查找算法总结—顺序二分二叉红黑
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了查找算法总结—顺序二分二叉红黑相关的知识,希望对你有一定的参考价值。
1.顺序查找
在查找中我们一个一个顺序的遍历表中的所有键并使用equals()方法来查找匹配的键。
优点:对数组的结构没有特定的要求,可以使用数组或者链表实现,算法简单。
缺点:当数组个数n较大时,效率低下。
时间复杂度:查找命中时,最大时间复杂度是O(n),最小时间复杂度是O(1),平均时间复杂度是O(n/2);未命中时,总需要O(n)次比较。
向一个空表中插入N个不同的件需要N2次比较。
2.基于有序数组的二分查找
在查找时,我们先将被查找的键和子数组的中间键比较。如果被查找的键小于中间键,我们就在左子数组中继续查找,如果大于我们就在右子数组中继续查找,否则中间键就是我们要找的键。
非递归的二分查找:


//非递归
public int rank(Key key)
{
int lo = 0, hi = N - 1;
while(lo <= hi)
{
int mid = lo + (hi - lo) / 2;
int com = key.compareTo(keys[mid]);
if(com < 0)
{
hi = mid - 1;
}
else if(com > 0)
{
lo = mid + 1;
}
else
{
return mid;
}
}
return lo;
}
非递归的二分查找:
//递归
public int rank(Key key,int lo,int hi)
{
if(hi < lo)
{
return lo;
}
int mid = lo + (hi - lo) / 2;
int com = key.compareTo(keys[mid]);
if(com < 0)
{
return rank(key,lo,mid-1);
}
else if(com > 0)
{
return rank(key,mid + 1,hi);
}
else
{
return mid;
}
}
一般情况下二分查找都比顺序查找快得多,对于一个静态表(不允许插入)来说,将其在初始化时就排序是值得的。

对于二分查找而言,如果表太大,动态表(插入操作较多)是不适用的。在上表所示,二分查找算法在插入的时候成本依然是O(n)级别。
核心的问题在于我们能否找到能够同时保证查找和插入操作都是对数级别的算法和数据结构。答案是令人兴奋的“可以”!
我们如何能够实现这个目标呢?要支持高效的插入操作,我们似乎需要一种链式结构。但单链接的链表是无法使用二分查找法的,
因为二分查找的高效来自于能够快速通过索引取得任何子数组的中间元素(但得到一条链表的中间元素的唯一方法只能是沿链表遍历)。
为了将二分查找的效率和链表的灵活性结合起来,我们需要更加复杂的数据结构。能够同时拥有两者的就是二叉查找树。
以上详细内容可参考博文:浅谈算法和数据结构: 六 符号表及其基本实现
3.二叉查找树
二叉查找树:是一棵二叉树,其中每个结点都含有一个键以及相关联的一个值且每个结点的键都大于其左子树中的任意结点的键而小于其右子树中的任意结点的键。
二叉查找树的插入、查找、最大键最小键、向上取整和向下取整、范围查找、删除操作在 算法(第四版)书中有很好的实现,其中的算法思想非常值得学习。
可参考博文:浅谈算法和数据结构: 七 二叉查找树
实现代码:
public class BTS<Key extends Comparable<Key>,Value> {
//定义树
public class Node
{
//左结点
private Node left;
//右结点
private Node right;
private Key key;
private Value value;
private int N;
public Node(Key key,Value value,int N)
{
this.key = key;
this.value = value;
this.N = N;
}
}
//根结点
private Node root;
//获取树的大小
public int size()
{
return size(root);
}
public int size(Node root)
{
if(root == null)
{
return 0;
}
return root.N;
}
//根据键获取相关联的值
public Value get(Key key)
{
return get(root,key);
}
public Value get(Node root,Key key)
{
if(root == null)
{
return null;
}
//判断被查找键与当前结点键的大小
int cmp = root.key.compareTo(key);
//若被查找的键小于当前结点键,则继续在当前结点的左子树上查找
if(cmp < 0)
{
return get(root.left,key);
}
//若被查找的键大于当前结点的键,则继续在当前结点的右子树上查找
else if(cmp > 0)
{
return get(root.right,key);
}
//若相等,则返回相关联的值
else
{
return root.value;
}
}
//向树中添加键值对,并插入在合适的位置
public void put(Key key,Value value)
{
root = put(root,key,value);
}
public Node put(Node root,Key key,Value value)
{
if(root == null)
{
return new Node(key,value,1);
}
//插入的键与当前结点的键进行比较
int cmp = root.key.compareTo(key);
//若插入的键小于当前结点的键,则继续向当前结点的左子树中插入
if(cmp < 0)
{
root.left = put(root.left,key,value);
}
//若插入的键大于当前结点的键,则继续向当前结点的右子树中插入
else if(cmp > 0)
{
root.right = put(root.right,key,value);
}
//若查找到相同的键时,则将插入的键相关联的值替换掉当前结点的键相关联的值
else
{
root.value = value;
}
//将树的大小加1
root.N = size(root.left) + size(root.right) + 1;
return root;
}
//获取树中最小的键
public Key min()
{
return min(root).key;
}
public Node min(Node x)
{
//若当前结点的左子树为空时,则表明当前结点的键是树中最小的键,返回该结点
if(x.left == null)
{
return x;
}
//否则继续向当前结点的左子树查找
return min(x.left);
}
//对给定键进行向下取整
//如果给定的键小于二叉查找树的根结点的键,
//那么小于等于key的最大键floor(key)一定在根结点的左子树中;
//如果给定的键大于二叉查找树的根结点的键,
//那么只有当根结点右子树中存在小于等于key的结点时,
//小于等于key的最大键才会出现在右子树中,
//否则根结点就是小于等于key的最大键。
public Key floor(Key key)
{
Node x = floor(root,key);
if(x == null)
{
return null;
}
return x.key;
}
public Node floor(Node root,Key key)
{
if(root == null)
{
return null;
}
int cmp = key.compareTo(root.key);
//如果相等,则返回当前结点
if(cmp == 0)
{
return root;
}
//给定键小于当前结点的键时,继续递归查找当前结点的左子树
else if(cmp < 0)
{
return floor(root.left,key);
}
//给定键大于当前结点的键时,向当前结点的右子树继续遍历,并将结点返回给t
Node t = floor(root.right,key);
//若t不为空,则说明右子树中存在小于等于key的最大键,返回t
if(t != null)
{
return t;
}
//否则返回当前结点
else
{
return root;
}
}
//查找排位为key的键
public Key select(int key)
{
return select(root,key).key;
}
public Node select(Node x,int key)
{
if(x == null)
{
return null;
}
int size = size(x.left);
//如果key小于左子树中的结点数size,那么就继续递归地在左子树中查找排名为k的键
if(key < size)
{
return select(x.left,key);
}
//如果key大于size,我们就递归地在右子树中查找排名为k-t-1的键
else if(key > size)
{
return select(x.right,key - size - 1);
}
//如果size等于key,返回当前根结点中的键
else
{
return x;
}
}
//根据给定键返回键在树中的排名
public int rank(Key key)
{
return rank(root,key);
}
public int rank(Node x,Key key)
{
if(x == null)
{
return 0;
}
int cmp = key.compareTo(x.key);
//如果给定键小于当前结点的键,则递归地向左子树比较并返回该键在左子树中的排名
if(cmp < 0)
{
return rank(x.left,key);
}
//如果给定键大于当前结点的键,则返回左子树中的结点总数加上1(根结点)再加上右子树中的排名(递归计算)
else if(cmp > 0)
{
return 1 + size(x.left) + rank(x.right,key);
}
//若相等,则返回当前结点左子树中的结点总数
else
{
return size(x.left);
}
}
//删除最小键
public void deleteMin()
{
deleteMin(root);
}
public Node deleteMin(Node x)
{
//若当前结点的左子树为空,则返回当前结点的右子树的结点
if(x.left == null)
{
return x.right;
}
//若当前结点的左子树不为空,则继续深入当前结点的左子树直至遇到空左子树
//进行回溯时将该结点的链接指向该结点的右子树
x.left = deleteMin(x.left);
//重新计算树的大小
x.N = size(x.left) + size(x.right) + 1;
return x;
}
//删除给定键
public void delete(Key key)
{
root = delete(root,key);
}
public Node delete(Node x,Key key)
{
if(x == null)
{
return null;
}
int cmp = key.compareTo(x.key);
//若给定键小于当前结点的键,则继续深入当前结点的左子树
if(cmp < 0)
{
x.left = delete(x.left,key);
}
//若给定键大于当前结点的键,则继续深入当前结点的右子树
else if(cmp > 0)
{
x.right = delete(x.right,key);
}
//若相等
else
{
//如果当前结点的左子树为空,则返回当前结点的右子树结点
if(x.left == null)
{
return x.right;
}
//如果当前结点的右子树为空,则返回当前结点的左子树结点
if(x.right == null)
{
return x.left;
}
//否则的话:
//1.将指向即将被删除的结点的链接保存为t
Node t = x;
//2.将x指向它的后继结点min(t.right)
x = min(t.right);
//3.将x的右链接(原本指向一棵所有结点都大于x.key的二叉查找树)指向deleteMin(t.right),也就是在
//删除后所有的结点仍然都大于x.key的子二叉查找树
x.right = deleteMin(t.right);
//4.将x的左链接(本为空)设为t.left(其下所有的键都小于被删除的结点和它的后继结点)
x.left = t.left;
}
//重新计算树的大小
x.N = size(x.left) + size(x.right) + 1;
return x;
}
}
分析:使用二叉查找树的算法的运行时间取决于树的形状,而树的形状又取决于被插入的先后顺序,在最好的情况下,一个含有N个节点的树是完全平衡的,每个空链接到根节点的距离都是lgN。
最坏情况下,搜索路径上可能有N个节点。就这个模型的分析而言,二叉查找树和快速排序几乎是”双胞胎”,树的根节点就是快速排序中的第一个切分元素。
二叉树事先的良好性能依赖于其中的键的分布足够随机以消除长路径。对于快速排序,我们可以先将数组打乱,而对于符号表的API,我们无能为力,因为符号表的用例控制着各种操作的先后顺序,
。最坏的情况是所有键按照顺序或者逆序插入符号表。
这个问题依然是可以被解决的,因为还有平衡二叉查找树,它能保证无论键的插入顺序如何,树的高度都将是总键数的对数。
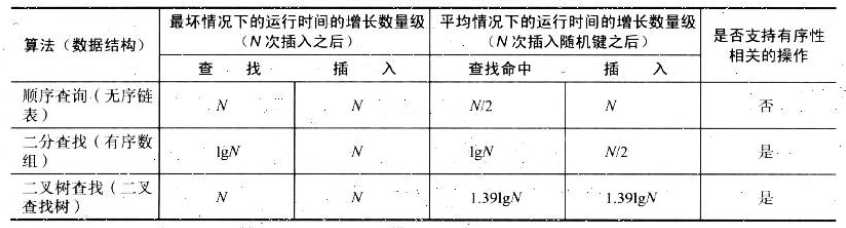
4.平衡查找树
我们希望能保持二叉查找树的平衡性,所有查找都能在lgN次比较内结束。
4.1 2-3查找树
为了保证树的平衡性,我们需要一些灵活性,因此在这里我们允许树中的一个节点保存多个键。
首先我们引入2-3查找树,2-3查找树既有2-节点(一个键和两条链接)又有3-节点(两个键和三条链接),当然这只是过渡,过后再引入红黑树和B-树。
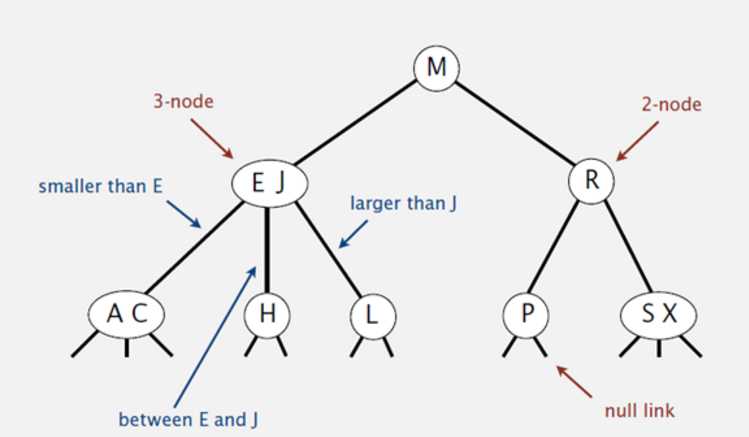
和标准的二叉查找树由上向下生长不同,2-3树的生长是由下向上的(节点的分解),也正是因为这样,2-3树才保证了平衡。
具体可参考博文:浅谈算法和数据结构: 八 平衡查找树之2-3树
2-3树的实现操作是并不方便的,我们需要维护两种不同类型的节点,将链接和其他信息从一个节点复制到另一个节点,将节点从一种数据类型转换到另一种数据类型等等,
实现这些不仅需要大量的代码,而且他们所产生的额外开销可能会使算法比标准的二叉查找树更慢。
实际上我们只需要花一点代价就能解决这个问题,就是下面我们引入的红黑树。
4.2 红黑二叉查找树
红黑二叉查找树的基本思想是用标准的二叉查找树(完全有2-节点构成)和一些额外的信息(替换3-节点)来表示2-3树。
我们讲树中的链接分为两种类型:左斜的红色链接将两个2-节点连接起来构成一个3-节点,黑链接则是2-3树中的普通链接。
对于任意的2-3树,只要对节点进行转换,我们都可以立即派生出一颗对应的二叉查找树。
等价定义:
①红链接均是左链接
②没有任何一个节点同时和两条红链接相连
③ 该树是完美黑色平衡的,即任意空链接到根节点的路径上的黑链接数量相同。
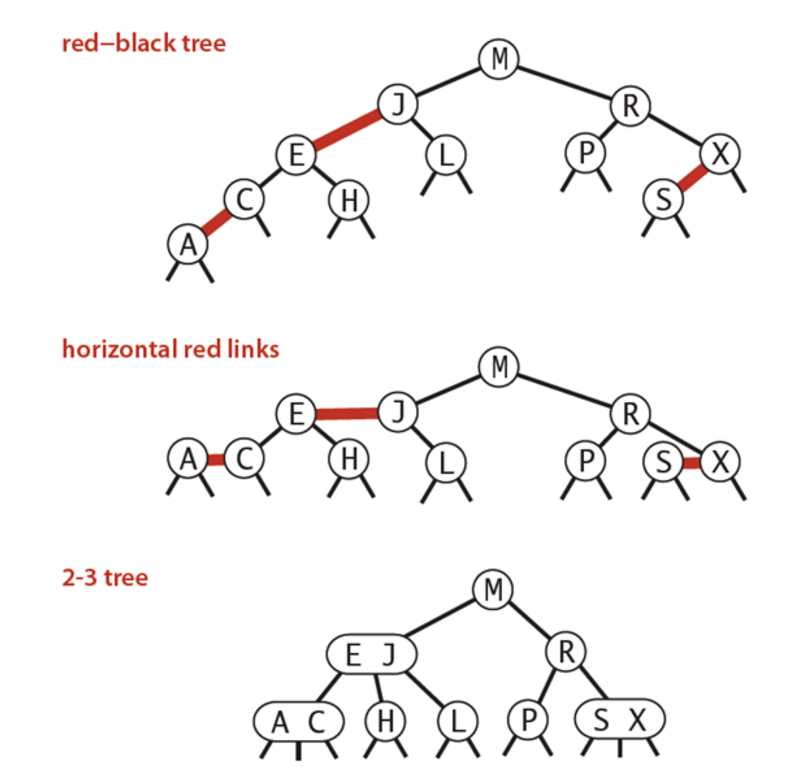
通过旋转和颜色翻转这些平衡化操作,让一个红黑树保持平衡。红黑树并不追求“完全平衡”——它只要求部分地达到平衡要求,降低了对旋转的要求,从而提高了性能。
具体可参考下面这篇博文:
浅谈算法和数据结构: 九 平衡查找树之红黑树
红黑树应用:
TreeMap 和 TreeSet 是 Java Collection Framework 的两个重要成员,其中 TreeMap 是 Map 接口的常用实现类,而 TreeSet 是 Set 接口的常用实现类。
虽然 HashMap 和 HashSet 实现的接口规范不同,但 TreeSet 底层是通过 TreeMap 来实现的,因此二者的实现方式完全一样。而 TreeMap 的实现就是红黑树算法。
对于 TreeMap 而言,由于它底层采用一棵“红黑树”来保存集合中的 Entry,这意味这 TreeMap 添加元素、取出元素的性能都比 HashMap 低:当 TreeMap 添加元素时,需要通过循环找到新增 Entry 的插入位置,因此比较耗性能;当从 TreeMap 中取出元素时,需要通过循环才能找到合适的 Entry,也比较耗性能。
但 TreeMap、TreeSet 比 HashMap、HashSet 的优势在于:TreeMap 中的所有 Entry 总是按 key 根据指定排序规则保持有序状态,TreeSet 中所有元素总是根据指定排序规则保持有序状态。
以上是关于查找算法总结—顺序二分二叉红黑的主要内容,如果未能解决你的问题,请参考以下文章