scrpy--分布式爬虫
Posted tulintao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scrpy--分布式爬虫相关的知识,希望对你有一定的参考价值。
原来的scrapy中的Scheduler维护的是当前机器中的任务队列(存放着Request对象以及回调函数等信息) + 当前的去重队列(存放访问过的url地址)
实现分布式的关键就是需要找一台专门的主机在上面运行一个共享的队列,比如redis。然后重写scrapy的Scheduler,让新的Scheduler到共享的队列中存取Request,并且去除重复的Request请求
1、共享队列
2、重写Scheduler,让它不论是去重还是执行任务都去访问共享队列中的内容
3、为Scheduler专门定制去重规则(利用redis的集合类型)
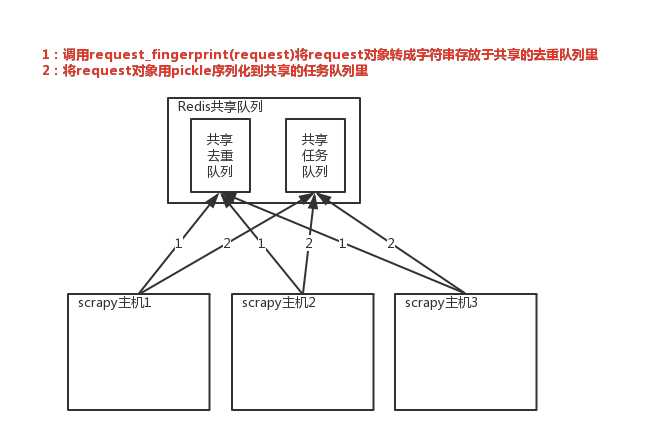
# 在scrapy中使用redis的共享去重队列 # 1、在settings中配置redis链接 REDIS_HOST=‘localhost‘ # 主机名称 REDIS_PORT=‘6379‘ # 端口号 REDIS_URL=‘redis://user:pass@hostname:9001‘ # 连接url,优先于上面的配置 REDIS_PARAMS={} # redis连接参数 REDIS_PARAMS[‘redis_cls‘] = ‘myproject.RedisClient‘ # 指定连接redis的python模块 REDIS_ENCODING = ‘utf-8‘ # redis的编码类型 # 2、让scrapy使用共享的去重队列 # 使用scrapy_redis提供的去重功能,其实是利用redis的集合来实现的 DUPEFILTER_CLASS = ‘scrapy_redis.dupefilter.RFPDupeFilter‘ # 3、需要指定Redis中集合的Key名称,Key=存放不重复Request字符串的集合 DUPEFILTER_KEY = ‘dupefilter:%(timestamp)s‘
# scrapy_redis去重+调度实现分布式采集 # settings中的配置 SCHEDULER = ‘scrapy_redis.scheduler.Scheduler‘ # 调度器将不重复的任务用pickle序列化后放入共享的任务队列中,默认是 使用优先级队列(默认),别的还有PriorityQueue(有序集合),FifoQueue(列表),LifoQueue(列表)。 SCHEDULER_QUEUE_CLASS = ‘scrapy_redis.queue.PriorityQueue‘ # 对保存到redis中的request对象进行序列化,默认是通过pickle来进行序列化的 SCHEDULER_SERIALIZER = ‘scrapy_redis.picklecompat‘ # 调度器中请求任务序列化后存放在redis中的key SCHEDULER_QUEUE_KEY = ‘%(spider)s:requests‘ # 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空 SCHEDULER_PERSIST = True # 是否在开始之前清空调度器和去重记录,True=清空,False=不清空 SCHEDULER_FLUSH_ON_START = False # 去调度器中获取数据的时候,要是是空的话最多等待的时间(最后没数据、未获取到数据)。如果没有的话就立刻返回会造成空循环次数过多,cpu的占有率会直线飙升 SCHEDULER_IDLE_BEFORE_CLOSE = 10 # 去重规则,在redis中保存的时候相对应的key SCHEDULER_DUPEFILTER_KEY = ‘%(spider)s:dupefilter‘ # 去重规则对应处理的类,将任务request_fingerprint(request)得到的字符串放到去重队列中 SCHEDULER_DUPEFILTER_CLASS = ‘scrapy_redis.dupefilter.REPDupeFilter‘
数据的持久化
# 当从目标站点解析出我们想要的内容以后保存成item对象,就会由引擎交给pipeline来进行数据持久化操作/保存到指定的数据库中,scrapy_redis提供了一个pipeline组件,可以帮助我们将item存储到redis中 # 将item持久化保存到redis的时候,指定key和序列化函数 REDIS_ITEMS_KEY = ‘%(spider)s:items‘ REDIS_ITEMS_SERIALIZER = ‘json.dumps‘
# 从redis中获取起始的URL scrapy程序爬虫目标站点,一旦爬取完成以后就结束了,万一目标站点内容更新了,拿着时候我们要是还想在此采集的话,就需要重新启动这个scrapy项目,这就会变的非常麻烦,scrapy_redis提供了一种让scrapy项目从redis中获取起始的url,如果没有scrapy就会过一段时间再来取而不会直接结束,所以我们只想要写一个简单的程序脚本,定期的往redis队列中放入一个起始的url就可以了 # 编写脚本的时候,设置起始url从redis中的Key进行获取 REDIS_START_URLS_KEY = ‘%(name)s:start_urls‘ # 获取起始URL的时候,去集合中获取呢还是去列表中获取:True=集合, False=列表 REDIS_START_URLS_AS_SET = False # 获取起始URL的时候,要是为True的话,就会使用self.server.spop;False的话就是self.server.lpop
以上是关于scrpy--分布式爬虫的主要内容,如果未能解决你的问题,请参考以下文章