函数编程
Posted sxy-blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了函数编程相关的知识,希望对你有一定的参考价值。
上节补充:bytes类型
bytes类型是指一堆字节的集合,在python中以b开头的字符串都是bytes类型。
如:b‘xe5xb0x8fxe7x8cxbfxe5x9cx88‘ #b开头的都代表是bytes类型,是以16进制来显示的,2个16进制代表一个字节。 utf-8是3个字节代表一个中。以上正好是9个字节。
计算机只能存储二进制,数据、字符、图片等存在硬盘上也必须以正确的方式编码成为二进制才能存储。
在Python中,二进制不是0101010来表示,而是通过bytes类型来表示。
将数据转换成编码成为二进制可通过encode方法
s = "小猿圈" print(s.encode("utf8")) # 运行结果为b‘xe5xb0x8fxe7x8cxbfxe5x9cx88‘
经过编码之后数据就是bytes类型。
字符串必须转成字符串类型才能存在硬盘上,在之前的文件操作中,python自动做了这个事情,在python3中文件存储的默认编码是utf-8。
当然也可以自己指定编码方式。
f = open(‘filename.text‘,‘w‘,encoding = ‘utf-8‘)
f = open(‘filename.text‘,‘w‘,encoding = ‘gbk‘)
通过这种方式就可以指定编码的方式。
Windows的默认编码方式是gbk,Mac上的默认编码方式是utf-8。
当写入中文的时候,由于windows系统上的默认编码方式是gbk,所以在写文件时应该指定 encoding = ‘utf8‘。
如果你不想让open对象帮你自动编码,你可以直接存入bytes类型的数据。
f = open (‘filename.text‘,‘wb‘) s = “小猿圈”.encode("utf8") f.write(s) f.close()
二进制的打开模式有
rb 二进制读
wb 二进制创建
ab 二进制追加
字符编码的转换
字符编码的转换就是将一种编码方式转换成另一种编码方式,比如将gbk转换成utf-8。
由于windows上的默认编码是gbk,Mac上的默认编码方式是utf-8,windows上的文件发到mac上会导致乱码,一次需要一种方式将gbk的编码转换成utf-8的编码。
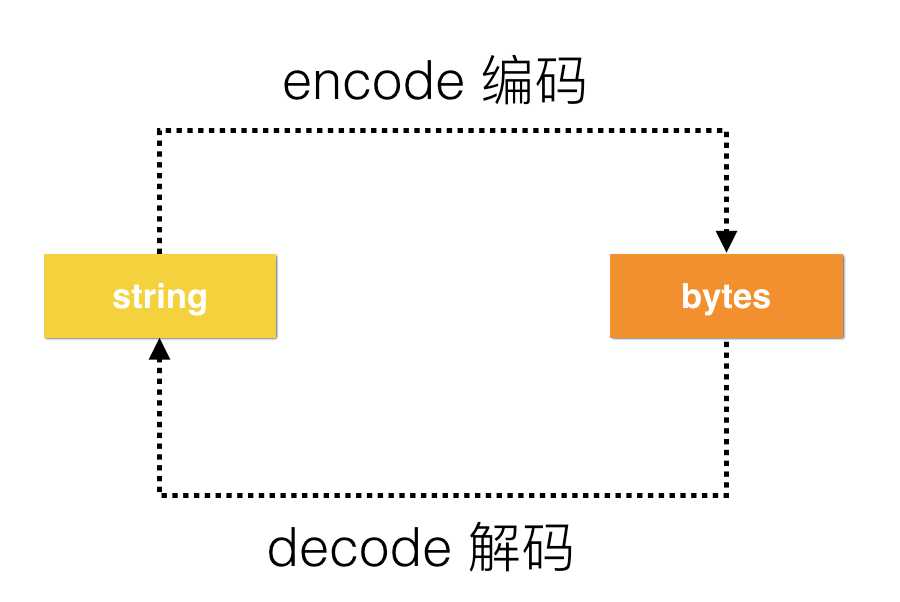
在python3中,内存里的字符串都是unicode编码,unicode又称万国码。
unicode有两个特点:
1.可以支持全球所有语言。
2.与全球所有的编码方式都有映射关系
因此,可以通过unicode这个桥梁实现编码的转换。

注意,不管在Windows or Mac or Linux上,你的pycharm IDE都可以支持各种文件编码,所以即使是utf-8的文件,在windows下的pycharm里也可以正常显示。
深浅copy
我们先看这样几行代码
a = 10 b = a a =9 print(a,b) # a为9 ,b为10
这种情况下,a,b是两个独立的变量,指向不同的内存地址。
data = { "name":"alex", "age":18, "scores":{ "语文":130, "数学":60, "英语":98, } } d2 = data data["age"] = 20 print(d2) # {‘name‘: ‘alex‘, ‘age‘: 20, ‘scores‘: {‘语文‘: 130, ‘数学‘: 60, ‘英语‘: 98}}
通过这段代码可以发现,data和d2都指向这个字典所在的内存地址,当data的数据改变时,d2的数据也改变了。
data和d2的数据并不是独立的,而是数据共享的,是什么原因呢?
字典、列表、集合,这三种可变数据类型本身相当于一个容器,容器本身有一个内存地址,里面的变量是相互独立的,有各自独立的内存地址。
上面的data、d2都是指向字典这个容器的内存地址,因此当内部的变量内存地址发生改变时,容器本身的内存地址并未发生改变。
因此data,d2仍指向同一个内存地址,因此数据是共享的。
那么,如何复制一份完整的dict数据呢?
可以用浅copy方法
data = { "name":"alex", "age":18, "scores":{ "语文":130, "数学":60, "英语":98, } } d2 = data.copy() data["age"] = 20 print(d2) # {‘name‘: ‘alex‘, ‘age‘: 18, ‘scores‘: {‘语文‘: 130, ‘数学‘: 60, ‘英语‘: 98}} print(data) #{‘name‘: ‘alex‘, ‘age‘: 20, ‘scores‘: {‘语文‘: 130, ‘数学‘: 60, ‘英语‘: # 98}}
这时候 data和d2就是两份独立的数据了,通过id(data) 和 id(d2) 可以看到这两个指向的字典容器的内存地址已经不同了。
但是为什么叫做浅copy呢?
这是因为浅copy方法只会赋值dict第一层的数据,更深层下面的数据仍然是共享的。
data = { "name":"alex", "age":18, "scores":{ "语文":130, "数学":60, "英语":98, } } d2 = data.copy() data["age"] = 20 data["scores"]["数学"] = 77 print(d2) #{‘name‘: ‘alex‘, ‘age‘: 18, ‘scores‘: {‘语文‘: 130, ‘数学‘: 77, ‘英语‘: 98}} print(data) #{‘name‘: ‘alex‘, ‘age‘: 20, ‘scores‘: {‘语文‘: 130, ‘数学‘: 77, ‘英语‘: # 98}}
通过上面可以看出,socres里面的数据是共享的

在为修改值之前,data,d2的内部变量的内存地址相同,但是只要稍作修改,数据的内存地址就会改变。但是scores内的数据改变时,内部变量的内存地址改变了,但是scores本身这个容器的内存地址没有改变,因此scores内部仍然是共享一份数据。
如果想所有层次的数据都完整复制一份,彻底让data和d2独立,就要用深copy方法。
import copy data = { "name":"alex", "age":18, "scores":{ "语文":130, "数学":60, "英语":98, } } d2 = copy.deepcopy(data) data["age"] = 20 data["scores"]["数学"] = 77 print(d2) #{‘name‘: ‘alex‘, ‘age‘: 18, ‘scores‘: {‘语文‘: 130, ‘数学‘: 60, ‘英语‘: 98}} print(data) #{‘name‘: ‘alex‘, ‘age‘: 20, ‘scores‘: {‘语文‘: 130, ‘数学‘: 77, ‘英语‘: # 98}}
深copy方法可以复制独立的list,dict,set。
函数
定义: 函数是指将一组语句的集合通过一个名字(函数名)封装起来,要想执行这个函数,只需调用其函数名即可。
特性:
-
减少重复代码
-
使程序变的可扩展
-
使程序变得易维护
函数语法:
def sayhi(): # 定义函数 print("hello world!") saihi() # 调用函数
函数也可以带参数
a = 10 b = 2 c = b**a print(c) # 通过函数可以这样写 def calc(x,y): res = x**y return res # 将计算结果返回 c = calc(a,b) # 结果用变量c接收 print(c)
函数可以让你代码的功能更加灵活,可以处理多个组的功能,很多重复的代码就可以写成一个函数,当调用时,只需要一句话即可,大大节省了代码量。
函数的参数
形参
只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量。
实参
可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先给实参赋值。
a = 10
b = 20
def calc(x,y): res = x**y return res # 将计算结果返回 c = calc(a,b) # 结果用变量c接收 print(c)
此函数中a,b就是实参,函数中的x,y就是形参。
默认参数
默认参数就是形参设置一个默认值,如果没有传入则用默认值,如果传入值,则用传入的值。
def info_2(name,age,sex,country="CN"): # 默认参数必须放在参数的最后面 否则可能发生一些错误 """ 个人信息 :param name: alex,eric.. :param age: inte :param sex: male female :param country: CN :return: None """ msg = """ --------------personal information--------------- name: %s age: %s sex: %s country: %s ------------------------------------------------- """ % (name, age, sex, country) print(msg)
info_2(‘alex‘, 22, ‘male‘)
# 运行结果:
--------------personal information---------------
name: alex
age: 22
sex: male
country: CN
-------------------------------------------------
上面调用函数时,函数只传入三个参数,但形参有四个值,当没有给country传实参时,country就用默认值;如果给country传了值,那么country就是传入的值。
上面在只传入三个参数时,country就用默认值country = ‘CN‘。
注意:形参中,默认参数一定要放在最后面,如果将默认参数放在前面,就会发生一些歧义,因为你不知道你传入的参数时给默认的参数,还是给另外的实参。
关键参数
正常情况下,给函数传参数要按顺序,不想按顺序就可以用关键参数,只需指定参数名即可(指定了参数名的参数就叫关键参数)。但是要注意,关键参数必须要放在位置参数之后。
位置参数就是形参和实参根据位置一 一对应传参。
def stu_register(name, age, course=‘PY‘ ,country=‘CN‘): print("----注册学生信息------") print("姓名:", name) print("age:", age) print("国籍:", country) print("课程:", course) stu_register(‘alex‘, 22 ,‘PY‘, ‘JP‘) #按位置传参数 stu_register("王山炮",course=‘PY‘, age=22,country=‘JP‘ ) #但是绝不能这样传入参数 stu_register("王山炮",course=‘PY‘,22,country=‘JP‘ ) stu_register("王山炮",22,age=25,country=‘JP‘ ) # 这样相当于给age赋值了两次
所以,传入参数时,优先级别:位置的参数>关键参数。
非固定参数
若函数在定义时不确定传入多少个参数时,可用非固定参数。
def stu_register(name,age,*args): # *args 会把多传入的参数变成一个元组形式 print(name,age,args) stu_register("Alex",22) # 输出为 Alex 22 stu_register("Jack",32,"CN","Python") # 结果为 Jack 32 (‘CN‘,‘Python‘) def stu_register(name,age,*args,**kwargs): # **kwargs 会把多传入的参数变成一个dict形式 print(name,age,args,kwargs) stu_register("Alex",22) #Alex 22 () {} # 后面这个{}就是kwargs,只是因为没传值,所以为空 stu_register("Jack",32,"CN","Python",sex="Male",province="ShanDong") # Jack 32 (‘CN‘, ‘Python‘) {‘province‘: ‘ShanDong‘, ‘sex‘: ‘Male‘}
*args 用于接收位置参数形成元组,**kwargs用于接收关键参数形成字典。
在函数中调用非固定参数时,不用加*。
函数的返回值和作用域
函数外部的代码想要获取函数执行的结果,可以用return函数。
def add(a,b): return a**b ret = add(2,10) # 用一个变量接收函数的返回值 print(ret) # 结果为1024
函数执行过程中,只要遇到return就结束,不执行后面的代码,也可以说return代表着函数的结束。
如果一个函数中没有return,或者没有执行return,返回值为None。
全局变量与局部变量
name = ‘Alex‘ def func(): name = ‘eric‘ def inner name = ‘mjj‘ print(name) # name = ‘mjj‘ print(name) # name = ‘eric‘ func() print(name) # name = ‘Alex‘
从上面函数的执行,我们可以发现,在函数中name变量的值已经被修改,但是在函数外打印name的值是,name仍为Alex。但是如果在同一级的函数,修改name,却可以得到修改的值。
在函数中定义的变量是局部变量,只在函数内部有效;
在函数外定义的变量成为全局变量,在整个程序中有效;
局部变量是不能修改全局变量的;
变量查找是按照就近原则,先找最靠近的,没有再查找远的。即先找局部再找全局。
当全局变量与局部变量同名时,在定义局部变量的函数内,局部变量起作用;在其它地方全局变量起作用。
如果想要再函数中修改全局变量,要用global
name = ‘Alex‘ def func(): glabal name # 声明name是一个全局变量 name = ‘mjj‘ print(name) # name=‘mjj‘ func() print(name) # name = ‘mjj‘
在函数中声明了name是一个全局变量,那么在函数外面不用写name = ‘Alex‘,仍然可以打印name。
给函数传递列表、字典、集合时的现象
d = {"name":"Alex","age":26,"hobbie":"大保健"}
l = ["Rebeeca","Katrina","Rachel"]
def change_data(info,girls):
info["hobbie"] = "学习"
girls.append("XiaoYun")
change_data(d,l)
print(d,l)
# d = {"name":"Alex","age":26,"hobbie":"学习"}
# l = ["Rebeeca","Katrina","Rachel","XiaoYun"]
通过这段代码可以看到,将字典、列表传入函数,函数却改变了外部字典列表的数据,局部变量修改了全局变量。但是在上面说到局部变量不能修改全局变量,所以为什么会这样?

列表、字典就相当于一个大容器,容器本身有一个内存地址,列表字典中的变量是容器中的物品,是相对独立的也有自己本身的内存地址。
上述代码是将列表、字典这个去容器的内存地址传递给了函数,不能改变,但是里面的变量是可以改变的。这和之前的深浅copy的原理相似。
列表、字典、集合这些可变数据类型传递给函数时,传递的都是容器本身的内存地址,其内部的元素是可以被函数改变的。
嵌套函数
name = ‘Alex‘ def func(): name = ‘eric‘ def inner name = ‘mjj‘ print(name) # name = ‘mjj‘ print(name) # name = ‘eric‘ func() print(name) # name = ‘Alex‘
仍然是这段代码,在函数中间又定义了另一个函数,就是嵌套函数。
从name变量的值,可以看出每个函数的变量是相互独立的,变量的查找顺序是从内向外的。
匿名函数
匿名函数就是不需要显示地指定函数名。
#普通函数 def calc(x,y): return x**y print(calc(2,5)) #匿名函数 calc = lambda x,y:x**y print(calc(2,5)) # 结果为32
lambda的用法是 x,y为传递的变量相当于函数的形参,:右边是表达式就是函数体,调用时仍然是通过变量名来传递参数。
匿名函数一般是结合使用的比如
res = map([lambda x: x*x, [1,3,4,5,6]) for i in res: print(i) # 1 9 16 25 36
map函数之后会将,通过匿名函数可以只用一行代码对列表进行操作,节省的代码量。
高阶函数
如果一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
def get_abs(n): if n < 0 : n = int(str(n).strip("-")) return n def add(x,y,f): return f(x) + f(y) res = add(3,-6,get_abs) print(res)
上面的代码把get_abs的函数名传递给add函数,那么在执行add函数时,实际上执行的就是get_abs(x)+get_abs(y)。
只需满足以下任意一个条件,即是高阶函数:
接受一个或多个函数作为输入
return 返回另外一个函数
函数的递归
在函数内部,可以调用其他函数。如果一个函数在内部调用自已本身,这个函数就叫做递归函数。
def calc(n): n = int(n/2) print(n) if n > 0: calc(n) #调用自己 print(n) calc(10)
上述函数的功能是对大于0的输入/2取整,但执行结果是 5 2 1 0 0 1 2 5。
这是为什么呢?我们来看一下递归函数的执行过程
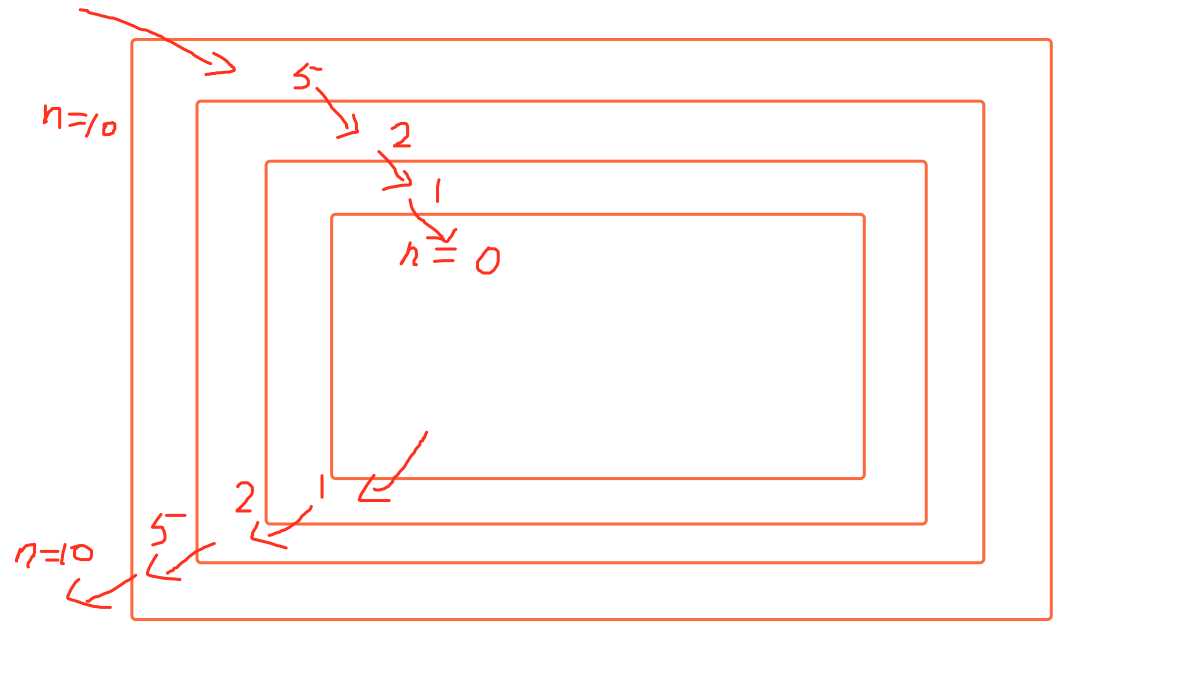
每一次判断n>0后就会进入下一层函数,当不满足n>0的条件时,才会执行下面的print(n),这就导致了如上结果。
递归特性:
-
必须有一个明确的结束条件
-
每次进入更深一层递归时,问题规模相比上次递归都应有所减少
-
递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
内置函数

内置参数详解https://docs.python.org/3/library/functions.html?highlight=built#ascii
函数作用解析
abs() # 求绝对值 all() # 全部为布尔值非False的值时 返回True 否则返回False any() # 只要有一个布尔值不为0的数据 返回True 否则 返回false ascii() # 返回一个表示对象的字符串, 如果内容为非ASCII值 则返回对应 # unicode编码的字符 bin() # 返回十进制数对应的二进制数 bool() # 判断一个数据结构是True or False 。注:空字典、空列表、None 布尔值为False bytearray ()# 把byte变成 bytearray, 可修改的数组。 s = ‘小猿圈‘ print(s[0], s[2]) # 字符串实际上是字符的集合 可以做切片操作 但是不能修改 s_code = s.encode("utf8") print(s_code) print(s_code[0], s_code[1]) # 字节类型也可以作切片操作 出来的值是16进制数对应的十进制数 但是也不能够修改 s_new_code = bytearray(s_code) print(s_code) print(s_new_code) s_new_code[3] = 229 # 给出十进制即可 会自动转成对应的16进制 print(s_new_code) print(s_new_code.decode("utf8")) # 可以发现字符串变了 # 综上可得,bytearray()方法可以将字节类型变成一个列表,进而对字节进行修改,修改#了原字符串的内存地址 bytes ()# bytes(“中国”,”gbk”) 将字符串按照指定编码方式转成bytes类型 callable() # 判断一个对象是否可调用 chr() # 返回一个数字对应的ascii字符 , 比如chr(90)返回ascii里的’Z’ ord () # 返回ascii的字符对应的10进制数 ord(‘a’) 返回97 hex() #返回一个10进制的16进制表示形式,hex(10) 返回’0xa’ oct # 返回10进制数的8进制表示 compile #py解释器自己用的东西,忽略 complex #求复数 dict ()#生成一个空dict dir() #返回对象的可调用属性 divmod() #返回除法的商和余数 ,比如divmod(4,2),结果(2, 0) enumerate #返回列表的索引和元素,一般在for循环中使用 a = [‘alex‘, ‘eric‘, ‘mjj‘] for i,v in enumerate(a); print(i,v) # 0 ‘alex‘ # 1 ‘erix‘ # 2 ‘mjj‘ eval() #可以把字符串形式的list,dict,set,tuple,再转换成其原有的数据类型。 exec ()#把字符串格式的代码,进行解义并执行 #比如exec(“print(‘hellworld’)”),会解义里面的字符串,打印hello world exit() #退出程序 filter # 对list、dict、set、tuple等可迭代对象进行过滤, # filter(lambda x:x>10,[0,1,23,3,4,4,5,6,67,7])过滤出所有大于10的值 float() #转成浮点 frozenset ()#把一个集合变成不可修改的集合 globals() #打印全局作用域里的值 locals() #打印局部变量作用域的值 hash() #hash函数,生成hash值 id() #查看对象内存地址 isinstance # 判断一个数据结构的类型,比如判断a是不是fronzenset, # isinstance(a,frozenset) 返回 True or False iter() #把一个数据结构变成迭代器,讲了迭代器就明白了 map # map(lambda x:x**2,[1,2,3,43,45,5,6,]) 输出 [1, 4, 9, 1849, 2025, 25, 36] max ()# 求最大值 memoryview # 一般人不用,忽略 min # 求最小值 next # 生成器会用到,现在忽略 repr #没什么用 reversed # 可以把一个列表反转 round #可以把小数4舍5入成整数 ,round(10.15,1) 得10.2 sorted sum #求和,a=[1, 4, 9, 1849, 2025, 25, 36],sum(a) 得3949 zip # 可以把2个或多个列表拼成一个,将每一个列表的元素一一对应组合起来 长度以最短的为准 li_1 = [1, 2, 3, 4, 5, 6] li_2 = [‘alex‘, ‘mjj‘, ‘wupeiqi‘] ret_2 = zip(li_1, li_2) print(list(ret_2)) # [(1, ‘alex‘), (2, ‘mjj‘), (3, ‘wupeiqi‘)
名称空间
一个变量如x=1,1存放在内存中,那么x放在什么地方。
名称空间就是存放变量与值绑定关系的地方。
python中有很多名称空间,每个空间互不干扰,相同的变量名处于不同的名称空间,这两个变量也是没有关系的。
python的名称空间有四种:LEGB
locals:函数内部的名字空间,一般包括函数的局部变量以及形式参数。
enclosing function:在嵌套函数中外部函数的名字空间, 若fun2嵌套在fun1里,对fun2来说,fun1的名称空间就enclosing.
globals:当前的模块空间,模块就是一些py文件。也就是说,globals()类似全局变量。
builtins: 内置模块空间,也就是内置变量或者内置函数的名字空间。
不同变量的作用域不同就是由变量所处的名称空间决定的。
作用域即范围
-
全局范围:全局存活,全局有效
-
局部范围:临时存活,局部有效
查看作用域方法 globals(),locals()
作用域查找顺序
当程序引用某个变量的名字时,就会从当前名字空间开始搜索。
搜索顺序规则便是:LEGB。即locals -> enclosing function -> globals ->builtins。
一层一层的查找,找到了之后,便停止搜索,如果最后没有找到,则抛出在NameError的异常。
level = ‘L0‘ n = 22 def func(): level = ‘L1‘ n = 33 print(locals()) # {‘level‘: ‘L1‘, ‘n‘: 33} def outer(): n = 44 level = ‘L2‘ print("outer:", locals(), n) # outer: {‘level‘: ‘L2‘, ‘n‘: 44} 44 def inner(): level = ‘L3‘ print("inner:", locals(), n) # inner: {‘level‘: ‘L3‘, ‘n‘: 44} 44 inner() outer() func()
每一层名称空间的局部变量都不相同,变量从内向外查找。
闭包
def outer(): name = ‘alex‘ def inner(): print("在inner里打印外层函数的变量",name) return inner # 注意这里只是返回inner的内存地址,并未执行 f = outer() # 返回的是inner函数的内存地址 .inner at 0x1027621e0> f() # 相当于执行的是inner()
正常情况下,outer()函数执行完毕内存就已经释放了,但是还可以调用outer()内部的inner函数,并且仍然可以调用outer函数的name,这就是由于闭包的存在。
闭包的意义:返回的函数对象,不仅仅是一个函数对象,在该函数外还包裹了一层作用域,这使得,该函数无论在何处调用,优先使用自己外层包裹的作用域。
装饰器
def home(): print("---首页----") def america(): print("----欧美专区----") def japan(): print("----日韩专区----") def henan(): print("----河南专区----")
假设这是一个网站的各个专区的页面,调用函数即为打开页面,现在要添加一个用户认证的功能
account = { "is_authenticated":False,# 用户登录了就把这个改成True "username":"alex", # 假装这是DB里存的用户信息 "password":"abc123" # 假装这是DB里存的用户信息 } def login(): if account["is_authenticated"] is False: username = input("user:") password = input("pasword:") if username == account["username"] and password == account["password"]: print("welcome login....") account["is_authenticated"] = True else: print("wrong username or password!") else: print("用户已登录,验证通过...") def home(): print("---首页----") def america(): login() # 执行前加上验证 print("----欧美专区----") def japan(): print("----日韩专区----") def henan(): login() # 执行前加上验证 print("----河南专区----") home() america() henan()
你可以加一个关于用户认证的函数,然后在每一个页面打开前都调用这个函数。
但是这样虽然程序的功能实现了,但是违反了“开放-封闭”原则。
-
封闭:已实现的功能代码块不应该被修改
-
开放:对现有功能的扩展开放
这样修改代码相当于是对已有的功能的代码块进行了修改,是不符合开放封闭原则的,所以要找一种不修改原来代码的方式来增加这个功能。
account = { "is_authenticated":False,# 用户登录了就把这个改成True "username":"alex", # 假装这是DB里存的用户信息 "password":"abc123" # 假装这是DB里存的用户信息 } def login(func): if account["is_authenticated"] is False: username = input("user:") password = input("pasword:") if username == account["username"] and password == account["password"]: print("welcome login....") account["is_authenticated"] = True else: print("wrong username or password!") if account["is_authenticated"] is True: # 主要改了这 func() # 认证成功了就执行传入进来的函数
def home(): print("---首页----") def america(): print("----欧美专区----") def japan(): print("----日韩专区----") def henan(): print("----河南专区----")
home() login(america) # 需要验证就调用 login,把需要验证的功能 当做一个参数传给login login(henan)
通过之前学过的高阶函数,在不修改源代码的情况下,实现了认证功能的添加,但是这种方式仍然不好,因为修改了原来程序的调用方式,修改以后,所有的用户都要修改调用方式,显然是不合理的。
那么如何在不修改源代码和原来调用方式的情况下给函数添加功能?
account = { "is_authenticated":False,# 用户登录了就把这个改成True "username":"alex", # 假装这是DB里存的用户信息 "password":"abc123" # 假装这是DB里存的用户信息 } def login(func): def inner(): # 再定义一层函数 if account["is_authenticated"] is False: username = input("user:") password = input("pasword:") if username == account["username"] and password == account["password"]: print("welcome login....") account["is_authenticated"] = True else: print("wrong username or password!") if account["is_authenticated"] is True: func() return inner # 注意这里只返回inner的内存地址,不执行
america() # 相当于执行inner() henan()
上面的代码将原函数名america传给login()函数,login()函又定义了一层函数inner,并且返回了内部函数的函数名inner,然后用america进行函数名的替换,这样再次执行america()时,相当于执行的就是
inner()函数。这样就实现了在没有修改源代码和调用方式的情况下给原函数增加功能的目的。
def america(): print("----欧美专区----") def henan(): print("----河南专区----") home() america = login(america) henan = login(henan) # 通常装饰器使用这种写法 @login # 相当于america = login(america) def america(): print("----欧美专区----") @login # 相当于henan = login(henan) def henan(): print("----河南专区----")
当需要给原函数传递参数时,可以使用非固定参数,即给innder(*args,**kwargs),然后给func(*args,**kwargs) 就可以实现了。
当有多个装饰器时,从上到下,按顺序执行。
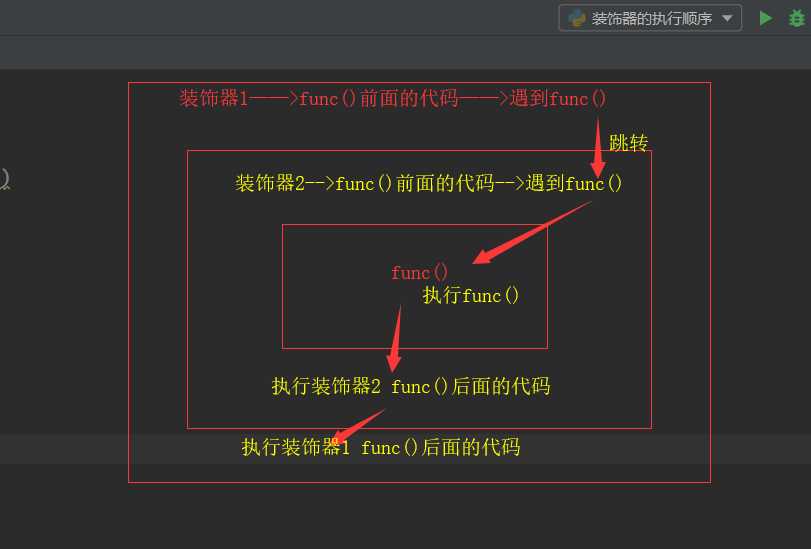
执行顺序如上。
列表生成式
现在有个需求,现有列表a=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9],要求你把列表里的每个值加1。
二逼青年版:生成一个新列表b,遍历列表a,把每个值加1后存在b里,最后再把a=b, 这样二逼的原因不言而喻,生成了新列表,浪费了内存空间。
普通青年版:for循环遍历。
略屌青年版:a = map(lambda x:x+1,a)。
装逼青年版:a = [x+1 for x in rang(10)]。
[x+1 for x in rang(10)]这种形式是列表生成式,左边为表达式,右边为循环。
生成器
在Python中,一边循环一边计算后面元素的机制,称为生成器:generator。
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:
>>> [x * x for x in range(10)] [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] >>> >>> (x * x for x in range(10)) at 0x101ebc3b8>
(x*x for x in range(10))生成的就是一个生成器。
我们可以直接打印出list的每一个元素,但我们怎么打印出generator的每一个元素呢?
如果要一个一个打印出来,可以通过next()函数获得generator的下一个返回值:
>>> g = (x * x for x in range(10)) >>> next(g) 0 >>> next(g) 1 >>> next(g) 4 >>> next(g) 9 >>> next(g) 16
我们讲过,generator保存的是算法,每次调用next(g)就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。
当然,上面这种不断调用next(g)实在是太变态了,正确的方法是使用for循环,因为generator也是可迭代(遍历)对象:
>>> g = (x * x for x in range(10)) >>> for n in g: ... print(n) ... 0 1 4 9
函数生成器
generator非常强大。如果推算的算法比较复杂,用类似列表生成式的for循环无法实现的时候,还可以用函数来实现。
比如,著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到:
1, 1, 2, 3, 5, 8, 13, 21, 34, …
实现100以内的斐波那契数代码:
def fib(max): a,b = 0,1 n = 0 # 斐波那契数 while n < max: n = a + b a = b # 把b的旧值给到a b = n # 新的b = a + b(旧b的值) print(n) fib(100)
仔细观察,可以看出,fib函数实际上是定义了斐波拉契数列的推算规则,可以从第一个元素开始,推算出后续任意的元素,这种逻辑其实非常类似generator。
也就是说,上面的函数和generator仅一步之遥。要把fib函数变成generator,只需要把print(b)改为yield b就可以了:
def fib(max): a,b = 0,1 n = 0 # 斐波那契数 while n < max: n = a + b a = b # 把b的旧值给到a b = n # 新的b = a + b(旧b的值) #print(n) yield n # 程序走到这,就会暂停下来,返回n到函数外面,直到被next方法调用时唤醒 f = fib(100) # 注意这句调用时,函数并不会执行,只有下一次调用next时,函数才会真正执行 print(f) print(f.__next__()) print(f.__next__()) print(f.__next__()) print(f.__next__())
这就是定义generator的另一种方法。如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator:
这里,最难理解的就是generator和函数的执行流程不一样。函数是顺序执行,遇到return语句或者最后一行函数语句就返回。
而变成generator的函数,在每次调用next()的时候执行,遇到yield语句暂停并返回数据到函数外,中间可以去做别的事情 再次被next()调用时从上次返回的yield语句处继续执行,可以实现中断的效果。
我们基本上从来不会用next()来获取下一个返回值,而是直接使用for循环来迭代:
f = fib(100) # 注意这句调用时,函数并不会执行,只有下一次调用next时,函数才会真正执行 for i in f: print(i) #输出: 1 2 3 ... ... 55 89 144
生成器不仅可以返回值,也可以通过send接收值。
def func1(): while True: name = ‘alex‘ yield name def func2(): while True: name = yield print(name) # hello alex c1 = func1() c2 = func2() ret1 = c1.__next__() c2.__next__() c2.send(‘hello alex‘) # alex print(ret1)
注意:刚开启的生成器不能直接接收值,应该先用__next__方法使函数执行到yield,再send值。
利用生成器中断的特性可以来模拟并发效果
import time def consumer(name): print("%s 准备吃包子啦!" %name) while True: baozi = yield # yield可以接收到外部send传过来的数据并赋值给baozi print("包子[%s]来了,被[%s]吃了!" %(baozi,name)) c = consumer(‘A‘) c2 = consumer(‘B‘) c.__next__() # 执行一下next可以使上面的函数走到yield那句。 这样后面的send语法才能生效 c2.__next__() print("----老子开始准备做包子啦!----") for i in range(10): time.sleep(1) print("做了2个包子!") c.send(i) # send的作用=next, 同时还把数据传给了上面函数里的yield c2.send(i)
注意:调用send(x)给生成器传值时,必须确保生成器已经执行过一次next()调用, 这样会让程序走到yield位置等待外部第2次调用。
迭代器
我们已经知道,可以直接作用于for循环的数据类型有以下几种:
-
一类是集合数据类型,如
list、tuple、dict、set、str等; -
一类是
generator,包括生成器和带yield的generator function。
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable,可迭代的意思就是可遍历、可循环。
而生成器不但可以作用于for循环,还可以被next()函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了。
*可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
可以使用isinstance()判断一个对象是否是Iterator对象:
>>> from collections.abc import Iterable >>> isinstance([], Iterable) True >>> isinstance({}, Iterable) True >>> isinstance(‘abc‘, Iterable) True >>> isinstance((x for x in range(10)), Iterable) True >>> isinstance(100, Iterable) False >>> from collections.abc import Iterator >>> isinstance([], Iterator) False >>> isinstance({}, Iterator) False >>> isinstance(‘abc‘, Iterator) False >>> isinstance((x for x in range(10)), Iterator) True >>> isinstance(100, Iterator) False
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数:
>>> isinstance(iter([]), Iterator) True >>> isinstance(iter(‘abc‘), Iterator) True
你可能会问,为什么list、dict、str等数据类型不是Iterator?
这是因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
小结
凡是可作用于for循环的对象都是Iterable类型;
凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
以上是关于函数编程的主要内容,如果未能解决你的问题,请参考以下文章