zhihutheirTTS1
Posted skydaddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了zhihutheirTTS1相关的知识,希望对你有一定的参考价值。
https://zhuanlan.zhihu.com/p/88502449 from zhihu
最近研究了一段时间的TTS模型。然后将自己的一些成果研究分享一下下,有不对的地方还请忽略。
一、Merlin语音合成系统。
这个系统应该可以说是历史比较长久的一套系统了,其搭配了三个声码器,WORLDSTRAIGHTWORLD2,感觉采用WORLD的偏多一点。WORLD的介绍网上已经很多啦,这里就不赘述了。
系统流程梳理:
先贴一张流程图:
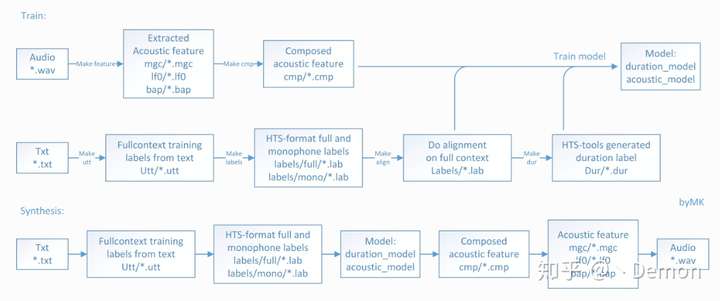
光看着就复杂。。。简单来说就四个模块:
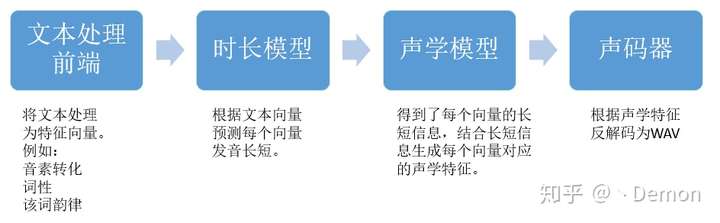
①文本处理前端
这个模块自己感觉是本系统里最难上手的地方,它要干的工作是:
1.将文字转化为自己的建模单元,比如文字转音素、韵律标注、词性标注等。
2.将标注转化为HTS格式。
3.根据设计的question来将每一个单元转化为向量。
HTS格式的详解和question的设计可以参考,里面也详细讲了一些所需的知识:
https://mtts.readthedocs.io/zh_CN/latest/merlin.html
我是没有把它完全弄懂。。。。
经过这个模块,得到Merlin接受的HTS格式标签

然后就可以把config文件中的
NORMLAB : True
执行merlin脚本即可得到Merlin系统的输入啦,当然前提是把question准备好。
②时长模型、声学模型
时长模型,如字面意思就是预测每个单元的发音长度。
声学模型就是为了得到WORLD所需的各种参数。
获得时长模型的输入输出就需要:
1.每个单元对应的长度。
2.每个单元的向量。
单元向量在文本前端可以获得。长度的获得就比较麻烦了。以没有韵律对齐标签的数据为例,
参考MTTS这个项目

首先利用alig工具,将音素对齐,然后再处理。跟着这个项目的Readme操作,比较容易。
主要是为了得到每个音素的长度。

有了这个完整的.lab文件,就可以启动Merlin的 05、06脚本了,05脚本是处理时长模型的训练文件,06脚本是处理声学模型的训练文件。对应配置文件里,只需开启
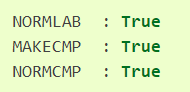
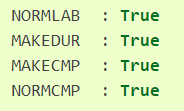
处理完毕后得到的文件,打开一下可以发现:
1.语言学特征文件(normal_lab文件夹里的文件)
以我624行的question为例,label为19行,首尾为‘sil’静音,会被去掉:
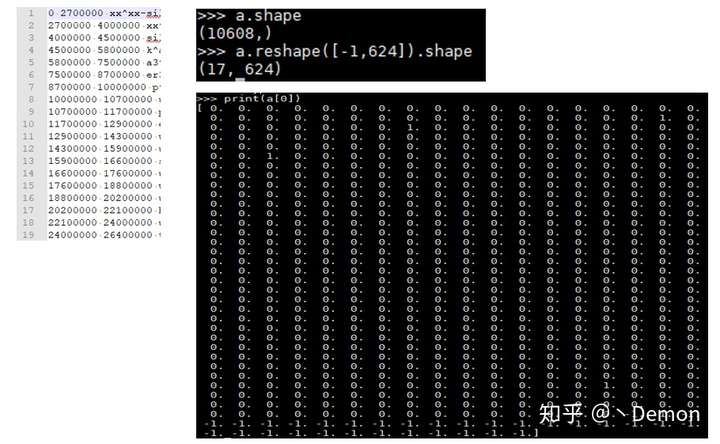
2.时长模型训练目标文件
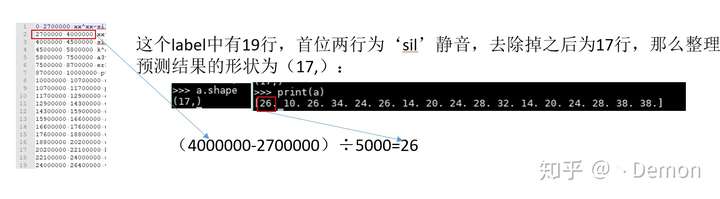
可以看出其做法就是:
Label中的前两个数值相减,再除以5000(5ms,默认值)的个数,即多少个5ms。其预测的就是这个5ms的个数。
3.声学模型的输入输出文件:

此时就比较关注(426,628)形状的来历,其做法:

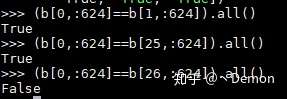
转换完628维度后的矩阵为(17,628),然后每一行重复时长个数,重复的不同在于倒数三维

搞清楚了输入输出后,基本整个流程就清楚了。然后对应训练即可。
二、端到端系统
经过了麻烦的Merlin系统,来梳理一下端到端的系统。
端到端的系统就比较简单了。
1.准备自己的建模单元,想怎么建就怎么建。
2.找好vocoder,准备对应输出。
3.训练就好了。
首先用微软的FastSpeech来说
FastSpeech: Fast, Robust and Controllable Text to Speech
和Merlin做个对比:
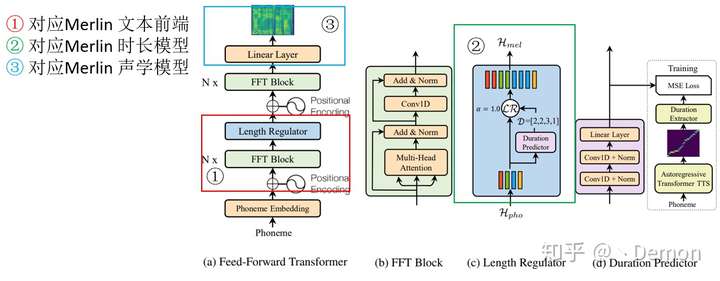
区别在于:
Merlin的embbeding是由人工设定的(question)。
端到端的embbeding是训练过程中形成的。
论文中FastSpeech借助Tacotron2 ransformerTTS的alig为duration标签用以训练它的时长预测能力。后面的做法都和Merlin一致,将embeding的输出复制几个送入Decoder。
星辰漫游者:FastSpeech复现笔记?zhuanlan.zhihu.com
这有大大复现的代码。
FastSpeech属于非自回归模型,所以其预测时间非常得短。并且可以调控duration的长短来进行发音长短的控制、一定韵律的控制。
然后自回归模型以Tacotron2DeepVoice3为代表梳理一下,
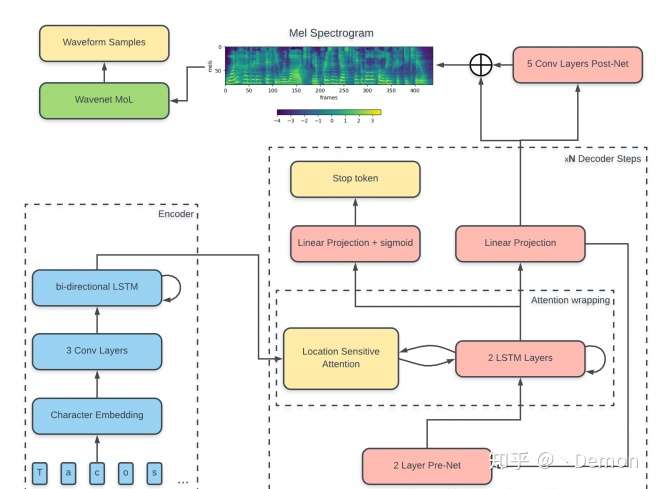
借一下别人的图。。。
自回归模型就是说,它必须一步一步地执行,自己判断或人为设定最大步数。相比Tacotron ,Tacotron2加入了一个stop token状态,从固定预测步数变为了动态的预测步数,可以一定程度上地减少运算量。
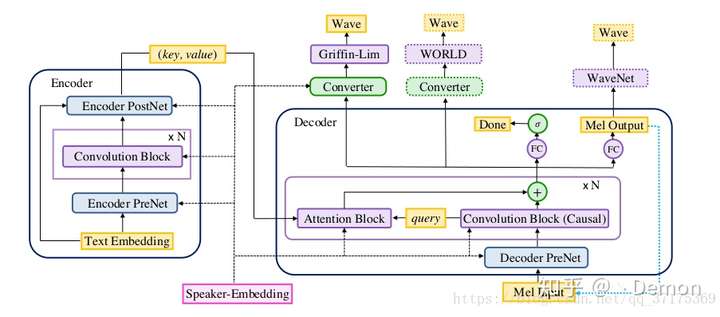
从结构上看,自己感觉其实和Tacotron是一样的,不同的就是换成了全卷积,然后把attention优化了一下,循环的步骤只送入query,(key,value)都放到了encoder层面,这么做应该也是为了加速解码过程。Github上也有很多代码了,此处就不贴代码了。
所以相同的FLOAS能力下,非自回归模型显著要快于自回归模型。
自己实验得,同样十个字,生成mel图速率,FastSpeech在几十毫秒级,Tacotron2在三百毫秒级,DeepVoice3在一百五十毫秒级。
最后,贴一个实验结果,
最近看见Google发了一篇Tacotron控制韵律、节奏的论文,自己复现了一下,做法略有不同。
https://arxiv.org/pdf/1910.01709.pdf
论文是一部分监督学习,一部分无监督学习,有两个控制参数,一个是由人控制,另一个是无监督训练的。
然后自己懒到不想标注数据,所以改成全部的无监督学习,采用了2维的flag向量生成一个控制信息。
采用了标贝公开的数据实验,网络自己总结的向量变化情况如下:
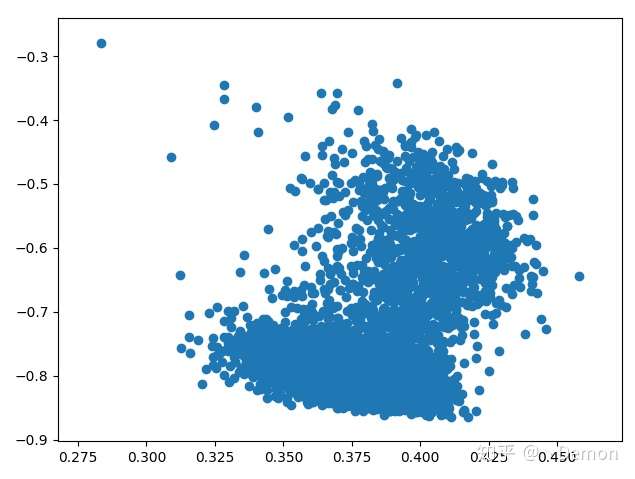
当输入[-1,-1]时,生成的语音说话快,[1,1]时则很慢。
基本符合这个数据库的数据特点,情感变化不大,说话快慢变化比较凸显。
后续搭一个http://github.io来展示各个模型的效果,和最后这个实验结果。
以上是关于zhihutheirTTS1的主要内容,如果未能解决你的问题,请参考以下文章