Prometheus+Grafana监控
Posted miaocbin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Prometheus+Grafana监控相关的知识,希望对你有一定的参考价值。
什么是Prometheus?
Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB)。Prometheus使用Go语言开发,是Google BorgMon监控系统的开源版本。
2016年由Google发起Linux基金会旗下的原生云基金会(Cloud Native Computing Foundation), 将Prometheus纳入其下第二大开源项目。
Prometheus目前在开源社区相当活跃。
Prometheus和Heapster(Heapster是K8S的一个子项目,用于获取集群的性能数据。)相比功能更完善、更全面。Prometheus性能也足够支撑上万台规模的集群。
Prometheus的特点
- 多维度数据模型。
- 灵活的查询语言。
- 不依赖分布式存储,单个服务器节点是自主的。
- 通过基于HTTP的pull方式采集时序数据。
- 可以通过中间网关进行时序列数据推送。
- 通过服务发现或者静态配置来发现目标服务对象。
- 支持多种多样的图表和界面展示,比如Grafana等。
Prometheus监控基本原理
Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、nginx、mysql、Linux系统信息(包括磁盘、内存、CPU、网络等等)。
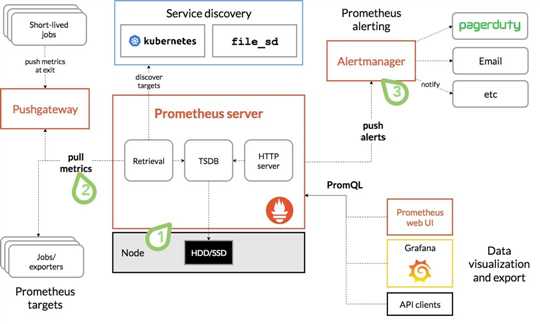
Prometheus服务过程
Prometheus Daemon 负责定时去目标上抓取metrics(指标)数据,每个抓取目标需要暴露一个http服务的接口给它定时抓取。Prometheus支持通过配置文件、文本文件、Zookeeper、Consul、DNS SRV Lookup等方式指定抓取目标。Prometheus采用PULL的方式进行监控,即服务器可以直接通过目标PULL数据或者间接地通过中间网关来Push数据。
Prometheus在本地存储抓取的所有数据,并通过一定规则进行清理和整理数据,并把得到的结果存储到新的时间序列中。
Prometheus通过PromQL和其他API可视化地展示收集的数据。Prometheus支持很多方式的图表可视化,例如Grafana、自带的Promdash以及自身提供的模版引擎等等。Prometheus还提供HTTP API的查询方式,自定义所需要的输出。
PushGateway支持Client主动推送metrics到PushGateway,而Prometheus只是定时去Gateway上抓取数据。
Alertmanager是独立于Prometheus的一个组件,可以支持Prometheus的查询语句,提供十分灵活的报警方式。
Prometheus 三大套件
- Server 主要负责数据采集和存储,提供PromQL查询语言的支持。
- Alertmanager 警告管理器,用来进行报警。
- Push Gateway 支持临时性Job主动推送指标的中间网关。
1. 安装 Prometheus Server
wget http://10.200.77.3:90/Monitor/prometheus/prometheus-2.14.0.linux-amd64.tar.gz tar xzf prometheus-2.14.0.linux-amd64.tar.gz -C /opt/ cd prometheus-2.14.0.linux-amd64 # 配置语法校验: ./promtool check config prometheus.ymlChecking prometheus.yml
SUCCESS: 0 rule files found
# 启动Prometheus: ./prometheus --config.file=prometheus.yml 查看Metrics: http://localhost:9090/graph
此时可以通过浏览器访问prometheus
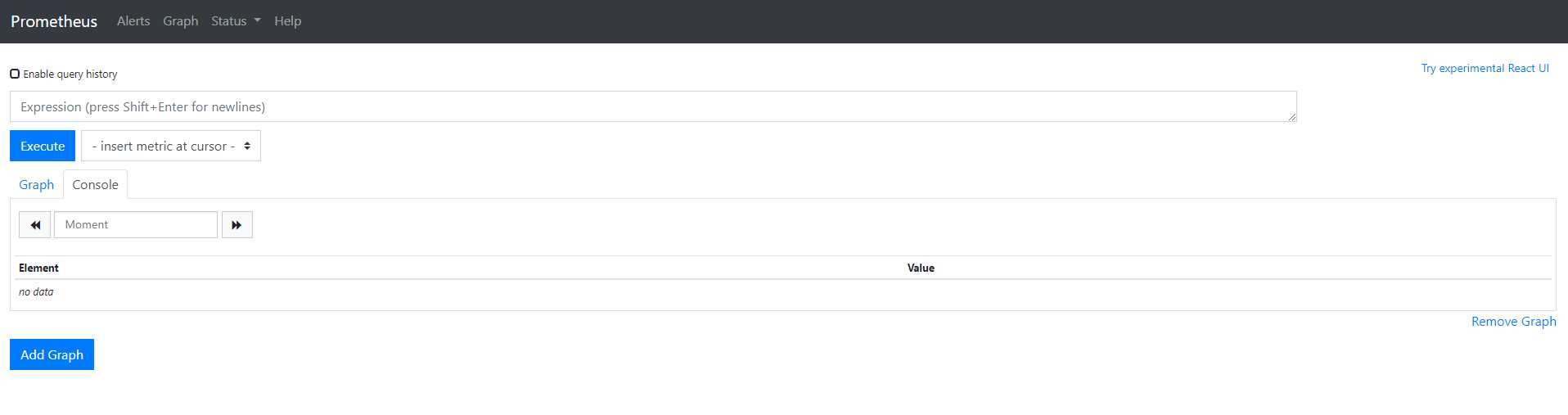
target中只有prometheus server
此时prometheus采用默认配置:
# my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global ‘evaluation_interval‘. rule_files: # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it‘s Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: ‘prometheus‘ scrape_interval: 10s static_configs: - targets: [‘localhost:9090‘]
设置prometheus开机启动
# 设置开机启动 touch /usr/lib/systemd/system/prometheus.service chown prometheus:prometheus /usr/lib/systemd/system/prometheus.service vim /usr/lib/systemd/system/prometheus.service
将如下配置写入prometheus.servie
[Unit] Description=Prometheus Documentation=https://prometheus.io/ After=network.target [Service] Type=simple User=prometheus # --storage.tsdb.path是可选项,默认数据目录在运行目录的./dada目录中 ExecStart=/opt/prometheus/prometheus --config.file=/opt/prometheus/prometheus.yml --web.enable-lifecycle --storage.tsdb.path=/opt/prometheus/data --storage.tsdb.retention=60d Restart=on-failure [Install] WantedBy=multi-user.target
Prometheus启动参数说明
- --config.file -- 指明prometheus的配置文件路径
- --web.enable-lifecycle -- 指明prometheus配置更改后可以进行热加载
- --storage.tsdb.path -- 指明监控数据存储路径
- --storage.tsdb.retention --指明数据保留时间
设置开机启动
systemctl daemon-reload
systemctl enable prometheus.service
systemctl status prometheus.service
systemctl restart prometheus.service
prometheus热加载配置
Prometheus支持Reload配置,按照以下方式即可:
# 注意,,需要在prometheus的启动参数里添加指定--web.enable-lifecycle 参数
Prometheus-2.0版本以后默认重载api没有开启, 配置修改后, 必须要重启 prometheus server才能生效. 若在启动prometheus时加上参数 web.enable-lifecycle , 可以启用配置的热加载.
curl -X POST http://localhost:9090/-/reload
2. Prometheus 配置监控其他Linux主机
2.1 node_exporter安装配置
# 下载node_server wget https://github.com/prometheus/node_exporter/releases/download/v0.18.1/node_exporter-0.18.1.linux-amd64.tar.gz # 解压到指定目录并删除下载文件 tar -zxf node_exporter-0.18.1.linux-amd64.tar.gz mv node_exporter-0.18.1.linux-amd64 /usr/local/ ln -sv /usr/local/node_exporter-0.18.1.linux-amd64 /usr/local/node_exporter rm -f node_exporter-0.18.1.linux-amd64.tar.gz # 运行用户添加 groupadd prometheus useradd -g prometheus -m -d /usr/local/node_exporter/ -s /sbin/nologin prometheus # 系统服务配置 node_exporter touch /usr/lib/systemd/system/node_exporter.service chown prometheus:prometheus /usr/lib/systemd/system/node_exporter.service chown -R prometheus:prometheus /usr/local/node_exporter* vim /usr/lib/systemd/system/node_exporter.service
在node_exporter.service中加入如下代码:
[Unit] Description=node_exporter After=network.target [Service] Type=simple User=prometheus ExecStart=/usr/local/node_exporter/node_exporter Restart=on-failure [Install] WantedBy=multi-user.target
启动 node_exporter 服务并设置开机启动
systemctl daemon-reload
systemctl enable node_exporter.service
systemctl start node_exporter.service
systemctl status node_exporter.service
systemctl restart node_exporter.service
systemctl start node_exporter.service
systemctl stop node_exporter.service
node_exporter启动成功后, 你就可以通过如下api看到你的监控数据了(将下面的node_exporter_server_ip替换成你的node_exporter的IP地址, 放到浏览器中访问就可以了 ).
http://node_exporter_server_ip:9100/metrics
为了更好的展示, 接下来我们将这个api 配置到 prometheus server中, 并通过grafana进行展示.
将 node_exporter 加入 prometheus.yml配置中
- job_name: ‘Linux‘
file_sd_configs:
- files: [‘/opt/prometheus/sd_cfg/Linux.yml‘]
refresh_interval: 5s
并在文件/opt/prometheus/sd_cfg/Linux.yml中写入如下内容
- targets: [‘IP地址:9100‘]
labels:
name: Linux-node1[这里建议给每个主机打个有意义的标签,方便识别.]
如果你按照上面的方式配置了, 但是使用工具 promtool检测prometheus配置时,没有通过, 那肯定是你写的语法有问题, 不符合yml格式. 请仔细检查下. 如有疑问, 可以在下方评论区留言.
这样做的好处是, 方便以后配置监控自动化, 规范化, 将每一类的监控放到自己的配置文件中, 方便维护.
当然, 如果你的服务器少, 要监控的组件少的话, 你也可以将配置都写入prometheus的主配置文件prometheus.yml中, 如:.
# my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global ‘evaluation_interval‘. rule_files: # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it‘s Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: ‘prometheus‘ scrape_interval: 10s static_configs: - targets: [‘localhost:9090‘] - job_name: ‘Linux‘ static_configs:
targets: [‘http://10.199.111.110:9100‘]
labels: group: ‘client-node-exporter‘
重载prometheus配置
curl -X POST http://localhost:9090/-/reload
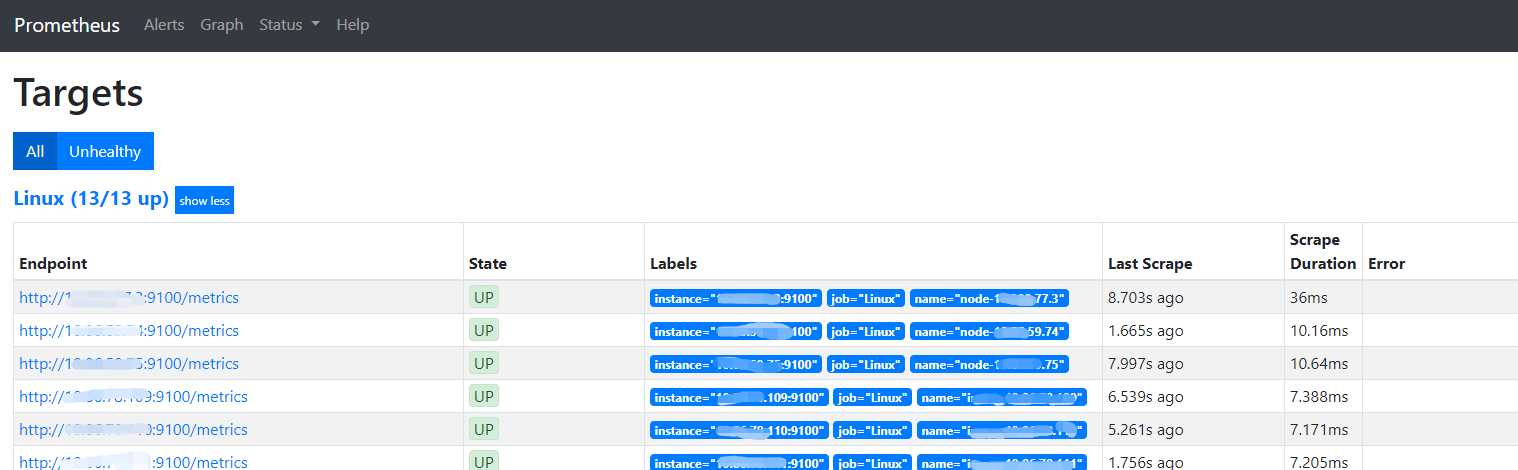
3 数据展示Grafana安装配置
下载地址: https://grafana.com/grafana/download
wget https://dl.grafana.com/oss/release/grafana-6.5.1-1.x86_64.rpm sudo yum localinstall grafana-6.5.1-1.x86_64.rpm
granafa默认端口为3000,可以在浏览器中输入http://localhost:3000/
granafa首次登录账户名和密码admin/admin,可以修改
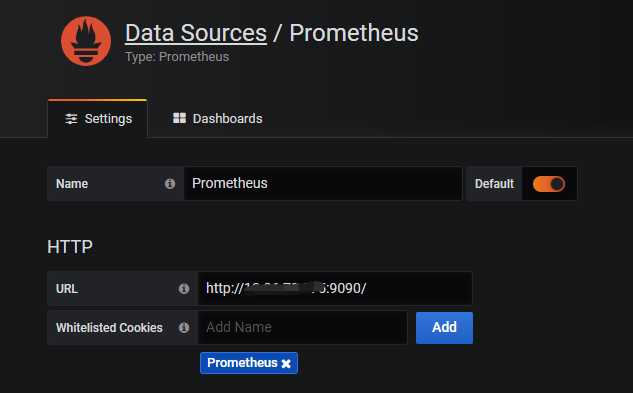
配置数据源Data sources->Add data source -> Prometheus,输入prometheus数据源的信息,主要是输入name和url
添加DashboardNew Dashboard->Import Dashboard->输入11074,配置数据源为Prometheus,即上一步中的name
配置完保存后即可看到逼格非常高的系统主机节点监控信息,包括CPU、IO、网络等信息。
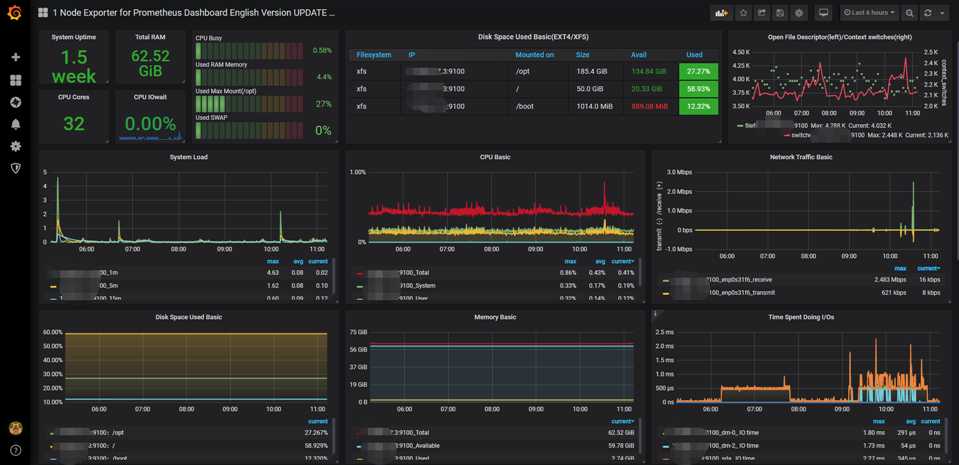
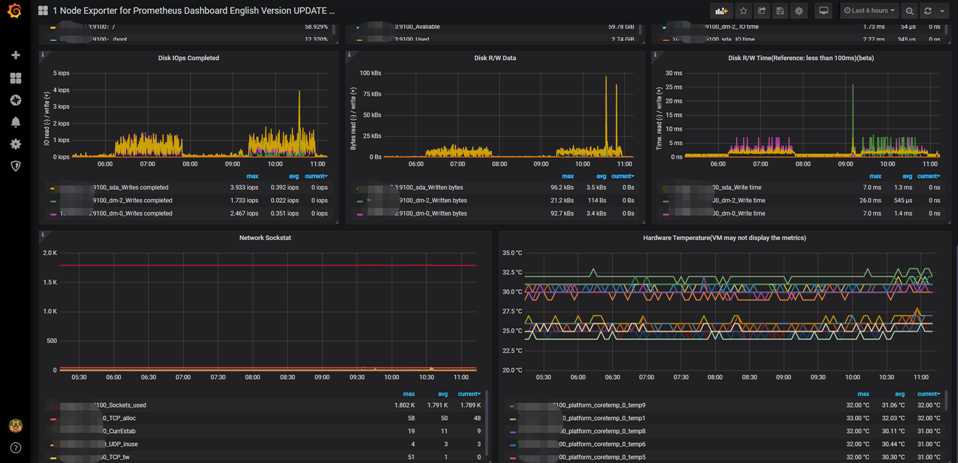
可以看到上述监控中包括了Linux服务器的一些常用参数, CPU, MEM, NETWORK, 连接数, 文件打开数, CPU温度等常用信息.
参考资料:
- 官网地址:https://prometheus.io/
- GitHub: https://github.com/prometheus
- 官方文档中文版: https://github.com/Alrights/prometheus
- 官方监控agent列表:https://prometheus.io/docs/instrumenting/exporters/
以上是关于Prometheus+Grafana监控的主要内容,如果未能解决你的问题,请参考以下文章