查找算法总结散列表
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了查找算法总结散列表相关的知识,希望对你有一定的参考价值。
时间复杂度上,红黑树在平均情况下插入,查找以及删除上都达到了lgN的时间复杂度。
那么有没有查找效率更高的数据结构呢,答案就是本文接下来要介绍了散列表,也叫哈希表(Hash Table)
什么是哈希表
哈希表就是一种以 键-值(key-indexed) 存储数据的结构,我们只要输入待查找的值即key,即可查找到其对应的值。
哈希的思路很简单,如果所有的键都是整数,那么就可以使用一个简单的无序数组来实现:将键作为索引,值即为其对应的值,这样就可以快速访问任意键的值。这是对于简单的键的情况,我们将其扩展到可以处理更加复杂的类型的键。
使用哈希查找有两个步骤:
- 使用哈希函数将被查找的键转换为数组的索引。在理想的情况下,不同的键会被转换为不同的索引值,但是在有些情况下我们需要处理多个键被哈希到同一个索引值的情况。所以哈希查找的第二个步骤就是处理冲突
- 处理哈希碰撞冲突。有很多处理哈希碰撞冲突的方法,本文后面会介绍拉链法和线性探测法。
哈希表是一个在时间和空间上做出权衡的经典例子。如果没有内存限制,那么可以直接将键作为数组的索引。那么所有的查找时间复杂度为O(1);如果没有时间限制,那么我们可以使用无序数组并进行顺序查找,这样只需要很少的内存。哈希表使用了适度的时间和空间来在这两个极端之间找到了平衡。只需要调整哈希函数算法即可在时间和空间上做出取舍。
哈希函数
哈希查找第一步就是使用哈希函数将键映射成索引。这种映射函数就是哈希函数。如果我们有一个保存0-M数组,那么我们就需要一个能够将任意键转换为该数组范围内的索引(0~M-1)的哈希函数。哈希函数需要易于计算并且能够均匀分布所有键。比如举个简单的例子,使用手机号码后三位就比前三位作为key更好,因为前三位手机号码的重复率很高。再比如使用身份证号码出生年月位数要比使用前几位数要更好。
在实际中,我们的键并不都是数字,有可能是字符串,还有可能是几个值的组合等,所以我们需要实现自己的哈希函数。
1. 正整数
获取正整数哈希值最常用的方法是使用除留余数法。即对于大小为素数M的数组,对于任意正整数k,计算k除以M的余数。M一般取素数。
2. 字符串
将字符串作为键的时候,我们也可以将他作为一个大的整数,采用再采用保留除余法。我们可以将组成字符串的每一个字符取值然后进行哈希,比如
public int GetHashCode(string str)
{
char[] s = str.ToCharArray();
int hash = 0;
for (int i = 0; i < s.Length; i++)
{
hash = s[i] + (31 * hash);
}
return hash;
}
java中String的默认实现就是类似于此。
上面的哈希值是Horner计算字符串哈希值的方法,公式为:
h = s[0] · 31L–1 + … + s[L – 3] · 312 + s[L – 2] · 311 + s[L – 1] · 310
举个例子,比如要获取”call”的哈希值,字符串c对应的unicode为99,a对应的unicode为97,L对应的unicode为108,所以字符串”call”的哈希值为 3045982 = 99·313 + 97·312 + 108·311 + 108·310 = 108 + 31· (108 + 31 · (97 + 31 · (99)))
如果对每个字符去哈希值可能会比较耗时,所以可以通过间隔取N个字符来获取哈西值来节省时间,比如,可以 获取每8-9个字符来获取哈希值:
public int GetHashCode(string str)
{
char[] s = str.ToCharArray();
int hash = 0;
int skip = Math.Max(1, s.Length / 8);
for (int i = 0; i < s.Length; i+=skip)
{
hash = s[i] + (31 * hash);
}
return hash;
}
但是,对于某些情况,不同的字符串会产生相同的哈希值,这就是前面说到的哈希冲突(Hash Collisions),比如下面的四个字符串:

如果我们按照每8个字符取哈希的话,就会得到一样的哈希值。所以下面来讲解如何解决哈希碰撞:
避免哈希冲突
拉链法
通过哈希函数,我们可以将键转换为数组的索引(0-M-1),但是对于两个或者多个键具有相同索引值的情况,我们需要有一种方法来处理这种冲突。
一种比较直接的办法就是,将大小为M 的数组的每一个元素指向一个条链表,链表中的每一个节点都存储散列值为该索引的键值对,这就是拉链法。
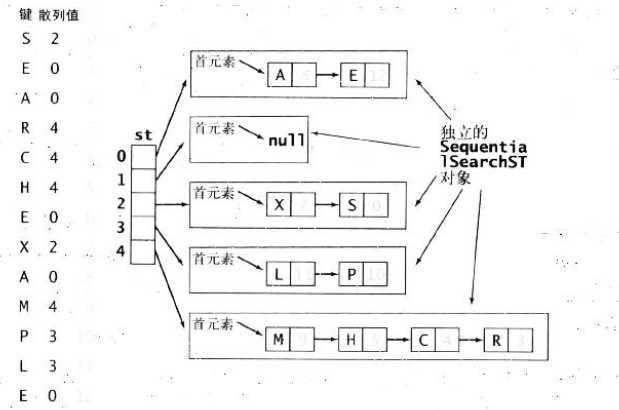
基于拉链法的散列表的实现简单,在键的顺序并不重要的应用中,它可能是最块的(也是使用最广泛的)符号表实现。
线性探测法
线性探测法是开放寻址法解决哈希冲突的一种方法,基本原理为,使用大小为M的数组来保存N个键值对,其中M>N,我们需要使用数组中的空位解决碰撞冲突。
开放寻址法中最简单的是线性探测法:当碰撞发生时即一个键的散列值被另外一个键占用时,直接检查散列表中的下一个位置即将索引值加1,这样的线性探测会出现三种结果:
- 命中,该位置的键和被查找的键相同
- 未命中,键为空
- 继续查找,该位置和键被查找的键不同。
空元素(记为null)可以作为查找结束的标志。
和拉链法一样,开放地址类的三列表的性能也依赖于a=N/M的比值,我们称为散列表的使用率。
对于拉链法,a是每条链的长度,因此一般大于1;对于基于先行探测的散列表,a是表中已被占用的空间比例,它是不可能大于1的,
为保证性能。我们动态调整数组的大小来保证使用率在1/8和1/2之间。
以上是关于查找算法总结散列表的主要内容,如果未能解决你的问题,请参考以下文章