args,**kwargs)
try:
db.session.commit()
return ret
except:
db.session.rollback()
return __wapper
if __name__ == "__main__":
pass4 service 层修改结果如下
#!/usr/bin/poython3.6
#conding:utf-8
from .model import db
from .model import Graph,Vertex,Edge
from .model import Pipeline,Track
from util import transactional
# 创建 DAG
@transactional
def create_graph(name,desc=None): # 此处用于创建图表,主要需要传递的参数是name和desc 描述信息
g=Graph()
g.name=name
g.desc=desc
db.session.add(g)
# 创建顶点表
return g
@transactional
def add_vertex(graph:Graph,name,input=None,script=None):
v=Vertex()
v.graph_id=graph.id
v.name=name
v.script=script
v.input=input
db.session.add(v)
return v
# 创建边表,用存储边的数据信息
@transactional
def add_edge(graph:Graph,tail:Vertex,head:Vertex):
e=Edge()
e.graph_id=graph.id
e.tail=tail
e.head=head
db.session.add(e)
return e
def del_vertex(id): # 通过顶点表的id来删除相关的信息,需要删除顶点和顶点对应的边的信息
query=db.session.query(Vertex).filter(Vertex.id==id)
v=query.first()
if v: # 找到顶点。删除相关的边,然后删除顶点
try:
db.session.query(Edge).filter((Edge.tail==v.id) | Edge.head==v.id).delete() # 删除对应的边
query.delete() # 删除顶点
db.session.commit() # 提交。若失败,则回滚
except:
db.session.rollback()
return v3 DAG 验证和测试数据处理
1 测试数据
测试数据函数,暂时放置在service.py中进行处理
```
def test_create_dag():
try:
g=create_graph(‘test1‘) # 此处成功返回一个graph对象
# 增加节点
input=‘‘‘
{
"ip" :{
"type" :"str",
"required" :"true",
"default" : 192.168.1.200
}
}
‘‘‘
script={
"script" : "echo test1.A",
‘next‘ : ‘B‘
}
# 此处可以设置为为了用户方面,next可以设置接收两种类型,数字表示顶点的id,字符串表示用一个DAG中的该名称的顶点,其不能重复
a=add_vertex(g,‘A‘,None,json.dumps(script)) # 对数据进行处理
b=add_vertex(g,‘B‘,None,‘echo B‘)
c=add_vertex(g,‘C‘,None,‘echo C‘)
d=add_vertex(g,‘D‘,None,‘echo D‘)
# 增加边
ab=add_edge(g,a,b)
ac=add_edge(g,a,c)
cb=add_edge(g,c,b)
bd=add_edge(g,b,d)
# 创建环路
g=create_graph(‘test2‘) # 环路
# 增加顶点
a = add_vertex(g,‘A‘,None,‘echo A‘)
b = add_vertex(g, ‘B‘, None, ‘echo B‘)
c = add_vertex(g, ‘C‘, None, ‘echo C‘)
d = add_vertex(g, ‘D‘, None, ‘echo D‘)
# 增加边。abc之间环路
ba=add_edge(g,b,a)
ac=add_edge(g,a,c)
cb=add_edge(g,c,b)
bd=add_edge(g,b,d)
# 创建DAG
g=create_graph(‘test3‘) # 多个顶点
# 增加顶点
a = add_vertex(g, ‘A‘, None, ‘echo A‘)
b = add_vertex(g, ‘B‘, None, ‘echo B‘)
c = add_vertex(g, ‘C‘, None, ‘echo C‘)
d = add_vertex(g, ‘D‘, None, ‘echo D‘)
# 增加边
ba=add_edge(g,b,a)
ac=add_edge(g,a,c)
bc=add_edge(g,b,c)
bd=add_edge(g,b,d)
# 多起点处理方式
g = create_graph(‘test4‘) # 多个顶点
# 增加顶点
a = add_vertex(g, ‘A‘, None, ‘echo A‘)
b = add_vertex(g, ‘B‘, None, ‘echo B‘)
c = add_vertex(g, ‘C‘, None, ‘echo C‘)
d = add_vertex(g, ‘D‘, None, ‘echo D‘)
# 增加边
ab = add_edge(g, a, b)
ac = add_edge(g, a, c)
cb = add_edge(g, c, b)
db = add_edge(g, d, b)
except Exception as e:
print (e)
```2 执行写入测试数据
创建app文件
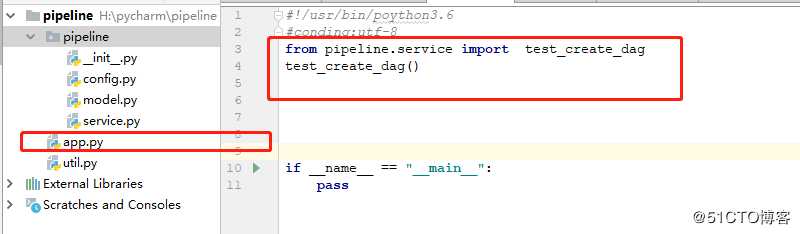
执行结果如下
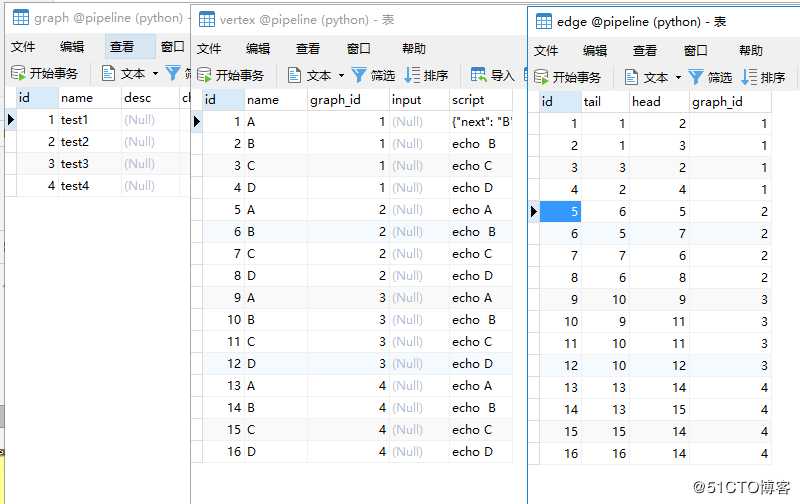
3 DAG 验证概述
当增加一个DAG定义后,或者修改了DAG定义后,就需要对DAG 进行验证,判断是否是一个DAG图,如何知道写入的数据库的数据是有效的,则需要通过在graph表中增加一个checked字段,用于判断是否是通过验证的,在以后的创建流程操作中,若检测到其字段为0时,则表示其未通过DAG 验证
注意:如果有一个流程使用了这个DAG,其将不被允许修改没了实现这个功能,且不要每一次都查询一下这个DAG是否被使用,可以在graph表中提供一个字段sealed,一旦设置就不能修改和删除,表示有人使用了,
在DAG定义后,修改后,就立即进行DAG检验,这样使用的时候就不用每次都检验。
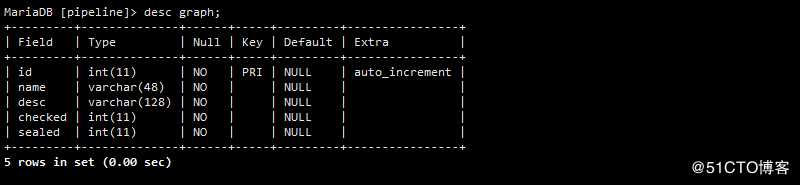
4 DAG 设计表结构结果
| 字段名 | 类型 | 说明 |
|---|---|---|
| id | int | 主键 |
| name | varchar | 非空,唯一,图的名称 |
| desc | varchar | 可为空,描述信息 |
| checked | int | 流程检验数据 |
| sealed | int | 不可为空,默认为0,0表示未使用,1表示已经有执行流程使用了,被封闭不可修改 |
结果如下
class Graph(Base):
__tablename__=‘graph‘
id=Column(Integer,primary_key=True,autoincrement=True)
name=Column(String(48),nullable=False)
desc=Column(String(128),nullable=False)
checked=Column(Integer,nullable=False,default=0)
sealed=Column(Integer,nullable=False,default=0)
# 创建relationship关系图,用于配置,此处的含义是可以使用此关系来处理查看此pipe下的顶点和边的信息
vertexs=relationship("Vertex")
edges=relationship("Edge")重新处理表结构,结果如下
查询所有入度为0的顶点
SELECT vertex.* FROM vertex LEFT JOIN edge on vertex.id=edge.head WHERE vertex.graph_id=1 AND edge.head is NULL 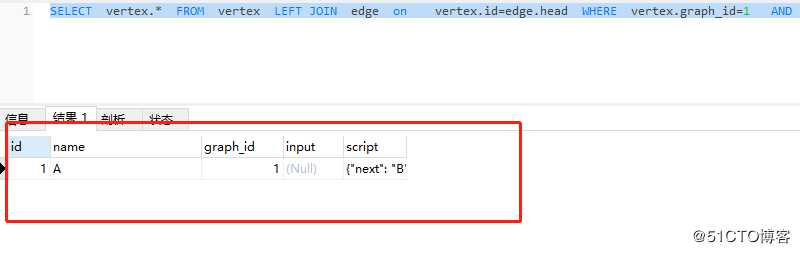
采用做链接找到edge中的null的方式,找到入度为0的顶点。
但这种方式找到的不适合进行验证,因为第一批入度为0的顶点找到之后,还需要再次查询,找到第二批顶点。其可以将所有的顶点,边都先查询一遍,然后再客户端数据库中进行相关的处理
5 函数创建
在service.py中进行创建此函数
def check_graph(graph:Graph):
query=db.session.query(Vertex).filter(Vertex.graph_id==graph.id)
vertexs=[vertex.id for vertex in query] # 获取顶点列表
query=db.session.query(Edge).filter(Edge.graph_id==graph.id)
edges=[(edge.tail,edge.head) for edge in query ] # 此处获取边的列表
while True:
vis=[] #存放索引,
for i,v in enumerate(vertexs): # 此处需要对顶点表中的每一个顶点和边表中的head进行匹配
for _,h in edges:
if h==v: # 此处的v表示顶点的id,此处的h表示head及弧头的数据,若相等,则表示其顶点有弧头,则表示入度不为0,此处判断失败
break
else: # 此处表示其顶点表中的和边表中head的没有匹配的情况,及入度为0的顶点
ejs=[]
for j,(t,_) in enumerate(edges): # 此处是处理弧尾的情况,
if t==v: # 此处是弧尾和顶点相等的情况,则将其加入到对应的ejs中,弧尾相等。则表示其可以形成边的关系
ejs.append(j) # 增加其顶点到对应的边关系中
vis.append(i) # 增加其边的索引到列表汇总
for j in reversed(ejs): # 删除列表中的边对应的索引。及删除和入度为0的顶点对应的边
edges.pop(j)
break
else: # 若遍历所有都没有找到入度为0的顶点,表明其本身就有环
return False
for i in vis:
vertexs.pop(i)
if len(vertexs) + len(edges) ==0: #此处为0,表示删除完成,则为DAG
try:
graph=db.session.query(Graph).filter(Graph.id==graph.id).first()
if graph:
graph.checked=1 # 修改和更新状态
db.session.add(graph)
db.session.commit()
except Exception as e:
db.session.rollback()
raise e
执行在app中进行。如下
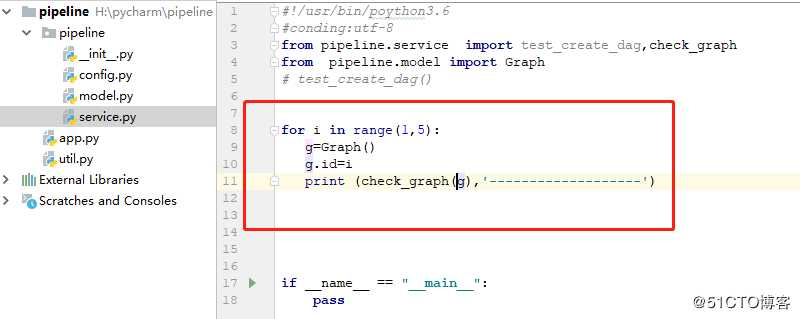
结果如下

4 流程的启动和inut 验证和执行器
1 执行引擎
起点
开启一个流程的时候,需要在界面中选择一个checke为1的DAG,选择一个顶点,顶点的选择,使用前面的左连接sql语句可以列出当前DAG中入度为0的节点作为初始顶点,供用户选择一个作为起点
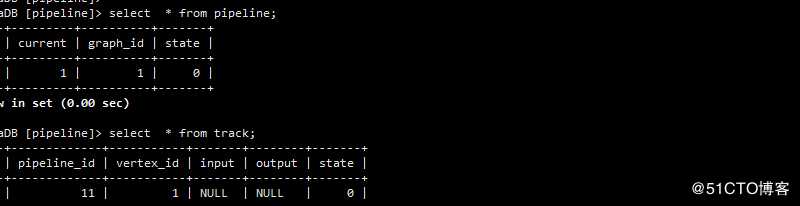
将起点信息写入pipeline表,Track表,状态State都是WAITING
pipeline 表示正在执行的节点
track记录历史信息,当前还没有input 具体值的信息
2 执行引擎代码如下
def start(graph:Graph,vertex:Vertex,params=None):
# 判断流程是否存在,且checked为1的则通过检验
g=db.session.query(Graph).filter(Graph.id==graph.id).filter(Graph.checked==1).first()
if not g:
return
v=db.session.query(Vertex).filter((Vertex.id==vertex.id) & (Vertex.graph_id==graph.id)).first()
if not v:
return
# 写入pipeline 表
p=Pipeline()
p.current=v.id
p.graph_id=g.id
p.state=STATE_WAITING
db.session.add(p)
try:
db.session.commit()
except:
db.session.rollback()
t=Track()
t.pipeline_id=p.id
t.vertex_id=v.id
t.state=STATE_WAITING
db.session.add(t)
try:
db.session.commit()
except:
db.session.rollback()
if g.sealed==0:
g.sealed=1
db.session.add(g)
return p
测试如下
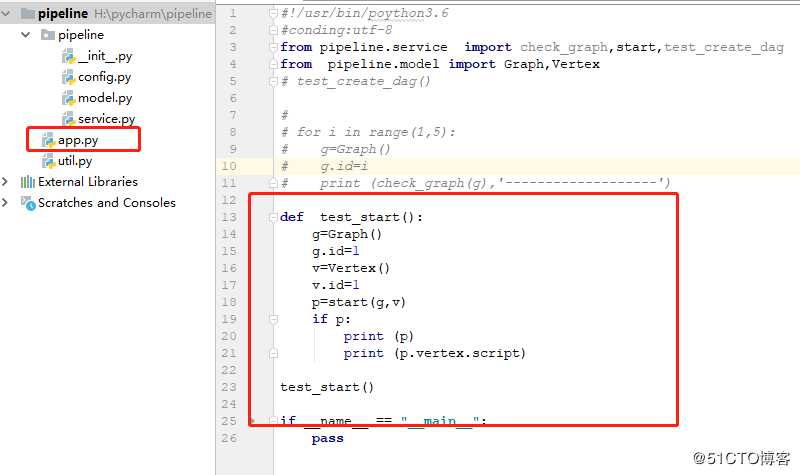
def test_start():
g=Graph()
g.id=1
v=Vertex()
v.id=1
p=start(g,v)
if p:
print (p)
print (p.vertex.script)
test_start()
结果如下
3 input 验证
开启一个流程后,起点可能会设置input,这时候就需要有一个界面,让用户填写参数,这是一个交互的过程,也可以实现为自动填写参数
提取起点的input参数并进行验证,验证通过,将输入值,保存到字典中,将值存入track表,将字典中的input值交给执行器完成,此处功能在mschedule项目中已经实现,此处不再累赘
4 执行器
使用Input获得字典,对script字段中的脚本进行替换。若是空字典,就直接执行脚本,启动线程,使用subprocess的Popen开启子进程执行,返回的结果保存到track的output中,判断成功失败,如果成功,则置状态为成功,继续,若失败,则置状态为失败,流程停止
### 执行器配置
from subprocess import Popen,PIPE
def execute(script,timeout=None):
proc=Popen(script,shell=True,stdout=PIPE)
code=proc.wait(timeout)
txt=proc.stdout.read()
return code,txt
5 流转
1 概述
设想一种自动化执行流程,先不考虑input的交互步骤,假设没有input环节
1 用户选择了起点之后,如何开始执行脚本?
如果用户提交了一个起点后,start函数开始执行,就一直执行到最后一个节点,这个函数才退出,可以,但其存在问题
也就是用户提交起点后,起点脚本执行是需要时间的,这时候异步执行可能是一个好的方式,开启线程,专门负责从数据库的pipeline表中读取所有WAITING的节点,执行script,获取返回结果
2 如何流转
脚本执行成功,需要流转到下一个节点
2.1 终点
如果本节点的出度为0,就是终点了,将pipeline,track中的字段置位完成2.2 自动选择
在脚本json中执行了next,把pipeline中current字段更新为最新的顶点id,状态为等待,track表中的原来的顶点id的状态修改为成功,新增一条跟踪顶点id记录,状态是等待。
2 异步执行
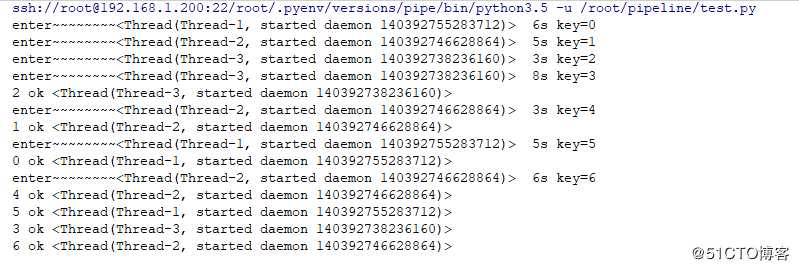
此处具体代码参考如下
#!/usr/bin/poython3.6
#conding:utf-8
from concurrent.futures import ThreadPoolExecutor,as_completed
import random
import threading
def test_fun(s,key):
print ("enter~~~~~~~~{} {}s key={}".format(threading.current_thread(),s,key))
threading.Event().wait(s)
return "ok {}".format(threading.current_thread())
with ThreadPoolExecutor(max_workers=3) as executor:
futures={executor.submit(test_fun,random.randint(1,8),i):i for i in range(7)}
for future in as_completed(futures):
id=futures[future]
try:
print (id,future.result())
except Exception as e:
print (id,‘failed‘)
结果如下
3 流转代码如下
from concurrent.futures import ThreadPoolExecutor,as_completed
MAX_POOL_SIZE=5
executor=ThreadPoolExecutor(max_workers=MAX_POOL_SIZE)
def iter_pipelines():# 此处可修改成yield from
query=db.session.query(Pipeline).filter(Pipeline.state==STATE_WAITING)
pipelines= query.all()
for pipeline in pipelines:
yield pipeline
#流转
def shift():
futures={}
for pipeline in iter_pipelines():
s=json.loads(pipeline.vertex.script) # 脚本的处理
script=s[‘script‘] # 拿到脚本
f=executor.submit(execute,script) # 送入函数和对应的参数
futures[f]=pipeline,s
for f in as_completed(futures):
p,s=futures[f] # 遍历相关对象
try:
code,txt=f.result()
print (code,txt,p.current)
if code==0: # 基本正常,此处返回为0表示正常情况
t=db.session.query(Track).filter((Track.pipeline_id==p.id) & (Track.vertex_id==p.current())).one()
t.state=STATE_SUCCEED
t.out=txt
db.session.add(t)
if ‘next‘ in s: # 是否存在下一跳
n=s[‘next‘] # 获取下一跳
if type(n)==int: # 此处对应的是执行下一个节点id对应的服务
pass
else: # 此处是对应的next为name的情况
pass
p.current=next # 更新节点数据
p.state=STATE_WAITING # 下一个节点的状态应该是正常
db.session.add(p)
else: # 此处未进行处理,则需要通过外部点击的方式完成
p.state=STATE_SUCCEED
db.session.add(p)
else:
pass
except Exception as e:
print (e,‘!!!!!!!!!!!!!!‘)
以上是关于运维流程系统的主要内容,如果未能解决你的问题,请参考以下文章
VSCode自定义代码片段15——git命令操作一个完整流程