Docker入门一概念和安装
Posted lanrish
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Docker入门一概念和安装相关的知识,希望对你有一定的参考价值。
Docker入门一概念和安装
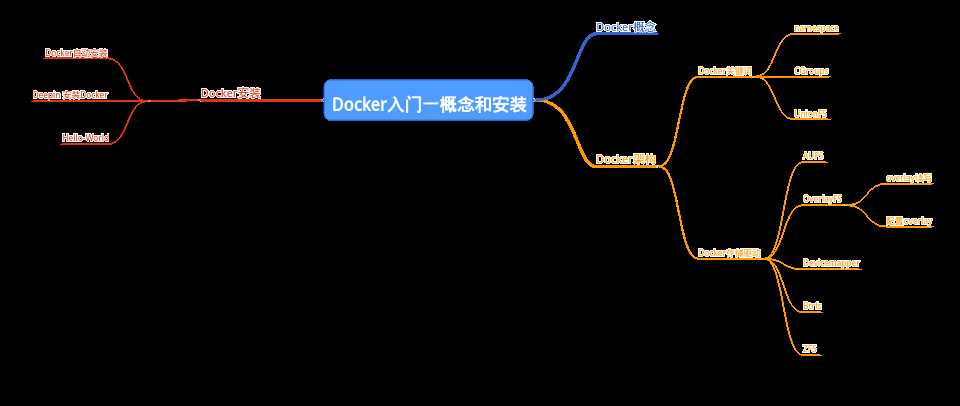
Docker概念
Docker 是一个基于 LXC 技术构建的容器引擎,基于 GO 语言开发,遵循 Apache2.0 协议开源。Docker 的发展得益于为使用者提供了更好的容器操作接口。包括一系列的容器,镜像,网络等管理工具,可以让用户简单的创建和使用容器。
核心理念:
Build once,Run anywhere.
核心关键词:
namespace, cgroups, union fs
Docker架构
Docker为C/S体系架构,主要分为3大组件:
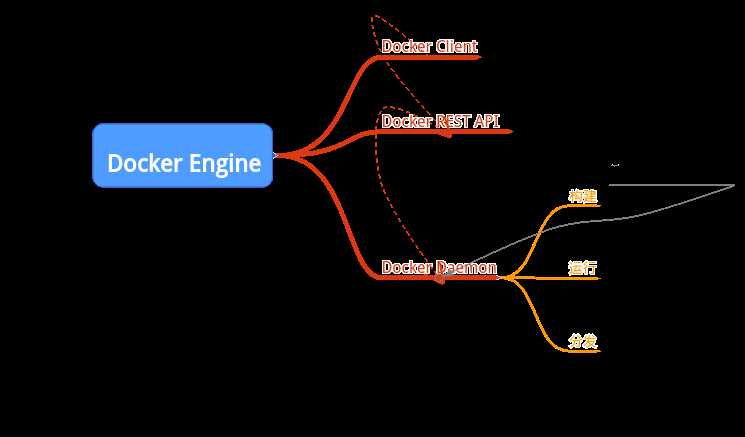
以下为Docker的运行架构图:

- Dockerd(daemon) : 用来监听Docker API请求和管理Docker对象(镜像,容器,网络,Volume)
- Client: 用来发送命令给dockerd
- Registry: 用来存储Docker镜像
- Images: 镜像为构建容器的只读文件系统层,image = readonly[bootfs+rootfs(Linux distributions)+software]
- Containers: 容器为镜像的可运行实例,容器的实质是
进程,该进程用于自己的root文件系统,网络,进程空间,用户id.
Docker关键词
namespace
命名空间为Linux Kernel的特性,实现了容器之间的资源隔离.
一般的硬件虚拟化方法给出的方法是 VM,而 LXC 给出的方法是 container,更细一点讲就是 kernel namespace。其中pid、net、ipc、mnt、uts、user等 namespace 将 container 的进程、网络、消息、文件系统、UTS("UNIX Time-sharing System") 和用户空间隔离开。
- pid namespace
不同用户的进程就是通过 pid namespace 隔离开的,且不同 namespace 中可以有相同 pid。所有的 LXC 进程在 docker 中的父进程为 docker 进程. - net namespace
有了 pid namespace, 每个 namespace 中的 pid 能够相互隔离,但是网络端口还是共享 host 的端口。网络隔离是通过 net namespace 实现的, 每个 net namespace 有独立的 network devices, IP addresses, IP routing tables, /proc/net 目录。这样每个 container 的网络就能隔离开来。docker 默认采用 veth 的方式将 container 中的虚拟网卡同 host 上的一个 docker bridge: docker0 连接在一起。 - ipc namespace
container 中进程交互还是采用 linux 常见的进程间交互方法 (interprocess communication - IPC), 包括常见的信号量、消息队列和共享内存。然而与VM 不同的是,container 的进程间交互实际上还是 host 上具有相同 pid namespace 中的进程间交互,因此需要在 IPC 资源申请时加入 namespace 信息 - 每个 IPC 资源有一个唯一的 32 位 ID。 - mnt namespace
类似 chroot,将一个进程放到一个特定的目录执行. - uts namespace
UTS("UNIX Time-sharing System") namespace 允许每个 container 拥有独立的 hostname 和 domain name, 使其在网络上可以被视作一个独立的节点而非 Host 上的一个进程 - user namespace
每个 container 可以有不同的 user 和 group id, 也就是说可以在 container 内部用 container 内部的用户执行程序而非 Host 上的用户。
CGroups
Linux namespace实现了独立的系统环境,但是内存大小,网络带宽,CPU,磁盘空间可以不受限制的使用,这时候就需要使用Linux cgroups来限制容器进程所使用的最大资源,达到资源控制的目的.
cgroups 实现了对资源的配额和度量。 cgroups 的使用非常简单,提供类似文件的接口,在 /cgroup 目录下新建一个文件夹即可新建一个 group,在此文件夹中新建 task 文件,并将 pid 写入该文件,即可实现对该进程的资源控制。
groups 可以限制 blkio、cpu、cpuacct、cpuset、devices、freezer、memory、net_cls、ns 九大子系统的资源,以下是每个子系统的详细说明:
blkio 这个子系统设置限制每个块设备的输入输出控制。例如: 磁盘,光盘以及 usb 等等。
cpu 这个子系统使用调度程序为 cgroup 任务提供 cpu 的访问。
cpuacct 产生 cgroup 任务的 cpu 资源报告。
cpuset 如果是多核心的 cpu,这个子系统会为 cgroup 任务分配单独的 cpu 和内存。
devices 允许或拒绝 cgroup 任务对设备的访问。
freezer 暂停和恢复 cgroup 任务。
memory 设置每个 cgroup 的内存限制以及产生内存资源报告。
net_cls 标记每个网络包以供 cgroup 方便使用。
ns 名称空间子系统。UnionFS
UnionFS,简单来说就是支持将不同物理位置的目录挂载到同一个虚拟文件系统,
典型的Linux启动:
bootfs + rootfs

一般流程为: bootfs(bootloader + kernel) => umount bootfs => mount rootfs
bootfs (boot file system) 主要包含 bootloader 和 kernel, bootloader 主要是引导加载 kernel, 当 boot 成功后 kernel 被加载到内存中后 bootfs 就被 umount 了. rootfs (root file system) 包含的就是典型 Linux 系统中的 /dev, /proc,/bin, /etc 等标准目录和文件。
不同Linux的发行版的主要区别在于: rootfs

典型的 Linux 在启动后,首先将 rootfs 设置为 readonly, 进行一系列检查, 然后将其切换为 "readwrite" 供用户使用。在 Docker 中,初始化时也是将 rootfs 以 readonly 方式加载并检查,然而接下来利用 union mount 的方式将一个 readwrite 文件系统挂载在 readonly 的 rootfs 之上,并且允许再次将下层的 FS(file system) 设定为 readonly 并且向上叠加, 这样一组 readonly 和一个 writeable 的结构构成一个 container 的运行时态, 每一个 FS 被称作一个 FS 层。

对readonly修改的文件和目录只会存在于上层的writeable层中,多个docker container共享readonly层.所以docker将readonly 的FS层称做"image", image 不保存用户状态,只用于模板、新建和复制使用.

上层的 image 依赖下层的 image,因此 Docker 中把下层的 image 称作父 image,没有父 image 的 image 称作 base image。因此想要从一个 image 启动一个 container,Docker 会先加载这个 image 和依赖的父 images 以及 base image,用户的进程运行在 writeable 的 layer 中。所有 parent image 中的数据信息以及 ID、网络和 lxc 管理的资源限制等具体 container 的配置,构成一个 Docker 概念上的 container。如下图:

通过DockerFile进行初始化的容器流程:
DockerFile:
FROM ubuntu:14.04
ADD run.sh /
VOLUME /data
CMD ["./run.sh"]- FROM ubuntu:14.04 设置基础镜像,此时会使用Ubuntu:14.04作为基础镜像.
- ADD run.sh / 将Dockerfile所在目录下的run.sh加至镜像的根目录,此时新一层的镜像只有一项内容,即根目录下的run.sh.
- VOLUME /data 设置镜像的存储,此VOLUME在容器内部的路径为/data。此时并未在新一层的镜像中添加任何文件,但是更新了镜像的json文件
- CMD [“./run.sh”] 设置镜像的默认执行入口,此命令同样不会在新建镜像中添加任何文件,仅仅在上一层镜像json文件的基础上更新新的镜像的json文件


图中的顶上两层,是Docker为Docker容器新建的内容,而这两层属于容器范畴。这两层分别为Docker容器的初始层(init Layer)与可读写层(Read-write Layer)
-
初始层: 大多是初始化容器环境时,与容器相关的环境信息,如容器主机名,主机host信息以及域名服务文件等。
-
读写层: Docker容器内的进程只对可读可写层拥有写权限,其它层进程而言都是只读的(Read-Only)。关于VOLUME以及容器的host、hostname、resolv.conf文件都会挂载到这里
Docker存储驱动
对于UnionFS,Docker可以兼容不同的文件系统,AUFS,Btrfs,OverlayFS,ZFS,Devicemapper共5种存储驱动.
为了实现UnionFS容器分层,隔离,共享Image的特点,这些存储驱动需要具备的特点:
- Copy on Write
如果每个container独自封装一个image,将会占用大量的磁盘空间,而Copy on Write,写时复制的技术,可以让多个容器基于一个Image来完成创建,进行写操作时,只需要将需要更改的部分从Image中复制到Container中进行更改,这样每个Container可以只保留自己增量更新的部分,节省磁盘空间. - Allocate-OnDemand
启动容器的时候,并不需要独占固定的磁盘空间,只有在写文件的时候,才分配给新空间,可以提高磁盘空间的利用率,减少空闲碎片.
AUFS
AUFS (AnotherUnionFS)是一种UnionFS,是文件级的存储驱动。
AUFS 支持为每一个成员目录 (类似 Git Branch) 设定 readonly、readwrite 和 whiteout-able 权限.
AUFS能透明覆盖一或多个现有文件系统的层状文件系统,把多层合并成文件系统的单层表示。简单来说就是支持将不同目录挂载到同一个虚拟文件下的文件系统。这种文件系统可以一层一层地叠加修改文件。无论底下有多少层都是只读的,只有最上层的文件系统是可写的。当需要修改一个文件时,AUFS创建该文件的一个副本,使用Copy on Write将文件从只读层复制到可写层进行修改,结果也保存在可写层。在Docker中,只读层就是image,可写层就是Container。

OverlayFS
OverlayFS类似AUFS文件系统,区别于AUFS:
- 更简单的设计
- 更快的速度
- 更广的兼容性(加入Linux内核主线)
Docker最新版本目前默认支持overlay2,比overlay在inode优化上更加高效,但是overlay2只支持Linux kernel4.0以上的版本.
OverlayFS分为两个目录:
- lowerdir: 镜像层
- upperdir: 容器层
这两个目录会统一对外展示为merged
注意镜像层和容器层是如何处理相同文件的: 容器层(upperdir)的文件是显性的,会隐藏镜像层(lowerdir)相同文件的存在。并在容器映射(merged)显示出统一视图

overlay驱动只能工作在两层之上,相比于AUFS,在多层镜像中有更好的查询性能,但是多层镜像没办法用多层OverlayFS实现,而不同镜像层使用不同的目录,上一层通过硬链接来引用下一层的镜像层.
创建一个新容器的流程: 镜像层lowerdir => 新目录容器层upperdir
overlay的镜像管理只工作在一个lower OverlayFS层之上,因此需要硬链接来实现多层镜像,但overlay2驱动原生地支持多层lower OverlayFS镜像(最多128层)。
因此overlay2驱动在合层相关的命令(如build和commit)中提供了更好的性能,与overlay驱动对比,减少了inode消耗.
overlay读写
- 读
- 读取lowerdir存在,upperdir中不存在的,需要从lowerdir中读取.
- 读取lowerdir和upperdir中都能在的,直接从upperdir中读取.
- 读取lowerdir不存在,upperdir存在的,直接从uppderdir中读取
- 写
- 容器第一次写一个镜像层存在的文件,先从lowerdir拷贝到upperdir,后续写操作只针对upperdir中的副本
删除文件和目录 删除文件时,容器会在镜像层创建一个whiteout文件,而镜像层的文件并没有删除,但是whiteout文件会隐藏它。容器中删除一个目录,容器层会创建一个不透明目录,这和whiteout文件隐藏镜像层的文件类似
重命名目录 只有在源文件和目的路径都在顶层容器层时,才允许执行rename操作,否则返回EXDEV。因此,应用需要能够处理EXDEV,并且回滚操作,执行替代的”拷贝和删除”策略
- 容器第一次写一个镜像层存在的文件,先从lowerdir拷贝到upperdir,后续写操作只针对upperdir中的副本
配置overlay
要求:
- overlay: Linux kernel > 3.18
- overlay2: linux kernel > 4.0
改变存储驱动会使你本地系统创建的所有容器都无法访问。在改变存储驱动前记得使用保存容器,然后推送到Docker hub或者私有仓库
1.停止Docker
[root@i4t ~]# systemctl stop docker
2.检查kernel版本,确定overlay的内核模块是否加载
[root@i4t ~]# uname -r
4.18.9-1.el7.elrepo.x86_64
[root@i4t ~]# lsmod |grep overlay
overlay 90112 0
#如果没有过滤出overlay模块,说明驱动没有加载,使用下面方法进行加载
[root@i4t ~]# modprobe overlay
3.使用verlay2存储来启动docker
#配置方法有2种
(1) 在Docker的启动配置文件中添加--storage-driver=overlay2的标志到DOCKER_OPTS中,这样可以持久化配置
(2) 或者将配置持久化到配置文件/etc/docker/daemon.json中
"storage-driver": "overlay2"
4.重启docker
5.执行docker info,查看Storage Driver是否为overlay
$ docker info
Client:
Debug Mode: false
Server:
Containers: 3
Running: 1
Paused: 0
Stopped: 2
Images: 6
Server Version: 19.03.5
Storage Driver: overlay2
Backing Filesystem: extfs
Supports d_type: true
Native Overlay Diff: true
Logging Driver: json-file
Cgroup Driver: cgroupfsDevicemapper
Device mapper是Linux内核2.6.9后支持的,提供的一种从逻辑设备到物理设备的映射框架机制,在该机制下,用户可以很方便的根据自己需要制定实现存储资源的管理策略。AUFS和OverlayFS都是文件级存储,而Devicemapper是块级存储,所有的操作都是直接对块进行操作,而不是文件。Devicemapper驱动会先在块设备上创建一个资源池,然后在资源池上创建一个带有文件系统的基本设备,所有镜像都是这个基本设备的快照,而容器则是镜像的快照。

所以在容器看到文件系统是资源池上基本设备的文件系统的快照,并不是为容器分配空间。
当要写入一个新文件时,容器的镜像内为其分配新的块并写入数据,这个叫做用时分配。
当要修改已有文件时,再使用Copy on Write为容器快照分配块空间,将要修改的数据复制到容器快照中的新快里再进行修改。
Devicemapper驱动默认会创建一个100G的文件包含镜像和容器,每个容器被限制在10G大小的卷内,可以自己配置调整
Btrfs
Btrfs被称为下一代写时复制的文件系统,并入Linux内核,也是文件级存储,但可以像Devicemapper直接操作底层设备。
Btrfs把文件系统的一部分配置为一个完整的子文件系统,称之为subvolume。采用subvolume,一个大的文件系统可以被划分多个子文件系统,这些子文件系统共享底层的设备空间,在需要磁盘空间时便从底层设备中分配,比如Btrfs支持动态添加设备。用户在系统中新增加硬盘后,可以使用Btrfs的命令将该设备添加到文件系统中。Btrfs把一个大的文件系统当成一个资源池,配置成多个完整的子文件系统,还可以往资源池里加新的子文件系统,而基础镜像则是子文件系统的快照,每个子镜像和容器都有自己的快照,这些快照都是subvolume的快照.
Docker的btrfs存储驱动将每个镜像层和容器存储在自己的btrfs子卷或快照中。镜像的基层存储为一个子卷而孩子层以及容器层存储为快照

镜像层和可写的容器层的信息存储在/var/lib/docker/btrfs/subvolumes/中。每个容器层或镜像层在这个目录下都有一个相应的目录。子卷具有copt-on-write的特性它们的空间由一个底层存储池来按需分配。它们也能被嵌套和快照.
当写入一个新文件时,在容器的快照里为其分配了一个新的数据块,文件写在这个空间里,叫做用时分配。而当修改已有文件时,使用CoW复制分配一个新的原始数据和快照,在这个新分配的空间变更数据,等结束后再进行相关的数据结构指引到新子文件系统和快照,原来的原始数据和快照没有指针指示,被覆盖。
详细介绍: Docker Btrfs
ZFS
ZFS文件系统是一个革命性的全新的文件系统,它从根本上改变了文件系统的管理方式,ZFS完全抛弃了”卷管理”,不再创建虚拟的卷,而是把所有设备集中到一个存储池中来进行管理,用”存储池”的概念来管理物理存储空间。过去,文件系统都是构建在物理设备之上的,并为数据提供冗余,”卷管理”的概念提供了一个单设备的映像。而ZFS创建在虚拟的,被称为”zpools”的存储池上。每个存储池由若干虚拟设备(virtual devices,vdevs)组成。这些虚拟设备可以是原始磁盘,也可以是一个RAID的镜像设备,或者是非标准RAID等级的多磁盘组。这样zpool上的文件系统可以使用这些虚拟设备的总存储容量。

每个正在运行的容器的统一文件系统都安装在/var/lib/docker/zfs/graph/中的安装点上.
在Docker中使用ZFS,首先从zpool里分配一个ZFS文件系统给镜像的基础层(Base layer),而其它镜像层则是这个ZFS文件系统快照的克隆,快照只是只读的,而克隆是可写的,当容器启动时则在镜像的最顶层生成一个可写层.

当启动一个container:
- 首先Image的Base layer作为ZFS文件系统位于Docker的主机上.
- 在该图中,通过获取基础层的ZFS快照,然后从该快照创建克隆来添加“Layer1”。 该克隆是可写的,并从zpool按需消耗空间。 快照是只读的,将基本层保留为不变的对象。
- 在该图中,容器的读写层是通过创建图像顶层(Layer1)的快照并从该快照创建副本来创建的。
- 当容器修改其可写层的内容时,将为已更改的块分配空间。 默认情况下,这些块为128k。

一般来说,overlay2驱动更快一些,几乎肯定比AUFS和devicemapper更快,在某些情况下,可能比Btrfs也快。在使用overlay2存储驱动时,需要注意以下几点
- Page Caching 页缓存
OverlayFS支持页缓存,也就是说如果多个容器访问同一个文件,可以共享一个或多个页缓存选项。这使得overlay2驱动高效地利用了内存,是Pass平台或者高密度场景很好的选择 - copy_up 和AUFS一样,在容器第一次修改文件时,OverlayFS都需要执行copy_up操作,这会给操作带来一些延迟————尤其这个拷贝很大的文件时,不过一旦文件已经执行了这个向上拷贝的操作后,所有后续对这个文件的操作都只针对这份容器层的拷贝而已
- Inode limits 使用overlay存储驱动可能导致过多的inode消耗,尤其是Docker host上镜像和容器的数目增长时。大量的镜像或者很多容器启停,会迅速消耗该Docker host的inode。但是overlay2 存储驱动不存在这个问题
overlay2存储驱动已经成为了Docker首选存储驱动,并且性能优于AUFS和devicemapper。不过,也带来了一些与其他文件系统不兼容性,如对open和rename操作的支持,另外,overlay和overlay2相比,overlay2支持了多层镜像,优化了inode的使用。
参考链接:
架构:https://i4t.com/4248.html
实践:https://legacy.gitbook.com/book/yeasy/docker_practice/details
Docker安装
Docker自动安装
curl -fsSL get.docker.com -o get-docker.sh
sudo sh get-docker.sh --mirror Aliyun添加用户组:
sudo groupadd docker
sudo usermod -aG docker $USERCentos设置开机自启
yum install -y epel-release bash-completion && cp /usr/share/bash-completion/completions/docker /etc/bash_completion.d/
systemctl enable --now dockerDeepin 安装Docker
- 卸载旧Docker
sudo apt-get remove docker.io docker-engine - 安装密钥管理与下载相关的工具
sudo apt-get install -y apt-transport-https ca-certificates curl gnupg2 software-properties-common3.下载并安装秘钥
curl -fsSL https://mirrors.ustc.edu.cn/docker-ce/linux/debian/gpg | sudo apt-key add -4.查看秘钥安装是否成功
sudo apt-key fingerprint 0EBFCD88# dulei @ dulei-PC in ~ [8:31:25]
$ sudo apt-key fingerprint 0EBFCD88
pub rsa4096 2017-02-22 [SCEA]
9DC8 5822 9FC7 DD38 854A E2D8 8D81 803C 0EBF CD88
uid [ 未知 ] Docker Release (CE deb) <docker@docker.com>
sub rsa4096 2017-02-22 [S]
- 手动编辑/etc/apt/sources.list,添加 docker-ce 软件源
sudo su
echo -e "deb [arch=amd64] https://download.docker.com/linux/debian stretch stable" >> /etc/apt/sources.list
- 安装docker
sudo apt-get update
sudo apt-get install docker-ce- 启动docker
service docker start- 免 sudo 使用 docker,注销再登录 即可生效.
sudo groupadd docker
sudo usermod -aG docker $USER- 安装docker-compose
sudo curl -L https://github.com/docker/compose/releases/download/1.25.0-rc2/docker-compose-Linux-x86_64 -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose10.更改docker国内镜像源
修改文件: /etc/docker/daemon.json
添加如下内容:
{
"registry-mirrors": ["https://n6syp70m.mirror.aliyuncs.com"]
}修改之后重启docker服务:
sudo service docker restartHello-World
$ sudo docker container run hello-world
Unable to find image ‘hello-world:latest‘ locally
latest: Pulling from library/hello-world
1b930d010525: Pull complete
Digest: sha256:c3b4ada4687bbaa170745b3e4dd8ac3f194ca95b2d0518b417fb47e5879d9b5f
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/
以上是关于Docker入门一概念和安装的主要内容,如果未能解决你的问题,请参考以下文章