Hash算法:双重散列
Posted magic-sea
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hash算法:双重散列相关的知识,希望对你有一定的参考价值。
双重散列是线性开型寻址散列(开放寻址法)中的冲突解决技术。双重散列使用在发生冲突时将第二个散列函数应用于键的想法。
此算法使用:
(hash1(key) + i * hash2(key)) % TABLE_SIZE
来进行双哈希处理。hash1() 和 hash2() 是哈希函数,而 TABLE_SIZE 是哈希表的大小。当发生碰撞时,我们通过重复增加 步长i 来寻找键。
第一个Hash函数:hash1(key) = key % TABLE_SIZE。
1 /** 2 * 计算首次的Hash值 3 * 4 * @param key 5 * @return 6 */ 7 private int hash1(int key) { 8 return (key % TABLE_SIZE); 9 }
第二个Hash函数是:hash2(key) = PRIME – (key % PRIME),其中 PRIME 是小于 TABLE_SIZE 的质数。
1 /** 2 * 发生碰撞是时继续计算Hash值 3 * 4 * @param key 5 * @return 6 */ 7 private int hash2(int key) { 8 return (PRIME - (key % PRIME)); 9 }
第二个Hash函数表现好的特征:
-
绝对不会产生 0 索引
-
能在整个HashTable 循环探测
-
计算会快点
-
与第一个Hash函数互相独立
-
PRIME 与 TABLE_SIZE 是 “相对质数”
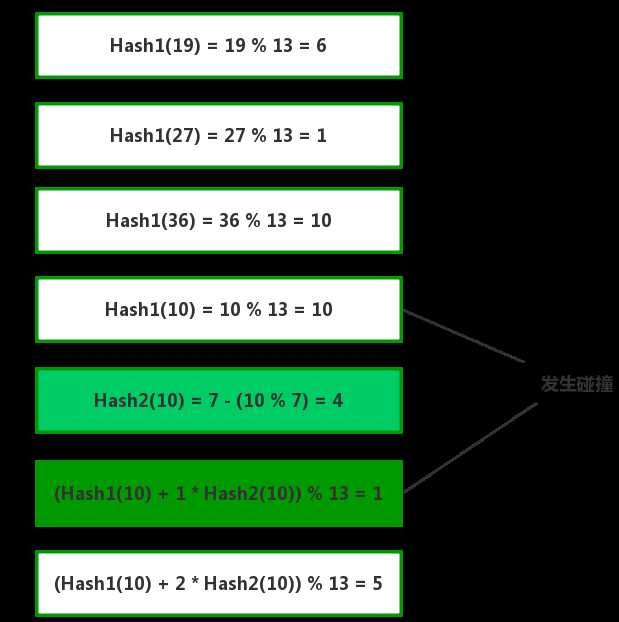
Java实现代码:
1 package algorithm.hash; 2 3 /** 4 * 双重哈希 5 */ 6 public class DoubleHash { 7 private static final int TABLE_SIZE = 13; // 哈希表大小 8 private static int PRIME = 7; // 散列函数值 9 10 private int[] hashTable; 11 private int curr_size; // 当前表中存的元素 12 13 public DoubleHash() { 14 this.hashTable = new int[TABLE_SIZE]; 15 this.curr_size = 0; 16 for (int i = 0; i < TABLE_SIZE; i++) 17 hashTable[i] = -1; 18 } 19 20 private boolean isFull() { 21 return curr_size == TABLE_SIZE; 22 } 23 24 /** 25 * 计算首次的Hash值 26 * 27 * @param key 28 * @return 29 */ 30 private int hash1(int key) { 31 return (key % TABLE_SIZE); 32 } 33 34 /** 35 * 发生碰撞是时继续计算Hash值 36 * 37 * @param key 38 * @return 39 */ 40 private int hash2(int key) { 41 return (PRIME - (key % PRIME)); 42 } 43 44 /** 45 * 向Hash表中存值 46 * 47 * @param key 48 */ 49 private void insertHash(int key) { 50 /* 表是否已满 */ 51 if (isFull()) { 52 return; 53 } 54 55 /* 获取首次的Hash值 */ 56 int index = hash1(key); 57 58 // 如果发生碰撞 59 if (hashTable[index] != -1) { 60 /* 计算第二次的Hash值 */ 61 int index2 = hash2(key); 62 int i = 1; 63 while (true) { 64 /* 再次合成新的地址 */ 65 int newIndex = (index + i * index2) % TABLE_SIZE; 66 67 // 如果再次寻找时没有发生碰撞,把key存入表中的对应位置 68 if (hashTable[newIndex] == -1) { 69 hashTable[newIndex] = key; 70 break; 71 } 72 i++; 73 } 74 } else { 75 // 一开始没有发生碰撞 76 hashTable[index] = key; 77 } 78 curr_size++; // Hash表中当前所存元素数量加1 79 } 80 81 /** 82 * 打印Hash表 83 */ 84 private void displayHash() { 85 for (int i = 0; i < TABLE_SIZE; i++) { 86 if (hashTable[i] != -1) 87 System.out.println(i + " --> " + hashTable[i]); 88 else 89 System.out.println(i); 90 } 91 } 92 93 public static void main(String[] args) { 94 int[] a = {19, 27, 36, 10, 64}; 95 96 DoubleHash doubleHash = new DoubleHash(); 97 for (int i = 0; i < a.length; i++) 98 doubleHash.insertHash(a[i]); 99 100 doubleHash.displayHash(); 101 } 102 103 }
以上是关于Hash算法:双重散列的主要内容,如果未能解决你的问题,请参考以下文章